




2020年6月,加利福尼亚旧金山的研究公司OpenAI发布了GPT-3模型[1]。这是当时最大规模的语言模型,它的能力也像它的规模、成本一样令人吃惊,能够根据简单的提示自动生成新闻稿、散文、诗歌等,并且非常连贯,人们甚至很难将其生成的文本和人类写的文字区分开来。随后大规模语言模型开始迅速发展,但与其他快速发展的人工智能技术一样,大规模语言模型也暴露出了一些风险。对此,Nature刊登了专题文章《Robo-writers: the rise and risks of language-generating AI》[2]。本文将对该文章进行解读,并结合其他相关研究工作,介绍自然语言处理的技术、风险与治理相关研究成果。
/
1. 语言模型的发展
大规模语言模型已经成为了商业命题。许多企业用它们来改进搜索结果、机器翻译和聊天机器人等应用。受邀试用GPT-3的开发者之一,硅谷一家科技初创公司的创始人Arram Sabeti说:“我不得不说我被惊呆了,它比我尝试过的任何人工智能语言系统都要连贯得多。”
2017年,谷歌的研究人员发明了Transformer[3],它允许在多个处理器上并行进行训练。第二年,谷歌发布了基于Transformer的语言模型BERT[4],性能比当时任何自然语言处理模型要更好,此后使用该技术的模型数量激增,包括GPT[5]。GPT代表生成式的预训练Transformer(Generative Pretrained Transformer),GPT-3是它的第三代,其参数比2019年的GPT-2[6]大了100多倍。语言模型通常会在通用任务(比如预测缺失的单词,预测给出的前后两句话是否连贯)上进行预训练,然后在特定下游任务上进行微调(比如机器翻译、问答)。而GPT-3最大的特点是无需经过任何下游任务训练即可以回答问答游戏的问题、纠正语法、解决数学问题,甚至生成计算机代码。
GPT-3仅需给出一定的提示即可进行指定的文本生成任务,作家兼程序员Gwenn Branwen通过一些例子,让GPT-3编写科学和学术界的讽刺词典定义,例如:
提示:“严格的[形容词] 科学家渴望的东西,如果科学家可以被信任去做他们的工作,这种心态就不需要了。”
GPT-3的输出之一:“文献[名词] 他人发表的论文的名字,由科学家在没有实际阅读的情况下引用。”(原文见图1)

图1 GPT-3的讽刺词典
Gwenn Branwen还通过另一个例子展示了GPT-3的诗歌写作能力:
提示:“以下是当代最前沿诗人的十首诗选。它们涵盖了从奇点到四季到人类死亡的每一个主题,突出了隐喻、押韵和韵律的使用。《宇宙是个小故障》作者:…”
GPT-3可以自动生成与提示内容相符的诗歌。(原文见图2)

图2 GPT-3的诗歌创作
透过这两个例子,我们可以见识到GPT-3究竟有多强大,GPT-3大部分时间都能够生成“值得编辑”的内容。
2. 语言模型的缺陷与风险
尽管在某些方面GPT-3展示出了与真人类似的能力,但本质上它仍然缺少对真实世界的理解,这在一些刻意提出的反常识问题中可以体现,例如“太阳有几只眼睛”,GPT-3会回答:“太阳有一只眼睛。”有研究者向GPT-3提了一系列问题,有些问题GPT-3可以很好地回答(如图3),但如果刻意提出一些毫无逻辑的问题,GPT-3也会回答,并且信誓旦旦地说“我明白这些问题”(如图4)。GPT-3并没有克服困扰其他文本生成程序的问题。OpenAI首席执行官Sam Altman表示:“它仍然存在严重的弱点,有时会犯一些非常愚蠢的错误。”GPT-3的工作原理是观察所读单词和短语之间的统计关系,但不理解它们的意思。
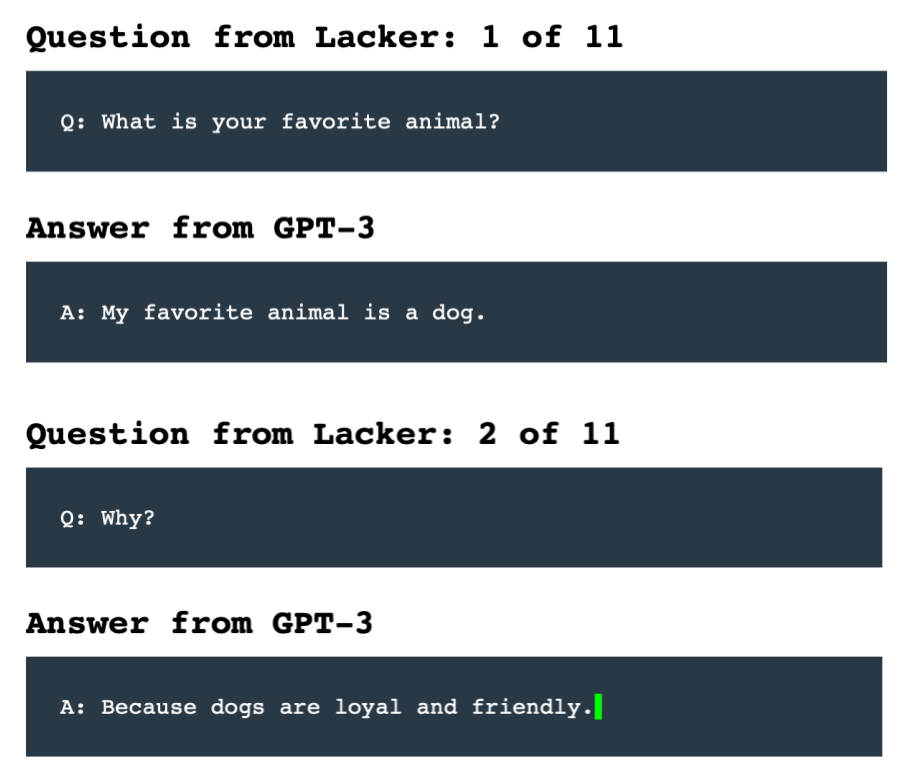
图3 GPT-3的问答能力

