




引言
上一篇文章我们对生成对抗网络(GAN)技术的一些进展及应用做了简要的介绍,相对于GAN技术本身快速发展与演进,针对GAN定量评估指标的研究相对较少。本篇文章我们主要从原理着手,介绍四种较为常见且应用广泛的GAN定量评估指标。
什么是GAN
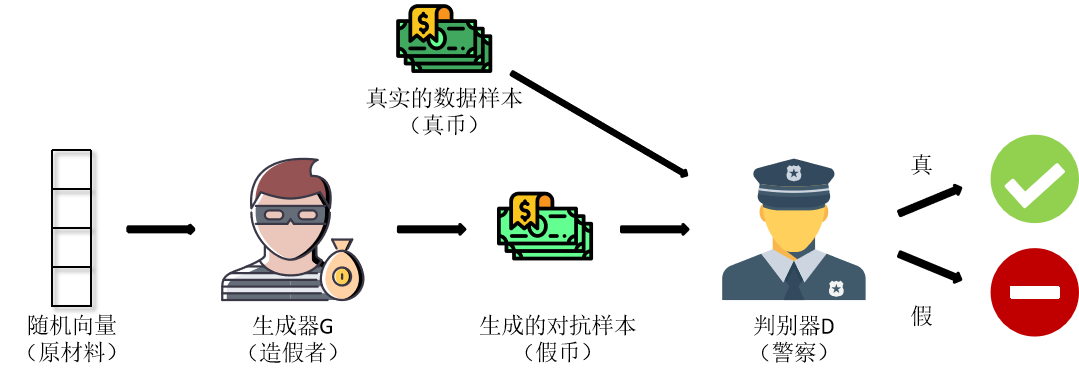
我们再来“复习”一下什么是GAN。GAN包含一个生成器G和一个判别器D,把生成器G看作造假者,把判别器D看作警察,造假者(生成器G)会不断生成假币(生成样本),而警察(判别器D)会判断接收到的样本是真还是假,在这个对抗过程中,生成器G的造假能力和判别器D的判断能力会不断增强。GAN的最终目的就是要通过生成器G和判别器D不断地零和博弈,使得生成器G生成以假乱真的样本。
定量评估指标要点
评价一个生成器G的优劣,我们大体需要从两个方面进行考虑。一方面是生成图像的质量,不够清晰与足够清晰但是看上去“很奇怪”的图片均算作低质量的图像;另一方面是生成图像的多样性,也就是生成图像的种类和真实图像相比够不够丰富。对于量化指标的介绍不可避免的会涉及到一些数学公式,不过笔者对于公式的含义做了直观解释,如果读者对于公式本身难以理解,可忽略公式了解其思想即可。
IS(Inception Score)
IS(Inception Score)会将生成的图像x输入分类器Inception V3,输出一个1000维的向量y,每个维度对应着图像属于某个类的概率。对于一个质量很好的生成图像来说,它应该会大概率属于某个类,也就是说,条件标签分布 p ( y | x ) 形如[0.9, 0.01, ..., 0.02, 0]。对于生成图像的多样性,若GAN生成一批图像,那么最理想的情况是,这一批图像的类别分布是均匀的(前提是训练数据集的类别分布是均匀的),用公式来说的话就是这批图像的经验分布p^(y)=1/N(∑Ni=1p ( y| x( i ) ))是均匀分布的。结合这两方面,对于一批生成图像,Inception Score的公式可以写作:
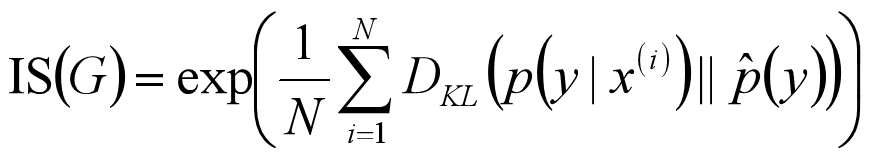
其中exp只是为了计算方便,没有具体意义,而KL散度DKL用来衡量两个分布的相似程度,值越大,说明这两个分布越不像。条件标签分布p ( y | x( i ) )是一个很尖锐的分布,而经验分布p^(y)是一个均匀分布,当这两个分布的差异越大,说明条件标签分布p ( y | x( i ) ) 趋于尖锐,而经验分布p^(y)趋于均匀。也就是说IS值越大,那么生成图像质量越好。

