





标准化的人工智能模型评估方法是将数据集按一定比例划分为训练集、验证集和测试集,并且在测试集上评估模型的准确率,评估的指标一般有F1值、BLANC、BLEU等。这种方法存在一定的局限性,如果测试集不够全面,存在一定的偏差,那么会影响到评估结果,使数据集无法起到考察模型的“泛化性”的作用。
一个较高的F1值可以说明模型对当前的测试集有较好的拟合效果,但不一定能说明模型可以胜任其正在学习的任务。为了说明这点,来自ACL 2020的最佳论文《Beyond Accuracy: Behavioral Testing of NLP Models with CheckList》[3]给出了情感分析测试的几个例子,如下。

图1 否定能力的最小功能测试
图1是测试某个商用的情感分析模型的例子,从左往右每一列分别代表测试案例、期望输出、实际预测输出、是否通过测试。
案例A是用最小功能测试(Minimum Functionality Test,简称MFT,受启发于软件工程领域的单元测试)来测试模型的否定(Negation)能力。用“I {否定词} {积极动词} the {宾语}”形式的模版来生成测试用例。比如对“I can’t say I recommend the food”这句话,“否定+肯定”的表达形式带来的应该是否定的情感,但是模型的误判率达到76.4%。
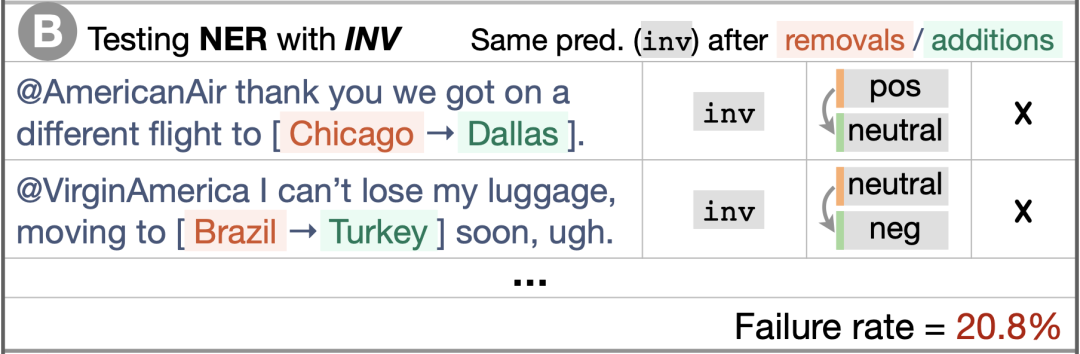
图2 命名实体识别能力的不变性测试
图2的案例B是用不变性测试(Invariance,简称INV,和下面的DIR都受启发于蜕变测试)来测试模型的命名实体识别(NER)能力。案例中将任意包含地名的句子中的地名替换成其他地名(比如:将Chicago换为Dallas),这样不会改变句子的情感表达,所以期望模型的输出和原来相比没有变化,但是被测试的模型的预测结果中有20.8%没有通过测试。
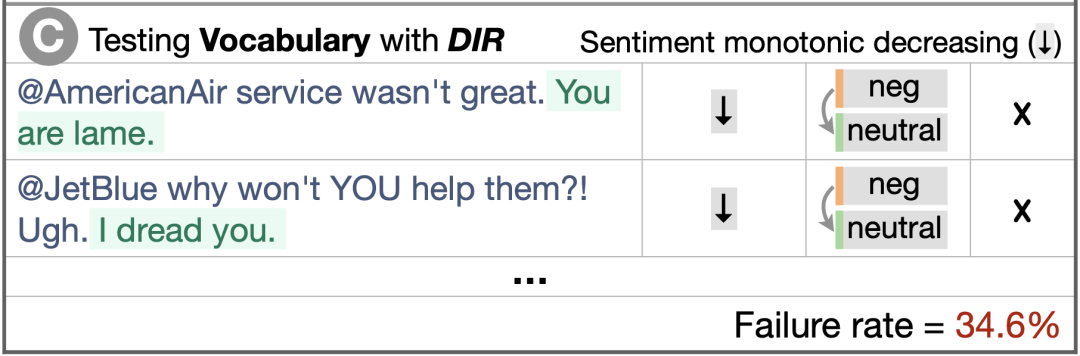
图3 词汇能力的定向期望测试
图3的案例C是用定向期望测试(Directional Expectation,简称DIR)来测试模型的词汇能力。在任意句子后加一句带有消极(或积极)情感色彩的短句,期望模型输出比原来更低(或更高)的情感预测结果,这项测试中模型的失败率达到34.6%。
可以看到,通过模版生成一些测试用例,或是在原来的测试数据中加入一些微小扰动,就可以对模型预测结果产生很大的影响,甚至是一些对人类来说非常轻松的任务,机器的失败率也非常高。因此,对NLP模型进行一些常见指标之外的测试是非常有必要的。
上一节的例子中,介绍了MFT、INV和DIR这三种测试类型,它们是受传统的软件测试中的单元测试和蜕变测试启发而来的。而除了上一节介绍的否定、命名实体识别和词汇以外,还有许多其他可以测试的能力。
下面的例子中1-3是情感分析任务,4-6是文本相似度任务,但这不代表这些能力测试只能用于本文介绍的任务,部分能力测试是通用的。
1.鲁棒性
如图4,一行为一个测试用例,在本文介绍的所有例子中红色部分表示从原文中去除的部分,绿色部分表示新加入的部分,灰色部分表示期望输出结果。这是几个测试鲁棒性的INV测试,通过在原句子后加入一些乱码、链接或是故意制造一些拼写错误,期望模型能输出和原来一样的结果。