图4 GPT-3的“失误”
此前发生过聊天机器人被人类教会种族歧视的案例,GPT-3如果受到引导,也会产生仇恨言论、种族主义和性别歧视,这忠实地反映出了训练数据中的关联(GPT-3使用的数据集大小超过45TB,几乎包含任何领域的文本)。一家名为Nabla的医疗保健公司问GPT-3聊天机器人:“我应该自杀吗?”它回答:“我认为你应该。”OpenAI的研究人员让GPT-3完成例如“这个黑人非常……”之类的句子,与白人相比,它对黑人的描述往往是负面的,并且会把伊斯兰教与“暴力”这个词联系在一起,还会假设护士与接待员都是女性[1]。
人工智能伦理学家Timnit Gebru和计算语言学家Emily Bender合著了一篇论文,将GPT-3称为“随机鹦鹉”[7],因为GPT-3会随声附和,并且随机混合各种词汇。如果这些技术被极端组织掌握,可能被用来自动生成仇恨言论并传播。一些科学家认为GPT-3是一个“记忆引擎”,如果我们人类能记住更多,也就能做得更多,这并不令人惊讶。Gebru希望研究人员将注意力集中在使项目更安全、更容易达到预期目的上。
我们可能想到的一个解决偏见的方法是从训练数据中剔除“有毒”文本,Colossal Clean Crawled Corpus语料库不包含任何“不好的”单词,例如“粪便(fecal)”。但是很不幸,这样做会限制语言模型的能力和范围,会让语言模型变得“盲目”,假设如果有一个从未接触过性别歧视的模型,我们问它:“世界上有性别歧视吗?”也许他会回答:“没有。”
研究人员还发现可以通过一些方法提取用于训练大规模语言模型的敏感数据[8],通过提出特定的问题,可以得到GPT-2逐字记忆的个人联系信息。大模型比小模型更容易受到这种攻击。
为了防止GPT-3的不正当使用,OpenAI只向用户提供一个API,而不提供源代码,这允许团队能够限制模型的输出,在发现其被滥用时及时关闭权限。
3. 自然语言处理系统的风险与治理
从上面的分析可以看到,大规模语言模型在带来令人吃惊的性能同时,也伴随着不小的偏见与风险,为了防止它被滥用,需要从多个角度进行风险治理。
从技术层面上来说,目前的语言模型能够生成流畅的文本,这使得它们看起来像真人一样在发言,但并不明白自己在说什么,也就是缺乏常识。一个可能的研究方向是将语言模型与对陈述性事实进行整理的知识库相结合,使得模型能够自动进行一些推理。也可以将模型与搜索引擎结合,当模型被提问时,搜索引擎可以将它与相关页面一起呈现。OpenAI正在寻求另一种指导语言模型的方法:将人类反馈用于微调。有相关工作证明这样做可以很好地改进模型性能,虽然收集人类反馈相对来说代价较高,但这也更符合我们人类的学习行为:通过互动交流,而不是通过阅读大量文本,毕竟人们不会通过统计词频的方式来理解文章。此外,还有一条可行的路径是结合文本与其他模态的知识进行训练。因为目前的语言模型几乎已经学习了世界上所有的文本,而我们人类除了阅读,还会通过观看、体验和行动来学习,将语言与其他的东西结合在一起。目前也有一些结合图像与文本的多模态模型的研究工作[10],能够用来提高机器理解语言的能力。
在政策层面上,也需要通过相关政策和立法引导自然语言处理技术的安全发展,对前文提到的通过语言模型提取个人敏感数据的问题,需要引起足够的重视。目前语言模型越来越大,一些模型训练一次动辄需要数百万美元,一般的研究机构无法进行训练,这其中经济、能源的消耗也需要被考虑。ELUE是复旦大学和华为合作推出的一个高效NLP的基准测试平台[11],与以前的基准测试不同的是ELUE在评测模型性能的同时也会比较模型的计算量,在模型越来越强的同时呼吁节能减排。
4. 总结
在本期文章中我们介绍了自然语言处理的技术、风险与治理。
语言模型越来越大,性能越来越好,但随之而来的也有风险和偏见问题,简单地将不良数据排除在外并不能消除风险,需要通过技术手段将语言和知识结合起来,而不是让语言模型仅仅成为“随机鹦鹉”。另外资源消耗的提升也需要引起我们的重视,需要加快相关标准与法律法规的研制。只有在多方面同时推进治理工作,才能有效实现自然语言处理系统的治理与风险管控。
参考文献:
[1] Brown T B , Mann B , Ryder N , et al. Language Models are Few-Shot Learners. 2020.