IS是最早被用于评价GAN的定量指标了,自2016年被提出以来,逐渐成为了应用最为广泛的指标之一。不过,IS存在的一些问题和缺陷也无法被忽略。首先,IS对网络内部权重非常敏感,尽管基于不同框架训练的网络拥有极为接近的分类精度,但由于内部权重的细微差异,导致了IS值有很大的变化。其次,分类器Inception V3是在ImageNet数据集上训练的,也就是说,只要GAN生成的图像不是ImageNet中存在的类,那么IS的意义就要大打折扣。最后,IS度量无法反应过拟合的情况,泛化能力差。
FID(Frechet Inception Distance score)
在计算IS的时候,其实只考虑了生成图像,并没有考虑到真实图像,无法反映出生成图像和真实图像的差距,而FID计算了生成图像与真实图像在特征空间上的距离。
FID同样也使用了分类器Inception V3,我们知道,对于输入为真实图像时,分类器池化层输出的高维特征应该是服从一个高斯分布的,那么对于生成图像,分类器的输出应该也会服从一个高斯分布,FID的目的正是要计算这两个高斯分布的差距,如果这两个分布相同,也就意味着生成图像的质量与多样性和真实图像的相同了。而对于多元的高斯分布来说,知道了分布的均值和协方差,我们就能确定分布的形状,那么从公式上来说,FID就是计算两个多元高斯分布的均值和协方差的距离:
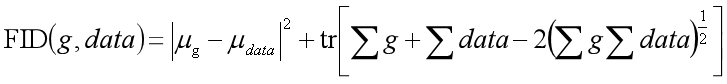
其中(μg, μdata)和(∑g, ∑data)分别是生成图像和真实图像的均值和协方差,tr表示矩阵的迹。那么FID越低,说明生成图片越接近真实训练集,图片质量和多样性也越好。
因为FID只利用了分类器的中间层,没有用到具体分类输出层,因此FID不受ImageNet数据集的限制。然而,FID对于特征向量比较敏感,但是没有涉及到特征值之间的空间关系,也就是说,FID无法评价那些质量很高但是对人类来说明显是“很奇特”的图片,例如鼻子长在了嘴巴下面,FID会认为是一张很好的图片。并且,对于过拟合的问题,FID也是无能为力。

