




引言

自然语言处理(Natural Language Processing,以下简称NLP)是人工智能的一个重要分支,是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。NLP是一门融语言学、计算机科学、数学于一体的科学。NLP有着非常多的应用,本文将以几个具有代表性的NLP应用场景为例,介绍它们的常用数据集与评测指标。

中文分词
(Chinese word segmentation)
中文分词是中文NLP的一个基础任务,大部分其他任务都是其下游任务。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符。虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比英文要复杂得多、困难得多。
下图为中文分词的一个例子:

中文分词根据实现原理主要可以分为以下两种方法:
01
基于词典的分词方法
也称字符串匹配分词算法。该算法是按照一定的策略将待匹配的字符串和一个已建立好的“充分大的”词典中的词进行匹配,若找到某个词条,则说明匹配成功,识别了该词。常见的基于词典的分词算法分为以下几种:正向最大匹配法、逆向最大匹配法和双向匹配分词法等。基于词典的分词算法是应用最广泛、分词速度最快的。很长一段时间内研究者都在对基于字符串的匹配方法进行优化,比如最大长度设定、字符串存储和查找方式以及对于词表的组织结构,采用TRIE索引树、哈希索引等。
02
基于统计的机器学习算法
目前常用的是算法是HMM、CRF、SVM、深度学习等算法,比如Stanford、Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
中文分词的一个常用工具是结巴分词,其基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG),同时采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
中文分词的常用数据集有Chinese Treebank(CTB6包括78,000个词, 超过128万个中文字符,CTB7包括2448个文档,51447句子,1,196,329个词以及超过190万个中文字符)、CityU、PKU、MSRA,评估指标一般为F值。
下表为Chinese Treebank 6数据集上部分较新模型的F值。

指代消歧
(Coreference resolution)
指代消歧是聚类文本中的涉及相同潜在真实世界实体的代词的任务。例如下图中“he”与“Obama”属于同一个聚类,而“I”、“my”和“she”属于另一个聚类。

指代消歧的常用数据集有CoNLL2012(包括144k个coreference,主题为新闻)和GAP(来自Gendered Ambiguous Pronoun Resolution,包含8908个coreference标注对)。在CoNLL2012上的评估指标为MUC、B-cubed、CEAF和BLANC几个指标的平均F值,在GAP上的评估指标为F值。本文将简要介绍CoNLL2012所用的几个评估指标。
01
MUC
MUC关注数据中的链接。用Key来表示手工标注的参照共指链,Response表示某个模型输出的共指链。K和R中实体之间的公共链接数除以K中的链接数表示召回率,而精确度是K和R中实体之间的公共链接数除以R中的链接数。它的缺陷在于无法衡量系统预测单例实体(singleton entity)的性能。
02
B-cubed
B-cubed可以克服MUC的缺点,它主要关注实体。
对某个实体mi,它的B-cubed Precision和Recall计算方式如下:

其中Rmi和Kmi分别表示R和K中与mi有连接的所有实体,所有实体的对应指标平均值则为最终的B-cubed指标值。
03
CEAF
CEAF更关注实体之间的相似度,首先需要选择一种相似度函数φ(Ki,Ri)用来度量共指链实体的相似度。然后从K与R两个集合中较小的集合向另一个集合建立一一对应的映射并计算对应实体的相似度,得到相似度之和最大的映射g*称为最优映射,记Φ(g*)为最优映射相似度之和,则CEAF Presicion和Recall为:
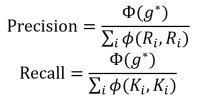
04
BLANC
BLANC与传统的F值计算类似,但不完全相同。它的混淆矩阵如下,其中GOLD为标注数据,SYS为模型预测数据。
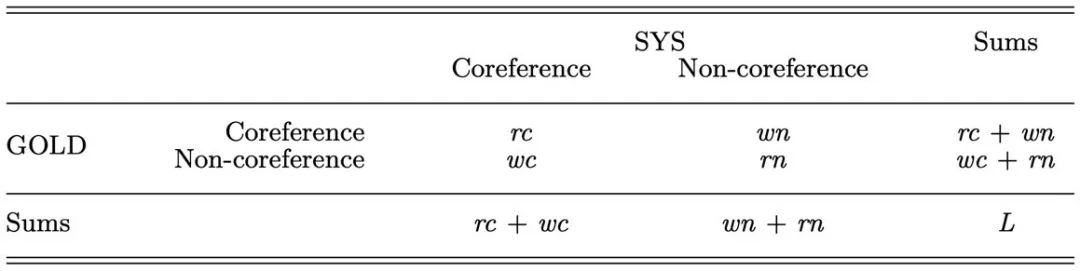
对应的Precision、Recall和F值计算如下:

以上几种指标关注的重点各不相同,CoNLL2012数据集上的实验平均了它们的F值作为最终的评测结果。
机器翻译
(Machine translation)
机器翻译即将源语言中的句子翻译成目标语言的任务。
常用的数据集有WMT2014 EN-DE(英语-德语)与WMT2014 EN-FR(英语-法语),中文机器翻译的数据集有WMT17、NIST、IWSLT、MTTT(The Multitarget TED Talks Task )、CWMT等。
常用的评测指标有人工评判、编辑距离、BLEU score等,这里主要介绍一下BLEU score。
首先介绍n-gram的准确率pn,n-gram即指句子中任意连续n个单词构成的短句,记candidate为机器翻译模型给出的翻译,reference为参考人工翻译(往往不止一个),则对candidate中的某个n-gram,求出它在所有reference中的最大出现次数与它在candidate中的出现次数,取其中较小值,记为count(clip),所有count(clip)之和与candidate中的n-gram总数的比值则为pn。
下图为一个1-gram的例子。

Candidate中只有一个1-gram(the),它在candidate中出现了7次,在reference 1中出现了2次,所以p1=2/7。
下图为一个2-gram的例子。

其中,candidate只有一个2-gram(of the),p2=1/1。
可以看到,candidate和reference的长度差异过大会影响n-gram评估的结果。因此,加入一个惩罚数BP(brevity penalty),下式中c代表candidate长度,r代表与c最接近的reference的长度。
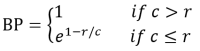
有了以上定义后,我们可以定义BLEU score,通常N取4,Wn取1/N。
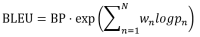
BLEU从不同粒度考虑了机器翻译的结果与人工翻译的结果的相似性,同时加入惩罚数以避免极端的机器翻译结果对准确率度量的影响,是一个应用广泛的机器翻译评估指标。
总结
随着NLP的发展,人工智能正从“感知智能”走向“认知智能”。NLP几乎可以进行任何与自然语言有关的应用,它的应用场景远远不止本文所介绍的这几个。
同时,对NLP模型的评测指标也在不断发展当中,从最基本的精确率、召回率和F值,到基于集合的MUC、B-cubed、CEAF和BLANC,再到基于不同粒度相似度的BLEU,它们各有不同的侧重点,应用在不同的数据集和NLP任务中。
然而,NLP还在高速发展当中,对于一些较新的NLP模型(例如Transformer、BERT),它们在某些评测方法上的表现已经和人类几乎没有差异,一般的数据集和评测指标已经不足以评估它们的性能。因此对NLP模型的评测也是一个非常重要的研究方向。
参考文献
1.Pradhan, S.; Moschitti, A.; Xue, N.; Uryupina, O. & Zhang, Y. (2012), CoNLL-2012 Shared Task: Modeling Multilingual Unrestricted Coreference in OntoNotes., in Sameer Pradhan; Alessandro Moschitti & Nianwen Xue, ed., 'EMNLP-CoNLL Shared Task' , ACL, , pp. 1-40 .
2.Bagga, A. & Baldwin, B. (1998), Algorithms for scoring coreference chains, in 'The first international conference on language resources and evaluation workshop on linguistics coreference' , pp. 563--566 .
3.Luo, X. (2005), On coreference resolution performance metrics, in 'HLT '05: Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing' , Association for Computational Linguistics, Morristown, NJ, USA , pp. 25--32 .
4.Recasens, M. & Hovy, E. H. (2011), 'BLANC: Implementing the Rand index for coreference evaluation.', Nat. Lang. Eng. 17 (4), 485-510.
5.Papineni, K.; Roukos, S.; Ward, T. & Zhu, W.-J. (2001), BLEU: A Method for Automatic Evaluation of Machine Translation, in 'ACL '02: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics' , Association for Computational Linguistics, Morristown, NJ, USA , pp. 311--318 .

扫码关注:上海市计算机软件评测重点实验室

觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

