




引言

自然语言处理(Natural Language Processing,以下简称NLP)是人工智能从感知迈向认知的关键技术,是人工智能研究领域的一个重要方向。上一期我们介绍了中文分词、指代消歧和机器翻译这三个NLP应用场景,本期我们将继续介绍语言模型、依存句法分析和多任务学习。

语言模型
(Language modeling)
语言模型可以判断一段文本是否是正常语言。语言模型在语音识别、拼写纠错、机器翻译、OCR识别中都有应用。通过给定一个句子(词汇序列),语言模型预测该句子的下一个词汇,计算它出现的概率。语言模型的标准定义如下:
对于语言序列,w1,w2,…,wn,语言模型就是计算该序列的概率,即P(w1,w2,…,wn)。
从机器学习的角度看,语言模型就是对语句的概率分布的建模。通俗的解释,语言模型就是判断一个序列是否是人话,例如:P(I am light)>P(Light I am)。
语言模型可以分为统计语言模型和神经网络语言模型。
统计语言模型采用极大似然估计来计算每个词出现的概率。对于任意长的语句根据极大似然估计来计算P(wi|w1,w2,…,wi-1)显然不现实,因此引入马尔科夫假设(Markov assumption),即假设当前词出现的概率只依赖于前n-1个词,对应的语言模型则称为n-gram语言模型。
未登录词(OOV)问题是统计语言模型的一大痛点,即测试集中出现训练集中未出现过的词,会导致模型输出的概率为零。一般采用平滑技术来解决这个问题,Interpolation平滑的核心思想是计算Trigram概率的同时考虑Unigram,Bigram,Trigram出现的频次,即将它们加权平均,抵消某个n-gram概率为0带来的影响。除此以外还有Laplace、Kneser-Ney等平滑技术。
如下图所示为Bengio在03年提出的前馈神经网络语言模型[1],它先给每个词在连续空间中赋予一个向量(词向量),再通过神经网络去学习这种分布式表征。利用神经网络去建模当前词出现的概率与其前 n-1 个词之间的约束关系。很显然这种方式相比 n-gram 具有更好的泛化能力,只要词表征足够好。从而很大程度地降低了数据稀疏带来的问题。但是这个结构的明显缺点是仅包含了有限的前文信息。
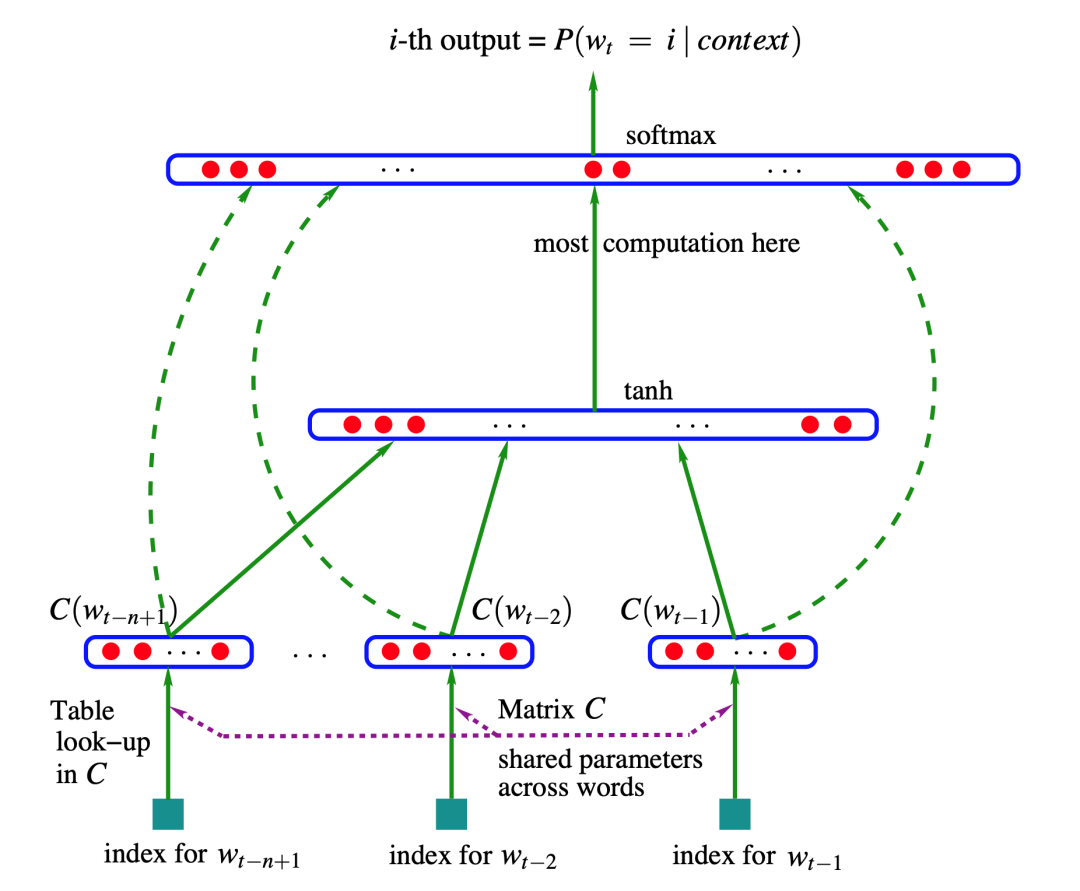
Mikolov在2010年提出在语言模型中使用循环神经网络(RNN)[2],隐状态的传递性使得RNN语言模型可以捕捉序列中的所有信息,有效解决了统计语言模型和前馈神经网络语言模型的不足。