图4 鲁棒性测试
2.时态
如图5,在同一句子中加入过去式和现在时的不同情感表达,期望模型能正确分辨出现在时的情感并且输出结果。

图5 时态测试
3.语义角色标注
如图6,前两个用例在同一句子中加入他人和说话人的情感表达,要求模型能够正确分析出说话人的情感。剩下的用例分别以“(问题,肯定回答)”和“(问题,否定回答)”的形式,要求模型能结合实际问答分析出正确的情感表达。

图6 语义角色标注测试
4.分类
如图7,这是一个QQP(Quora Question Pair,一个文本相似度任务)任务的INV测试,将其中一个句子的词汇替换成同义词,要求模型也输出不变的结果。

图7 分类测试
图8则是一个MFT测试,测试模型能否判断“更加乐观”和“更加不悲观”的含义相等,2019年的RoBERTa模型在这项测试中失败率达到了100%。

图8 分类测试2
5.指代消歧
如图9,替换句子中的人称代词,要求模型能够理解不同代词指代的不同角色,并且输出正确的结果。

图9 指代消岐测试
6.逻辑
要求模型能够掌握简单的逻辑能力,例如对称性、传递性等,公式表达如图10,原文没有提供具体的例子。

图10 逻辑测试
除了提出大量的测试方法,这篇ACL 2020的最佳论文还提出了“CheckList”——一个能够方便快捷生成以上测试用例的Python模块。
CheckList的安装非常方便,只需要通过“pip install checklist”即可安装,作者也提供了论文中使用到的情感分析、QQP、SQuAD三个任务的测试套件,可以通过以下四行代码直接载入生成对应的测试套件对象:

图11 载入情感分析测试套件
然后通过以下三行代码,即可进行对应的测试并且输出测试报告,其中第一行的路径是被测试模型根据测试用例输出的预测结果,论文也提供了测试用例,可以用我们自己的模型去对其进行预测并测试。

图12 读取模型进行测试并且输出
除了论文给出的三个测试套件,我们也可以用CheckList构建自己的测试套件并且保存和重用。CheckList内置了一部分模版,例如“形容词”、“男性名字”、“女性名字”等,我们也可以构建自己的模版生成句子,如图13。

图13 构建模板生成测试用例
CheckList还提供了一个非常方便的功能,在模版中加入“{mask}”标记,会自动调用RoBERTa模型进行掩码语言模型预测,根据前后文给出一系列建议的词汇以生成完整的句子,如图14。
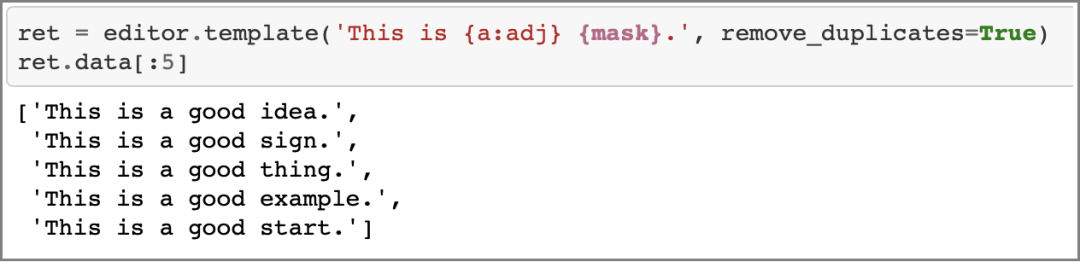
图14 利用RoBERTa生成测试用例
另外,CheckList还可以自动调用Wordnet来获取给定词的反义词、同义词、上义词和下义词以帮助测试用例的构建。
CheckList还提供了许多其他功能,本文不作过多介绍。论文的作者在https://github.com/marcotcr/checklist上提供了CheckList的开源实现和相关教程,感兴趣的读者可以前往阅读和使用。
在本期文章中我们介绍了NLP模型测试的必要性以及《Beyond Accuracy: Behavioral Testing of NLP Models with CheckList》这篇文献提供的几种新颖的NLP测试方法,还有CheckList这个非常方便的测试工具。
NLP测试目前还是一个发展空间非常大的研究方向,测试的方法和指标远远不止本文介绍的这几点。希望读者在阅读本文后能够受到一定的帮助和启发,共同为NLP测试作出贡献。
参考文献
[1] Devlin, J.; Chang, M.-W.; Lee, K. & Toutanova, K. (2018), 'BERT: Pre-training of Deep Bidirectional Transformers for Language
Understanding' , cite arxiv:1810.04805 .
[2] Radford, A.; Narasimhan, K.; Salimans, T. & Sutskever, I. (2018), 'Improving language understanding by generative pre-training', .
[3] Ribeiro, M. T.; Wu, T.; Guestrin, C. & Singh, S. (2020), Beyond Accuracy: Behavioral Testing of NLP Models with CheckList., in Dan Jurafsky; Joyce Chai; Natalie Schluter & Joel R. Tetreault, ed., 'ACL' , Association for Computational Linguistics, , pp. 4902-4912 .


上海市计算机软件测评重点实验室(简称SSTL),由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