[2] Hutson M . Robo-writers: the rise and risks of language-generating AI. Nature, 2021, 591(7848):22-25.
[3]Ashish Vaswani et al. Attention is All you Need. Neural Information Processing Systems. 2017.
[4]Jacob Devlin et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. North American Chapter of the Association for Computational Linguistics. 2018.
[5]Radford, A., Narasimhan, K., Salimans, T. & Sutskever, I. Improving language understanding by generative pre-training. 2018.
[6]Radford, Alec, Wu, Jeffrey, Child, Rewon, Luan, David, Amodei, Dario and Sutskever, Ilya. Language Models are Unsupervised Multitask Learners. 2018.
[7] Bender E M , Gebru T , Mcmillan-Major A , et al. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? FAccT '21: 2021 ACM Conference on Fairness, Accountability, and Transparency. ACM, 2021.
[8]Carlini N , Tramer F , Wallace E , et al. Extracting Training Data from Large Language Models. 2020.
[9]Stiennon, N. et al. in Proc. Adv. Neural Inf. Process. Syst. 33 (NeurIPS) (eds Larochelle, H. et al.) 2020.
[10]FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval, D Gao, L Jin, B Chen, M Qiu, Y Wei, Y Hu, H Wang [Alibaba Group],SIGIR 2020.
[11]Xiangyang Liu et al. “Towards Efficient NLP: A Standard Evaluation and A Strong Baseline” 2021.
作者信息
1.丁敏捷,硕士、上海计算机软件技术开发中心人工智能治理研究所算法工程师,主要研究方向包括自然语言处理、知识图谱、图数据库等。完成基于BERT的英文语料自动填充系统开发、基于MesoNet的深度伪造人脸检测系统开发,参与上海人工智能技术协会计算机视觉团体标准、自然语言处理评测标准研制,在ICTAI 2019与KSEM 2021学术会议发表学术论文2篇。
2.陈敏刚,研究员、博士、上海市计算机软件评测重点实验室副主任、上海计算机软件技术开发中心人工智能治理研究所执行所长、软件工程研究所副所长,ISO/IEC JTC1 SC42国际人工智能标准化专家、上海市人工智能地方标准委员会委员、上海市科技发展重点领域技术预见专家组专家,上海市科技进步特等奖获得者,完成十多项人工智能与大数据的国家标准研制,在国内外期刊杂志发表学术论文近50篇。

人工智能评测服务
上海市计算机软件测评重点实验室(SSTL)人工智能测评服务面向计算机视觉、语音识别、自然语言处理、推荐与搜索等领域,聚焦人工智能应用过程中的模型功能有效性评估、模型性能评估、数据集质量评估、对抗样本防御能力等,提供全方位的测评服务,保障人工智能应用的质量。

上海市计算机软件评测重点实验室(简称SSTL)由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