统计语言模型和神经网络语言模型各有其优势和不足。统计语言模型参数容易训练,可解释性强,但缺乏长距离依赖,只能对前n-1个词进行建模,且难以避免数据稀疏和OOV问题;神级网络语言模型可以建立长距离依赖,避免OOV问题,但是模型训练时间较长,并且缺乏可解释性。
语言模型往往用困惑度(Perplexity)来评估其效果,困惑度可以简单理解为文本出现概率的倒数。困惑度越小,说明所建模的语言模型越精确。好的语言模型对于未观察过的流畅的文本应该能输出一个高概率或者低困惑度,反之则输出低概率或高困惑度。
英文语言模型的常用数据集有Penn Treebank(包含约1M的单词,主题为新闻)、WikiText-103(包含约103M单词,多为维基百科上的词条)、Google 1B(包含约1B单词,主题为新闻评述)。中文语言模型的常用数据集有Chinese Treebank (CBT) v9(包含约2M词汇)、Chinese Gigaword v5(包含约934k词汇)。
依存句法分析
(Dependency parsing)
依存句法分析需要遵循某一语法体系,根据该体系的语法确定语法树的表示形式,下图为一个依存句法分析的例子。

常见的关系标签有root(中心词,通常是动词)、nsubj(名词性主语)、dobj(直接宾语)、prep(介词)、pobj(介词宾语)、cc(连词)、compound(复合词)、advmod(状语)、det(限定词)、amod(形容词修饰语)等。
句法分析的典型应用是意见抽取(Opinion extraction)和信息检索(Information retrieval)。在意见抽取中,例如“这篇文章的内容质量很好”这句话,“很好”形容的是“这篇文章”。在信息检索中,对于“某某的儿子是谁?”和“某某是谁的儿子?”这样的两种查询,他们的词袋模型是一样的,不考虑语法结构的话很难返回正确的结果。而借助句法分析,得到表示依存关系的语法树后,可以从中抽取出对应的搭配从而解决上面提到的两个问题。
在20世纪70年代,Robinson提出依存语法中关于依存关系的四条公理:
一个句子中只有一个成分是独立的;
其它成分直接依存于某一成分;
任何一个成分都不能依存与两个或两个以上的成分;
如果A成分直接依存于B成分,而C成分在句中位于A和B之间,那么C或者直接依存于B,或者直接依存于A和B之间的某一成分。
依存句法分析的常用方法可以分为基于规则、基于统计和基于深度学习的方法。
基于规则的方法: 早期的基于依存语法的句法分析方法主要包括类似CYK的动态规划算法、基于约束满足的方法和确定性分析策略等。