MMD
(Maximum Mean Discrepancy,最大均值差异)
MMD通常被用来检测双样本的分布情况,是迁移学习中使用最广泛的度量之一。简单来说,MMD就是找到一个合适的映射函数,将生成图像和真实图像这两个分布映射到再生核希尔伯特空间H(RKHS,如果不映射到RKHS,那么所涉及的计算量几乎是无穷的),然后在RKHS中求两个分布均值的差:
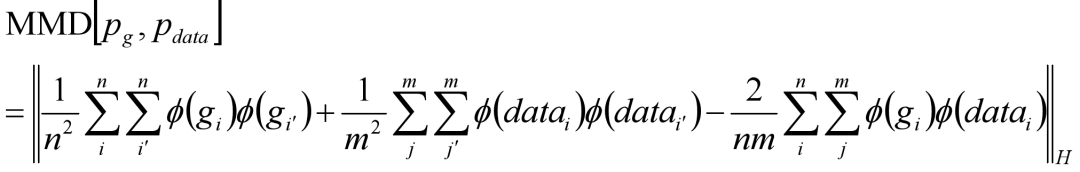
其中ϕ(*)是映射函数,gi、datai分别是生成图片样本集和真实图片样本集。而问题就在于,这个映射函数ϕ(*)很难去选择,在这种情况下,通过引入核函数k(*)将原式求ϕ(*)替换为求内积:
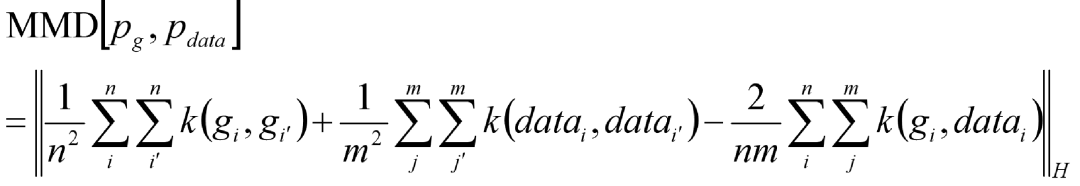
如此,选用好核函数(例如高斯核函数)之后,就可以计算出MMD。当然,MMD越小,说明两个样本之间的分布越接近,生成图片的结果越好。
1-NN
(1-Nearest Neighbor Classifier,1-最近邻分类器)
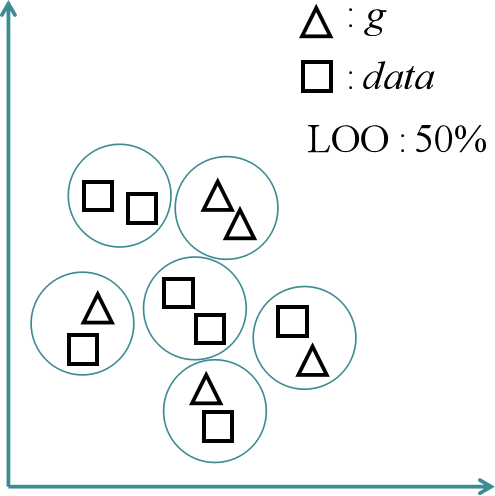
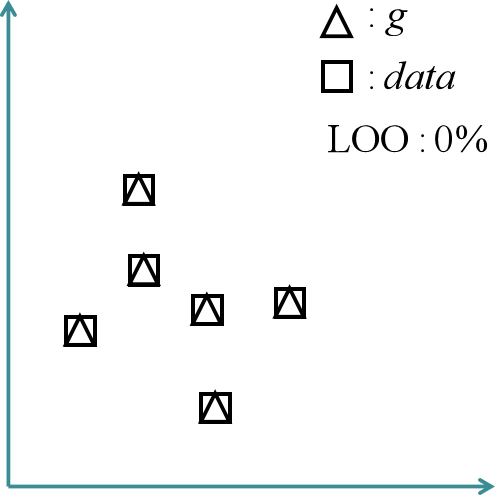
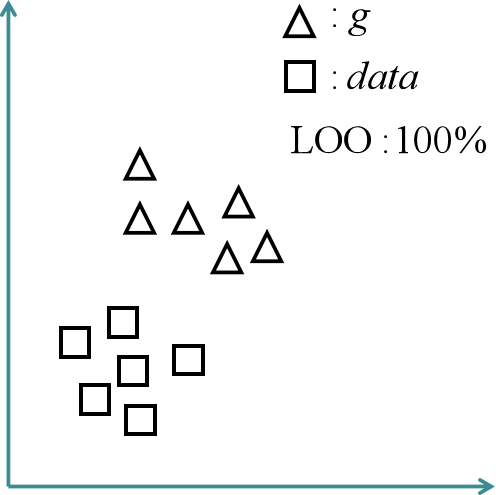
1-NN分类器也是被用来评估两个分布之间的距离,主要思路是对生成图像样本集{g1, g2, ..., gn}和真实图像样本集{data1, data2, ..., datan}采取留一法(leave-one-out,LOO)来求整体准确率作为评估指标。具体来说,就是将生成图像样本集和真实图像样本集以及对应的标签构成一个包含2n个样本的集合D,再将集合D分成两个集合D1和D2,其中D1只包含一个样本,其他2n-1个样本包含在D2中,接着利用D2训练1-NN二分类器,并用D1验证二分类器,将整个过程循环2n次,最终计算整体准确率。
在n无穷大的理想状况下,若两个分布相似,1-NN无法做出很好的分类,整体准确率应该接近50%的随机分类,这种情况下,说明生成图像的结果很好。如果生成图像过拟合了,或者极端点说,生成图像完美复刻真实图像的所有特征,那么每一个D2在D1中都会找到一个不同类别的距离为零的最近邻样本,这种情况下整体准确率为0%。而如果1-NN很好的区分了两个样本集,整体准确率接近100%,那就说明了生成图像的欠拟合。结果可以看出,1-NN的结构非常简单,几乎不涉及其他的超参数,同时也解决了上面几种评估指标无法反映过拟合情况的问题。
结语
GAN的定量评估指标远不止以上四种,不同的GAN模型所适用的指标也不尽相同。GAN在图像生成方面的能力令人惊叹,一个好的定量评估指标能够指导更好的GAN算法设计。最后一篇参考文献介绍了24种定量评估指标,然而每种指标多多少少都会有一些自身的局限性。因此,GAN的定量评估指标问题仍然有待探索研究。
参考文献
[1] Barratt, S., Sharma, R.: A note on the Inception score. arXiv preprint arXiv:1801.01973 (2018)
[2] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local Nash equilibrium[J]. In: NIPS (2017)
[3] Gretton, A., Borgwardt, K. M., Rasch, M. J.: A Kernel Method for the Two-Sample-Problem[J]. In: NIPS (2017)
[4] Xu, Q., Huang, G., Yuan, Y.: An empirical study on evaluation metrics of generative adversarial networks[J]. arXiv preprint arXiv:1806.07755 (2018)
[5] Borji, A.: Pros and cons of gan evaluation measures. arXiv preprint arXiv:1802.03446 (2018)

人工智能测评服务
上海计算机软件测评重点实验室(SSTL)人工智能测评服务面向计算机视觉、语音识别、自然语言处理、推荐与搜索等领域,聚焦人工智能应用过程中的模型功能有效性评估、模型性能评估、数据集质量评估、对抗样本防御能力等,提供全方位的测评服务,保障人工智能应用的质量。
主要测评内容包括:
A 人工智能模型的功能有效性
包括混淆矩阵、准确率、精度、召回率、F1-Score、ROC、AUC等测评指标
B 人工智能模型的性能
包括模型推断时间、模型运行占用的资源、模型的压缩程度、模型的存储需求、模型的算力需求等
C 人工智能系统数据集质量评估
包括数据集规模、数据集标注质量、数据集的均衡性等
D 人工智能系统防御对抗样本能力
利用自研的对抗样本生成工具,通过白盒或黑盒的方式生成对抗样本,评估系统防御对抗样本的能力、系统对于物理世界攻击的防御能力等
E 人工智能系统的鲁棒性
包括干扰数据对系统的影响、数据集分布对系统的影响、业务不相关数据对系统的影响等
F 人工智能系统的安全性
包括模型是否采用加密算法、系统的功能安全认证、接口安全认证、网络通讯的安全性等
G 人工智能治理评估
包括模型的可解释性、模型的公平性、系统的应用风险、系统的伦理风险等

上海市计算机软件测评重点实验室(简称SSTL),由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
