





让我们从这张图片开始说起吧,这是2015年Twitter上的一位用户在吐槽Google Photos将他的黑人朋友识别成了大猩猩。这不是偶然,美国电商巨头亚马逊也曾被爆出使用的人工智能简历筛选技术更加倾向男性。这些事件说明了人工智能算法不是100%可靠的,人工智能也会有偏差,甚至是出错。将黑人识别成大猩猩,简历筛选倾向男性,对于黑人群体和女性群体来说,这就是人工智能算法对他们的偏见和不公平。
算法为什么会产生不公平
我们先来回顾一下简单的人工智能深度学习网络的训练过程:研究人员收集大量数据,接着将收集到的数据进行标记标签,然后将数据和标签成对输入神经网络进行训练。从以上三个步骤中我们大致能够看出导致算法不公平的两个主要原因:输入的数据的偏见以及算法模型本身的偏见。
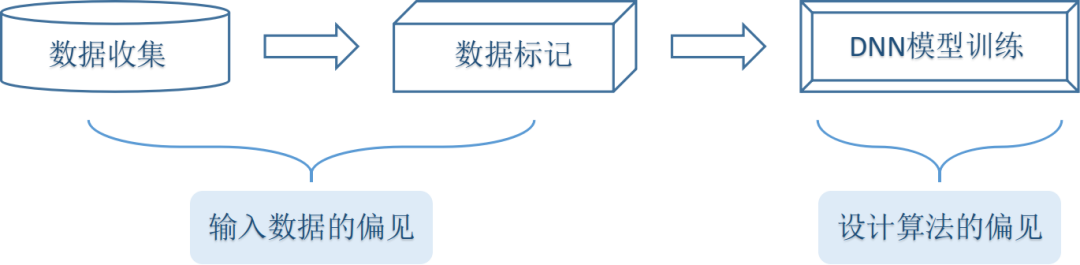
原因1:输入数据的偏见
我们来看一个实际应用:使用智能手机获得到达目的地的最快路线。首先,至少需要三个输入:(1)当前位置,(2)目的地,(3)地图。然后使用算法计算从(1)到(2)的最快路线。最基本的算法系统可以简单地利用地图数据作为输入,例如所在地区道路的名称、位置和长度,算法系统会计算出地图上包含最少或最短道路的路线。更复杂的算法系统还可以包括每条道路的限速信息,或者包括实时交通拥堵的信息,当然还可能包括许多其他信息,例如天气变化情况、实时红绿灯、是否发生车祸以及上下班高峰等等。
手机导航系统所需的输入如此之多,倘若输入数据产生了某种偏差,输出结果就会产生某种不公平。会导致输出不公平的一些数据原因包括:
数据选择不当。算法系统的开发人员决定了输入数据,开发人员可能只拥有包含相关道路的信息,而缺少公交或非机动车的信息,这样的导航系统对不开车的人群无法提供准确的导航服务,对这些人群来说是不公平的。
数据缺失、偏差或过时。如果算法系统没有定期更新公交或火车时刻表,即使该导航系统在其他方面运行良好,最终的结果也可能再次阻碍公共交通的使用,并对那些没有替代出行方案的人造成不公平。
选择性偏见。人工智能会将输入数据的一般特征误认为是整个世界的普遍特征,然而再多的输入数据也无法代表整个世界,因此算法系统的输出总会偏向一些群体而忽视另一些群体。例如,如果只从年轻人群体那里收集速度数据,那么该导航系统对老年人群体则不准确。
数据偏见延续。在这种情况下,算法系统会将过去的输入或输出的偏见自我复制到当前的输出中。例如,在一个主要由男性组成的工作场所中,被设计成偏向适应公司文化的招聘系统可能会招聘更多的男性。
原因2:设计算法的偏见
人工智能深度学习算法系统的最终产品就像一个“黑匣子”——一台不透明的机器。它接受输入,执行一些难以理解的过程,并根据该过程提供无法解释的输出,即使是开发人员都可能不了解算法系统中涉及的技术过程。这意味着人们无法了解人工智能做出某种决定的原因,甚至意味着无法发现和纠正某些隐藏的错误或偏见。特别是在延续了数据偏见的情况下,人工智能会一步步走向歧路。因此,在设计并使用人工智能的过程中,要尽可能鼓励透明度、问责制和适当程序机制。算法本身产生偏见的原因包括:
匹配系统偏差。对于搜索引擎、社交媒体平台来说,需要依赖匹配系统来确定搜索结果、广告投放以及业务推荐。如果系统设计未及时更新,或者没有考虑到所用数据及算法中的历史偏见,那么这些匹配系统可能会导致结果不公平。
个性化与推荐服务。推荐系统会收集并分析用户的详细信息,推断他们的偏好、兴趣和信仰,以便为他们推荐新音乐下载、视频观看、价格折扣等信息。此类推荐算法可能会无意中限制信息向某些群体的流动,缩小而不是扩大用户的选择范围。