基于统计的方法:统计自然语言处理领域也涌现出了一大批优秀的研究工作,包括生成式依存分析方法、判别式依存分析方法和确定性依存分析方法,这几类方法是数据驱动的统计依存分析中最为代表性的方法。
基于深度学习的方法:近年来,深度学习在句法分析课题上逐渐成为研究热点,主要研究工作集中在特征表示方面。传统方法的特征表示主要采用人工定义原子特征和特征组合,而深度学习则把原子特征(词、词性、类别标签)进行向量化,在利用多层神经元网络提取特征。
依存句法分析的常用数据集有Penn Treebank、Universal Dependencies Treebank。通常使用的指标包括:无标记依存正确率(Unlabeled attachment score, UAS)、带标记依存正确率(Labeled attachment score,LAS)、依存正确率 (Dependency accuracy,DA)、根正确率(Root accuracy,RA)、完全匹配率(Complete match,CM)等。
无标记依存正确率:测试集中找到其正确支配词的词(包括没有标注支配词的根结点)所占总词数的百分比。
带标记依存正确率:测试集中找到其正确支配词的词,并且依存关系类型也标注正确的词(包括没有标注支配词的根结点)占总词数的百分比。
依存正确率:测试集中找到正确支配词非根结点词占所有非根结点词总数的百分比。
根正确率:有二种定义,一种是测试集中正确根结点的个数与句子个数的百分比。另一种是指测试集中找到正确根结点的句子数所占 句子总数的百分比。
完全匹配率:测试集中无标记依存结构完全正确的句子占句子总数的百分比。
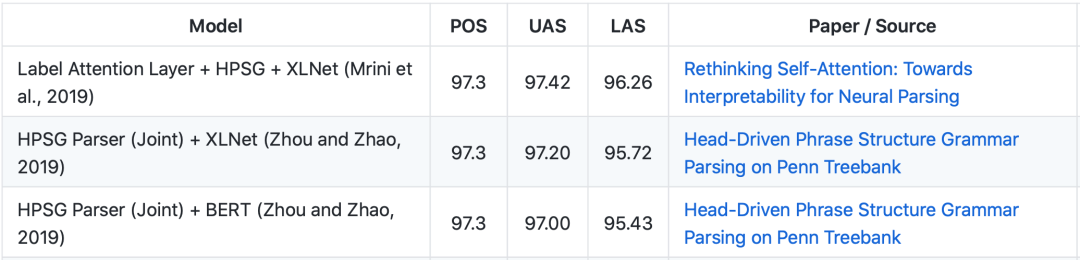
下图为Penn Treebank数据集上部分较新模型和它们的实验结果。
多任务学习
(Multi-task learning)
多任务学习的目标是同时学习多个不同的NLP任务,并最大化其中一个或全部任务的性能。
多任务学习的常用基准测试为DecaNLP(Natural Language Decathlon)[3]、GLUE(General Language Understanding Evaluation benchmark)[4]和SuperGLUE[5]。
DecaNLP由Salesforce发布,涵盖了十个任务:问答、机器翻译、摘要、自然语言推理、情感分析、语义角色标注、关系抽取、任务驱动多轮对话、语义分析和代词消解。
下图为DacaNLP的十个任务与对应数据集和评测指标简介。
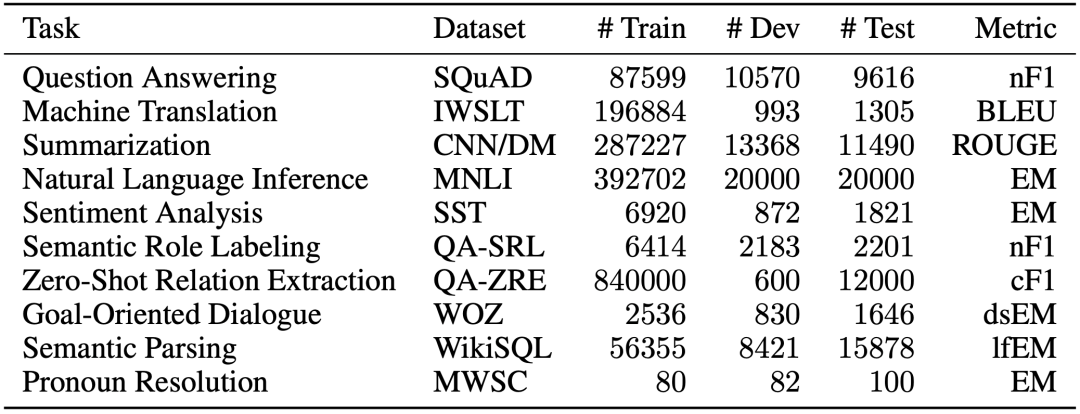
其中,EM为精确匹配(Exact match)比较,相当于准确率。基于n-gram的BLEU在上一期的文章中有相关介绍。ROGUE是摘要(Summarization)任务中常用的评测指标,可以分为ROGUE-N和ROGUE-L。ROGUE-N与BLEU类似,计算n-garm在candidate和reference中的共现比率,是基于召回率的指标,ROGUE-L基于最长公共子序列(LCS),与n-gram的主要区别为LCS不要求连续匹配,只要求顺序匹配,优点是不需要预先定义n-gram的长度,缺点是只考虑最长的子序列,忽略了其他较短的子序列的影响。
GLUE与DecaNLP类似,是一种评估和分析模型在各种现有自然语言理解任务中的性能的工具,根据所有任务的平均精度对模型进行评估。
下图为GLUE的任务与对应数据集和评测指标的简介 。
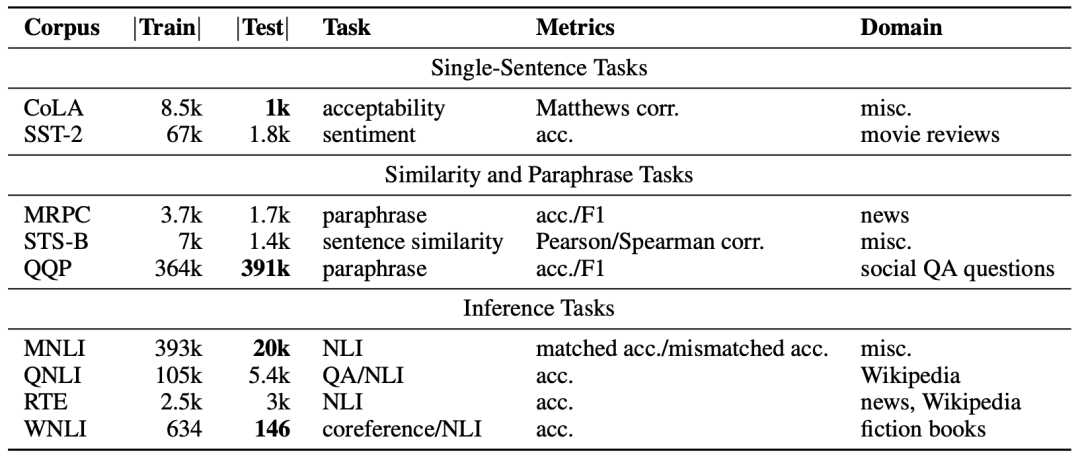
GLUE中的所有任务都可以归为单句或者是句子对的分类任务,除了STS-B,这是一个回归任务。大部分评测指标都为准确率,除此以外也有Matthews相关系数和Pearson/Spearman相关系数等,Matthews相关系数利用混淆矩阵来计算,Pearson和Spearman相关系数来自于统计学。
下图是GLUE上的人类基准和部分模型得分。
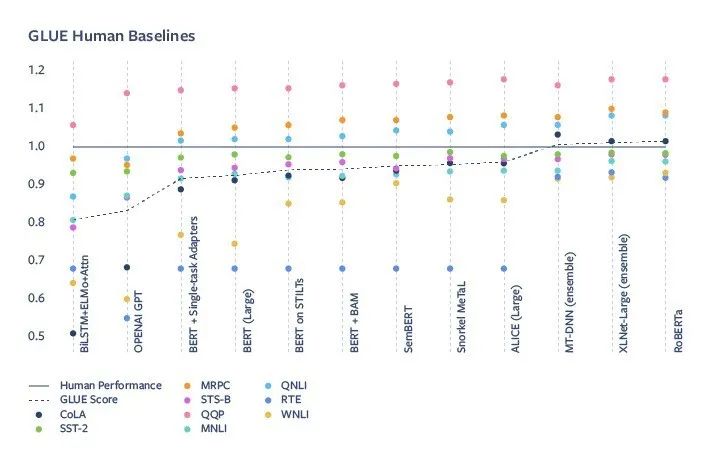
可以看到,随着GPT和BERT的出现,NLP模型的水平大幅提升,BERT在GLUE基准测试中得分与人类不超过10%,而RoBERTa已经超过了人类,但这并不意味着机器已经掌握了自然语言。参与制定GLUE的DeepMind、纽约大学、华盛顿大学联合Facebook提出了新的多任务学习测试标准SuperGLUE。
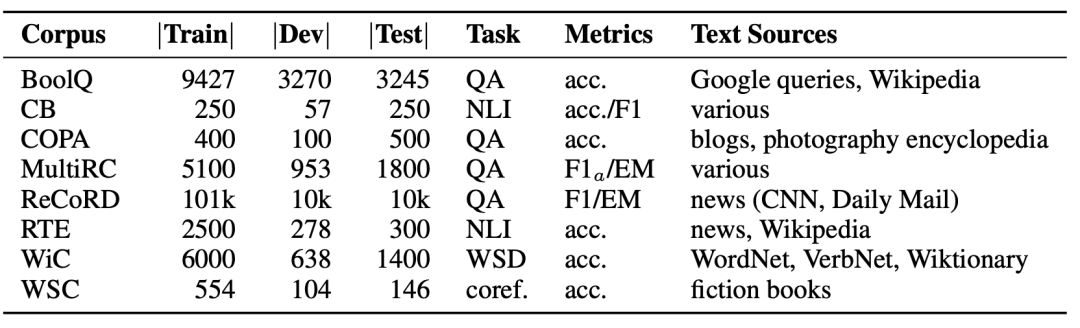
下图为SuperGLUE的数据集、任务和评测指标简介,其中WSD为词义消歧(Word sense disambiguation),coref.是指代消解(Coreference resolution),其余任务简称在前文均有介绍。
下图为部分模型的平均SuperGLUE得分与人类基准,可以看到在GLUE上超越人类的RoBERTa在SuperGLUE上与人类仍然有较大差距。因此,SuperGLUE对NLP模型的性能评测带来了更大的挑战。

总结
在本期文章中我们介绍了语言模型、依存句法分析和多任务学习这几个NLP技术和应用,其中多任务学习包含多个其他的NLP任务,是目前比较常用的NLP模型评测指标。
但是,NLP的应用场景远远不止这些。在这两期的NLP应用场景与评测指标介绍中,我们挑选了比较有代表性的几个技术应用和评测指标进行详细介绍,希望研究NLP模型和测评的学者可以对这个领域的主要研究问题和评测方法有一个全面的了解。
参考文献
1.Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3, 1137–1155.
2.Mikolov, T.; Karafiát, M.; Burget, L.; Cernock, J. & Khudanpur, S. (2010), Recurrent neural network based language model., in 'INTERSPEECH' , pp. 3 .
3.McCann, B.; Keskar, N. S.; Xiong, C. & Socher, R. (2018), 'The Natural Language Decathlon: Multitask Learning as Question Answering' , cite arxiv:1806.08730 .
4.Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O. & Bowman, S. R. (2019), GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding, in 'ICLR (Poster)' , OpenReview.net, .
5.Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O. & Bowman, S. R. (2019), SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems., in Hanna M. Wallach; Hugo Larochelle; Alina Beygelzimer; Florence d'Alché Buc; Emily B. Fox & Roman Garnett, ed., 'NeurIPS' , pp. 3261-3275 .

扫码关注:上海市计算机软件评测重点实验室

觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