相关与因果。算法系统本身可能会认为,由于两个因素经常一起发生(例如,具有一定的收入水平和特定的种族),两者之间必然存在因果关系。在这种情况下,假设因果关系会导致歧视与不公平。

什么是公平
上一节我们大致了解了下人工智能产生不公平的原因,在讨论如何解决不公平之前,我们需要先解决另一个问题——什么是公平?屏幕前的你可能会立刻抛出各种定义:公平就是人人平等,或者是处理事情不偏不倚,或者是人人享有同等的权力和义务,或者是“耕者有其田”,或者是......。这个问题的答案有太多的“或者”了,任何一种定义都可以解释公平,但任何一种定义都无法完全覆盖公平。
在2018年ACM的 FAT会议上,普林斯顿大学的Arvind Narayanan副教授做了一场演讲,从计算机科学和统计学的角度阐述了21种不同的公平性定义,即使是这样,所阐述的公平性定义仍然是不全面的,言下之意,目前我们还无法给出一个全面的公平性定义,只能是具体定义适用具体问题。
目前界内对于公平的讨论大多集中在个体公平(Individual Fairness),即平等对待每一个个体,以及群体公平(Group Fairness),即对于群体是公平的,特别是对于潜在的弱势群体是公平的。但是如何判断评估一个系统是否符合个体公平、群体公平或者其他公平的要求是非常复杂的。而且,对于公平的不同定义,也显示出了对不同利益的权衡。目前已经有许多关于公平性的数学定义,包括人口均等(Demographic Parity)、机会均等(Equality of Opportunity),因果推理(Causal Reasoning)等。虽然这些定义每一个都是正确的,但人工智能系统无法同时满足公平的多个衡量标准。这也说明了为什么即使COMPAS(一款评估罪犯再次犯罪可能性的系统)无法解决“误报”问题,其开发公司仍然宣称系统是公平的,因为COMPAS符合了预测性均等(Predictive Parity)定义。
此外,过度强调公平,也会带来一些消极影响。例如,平等批准相同的贷款额度,将会影响无力偿还人群的信用评分。公平是非常复杂的,仅仅通过单一且通用的标准去定义公平将永远无法实现公平。应当根据不同情况,设置公平的不同衡量指标和标准。
如何减少不公平
在数据收集到模型训练的整个过程中,可以从三个步骤来减少算法不公平:
数据预处理:数据集是人工智能算法学习特征的主要来源,因此对其进行预处理可以防止不公平的数据输入到模型中。可能因为训练数据本身捕捉到了历史歧视,或者是数据中有其他的潜在偏见,例如由于少数群体的代表性不足,该群体出现不公平的可能性更大。
学习算法修正:修改或更改最新的学习算法,以消除模型训练过程中的不公平,目前最常见的方法是在目标函数中加入相关约束。
模型后期处理:修改先前训练好的分类器,以在不同的组上获得期望的结果。如果学习后的模型是一个黑箱,而不能对训练数据或学习算法进行任何修改,则只能进行模型后期处理,黑箱模型最初分配的标签会根据函数进行重新分配。
以上是根据算法的处理过程而划分的减少不公平的方法,当然,还有许多其他的缓解不公平的方法,例如可变自动编码器(VAE):避免敏感属性的不公平干扰;对抗学习:缓解从刻板关联数据中学习到的偏见;反事实转换:将无关的所有数据随机转换为反事实值进行数据增广。在之后的公平性系列文章中,我们将对这些不公平解决方案进行详细研究,本文不再赘述。
结语
人类创造出了“公平”这个主观性的概念,人工智能的公平性也始于人类。那么,由谁来定义公平?如何去评判各种公平性定义?又由谁来决定公平的考量因素?在解决人工智能不公平的过程中,我们都会有自身的盲点,但是正是由于拥有不同的盲点,这种多样性能够使我们更好地识别事物中的各种不公平。
令人无奈的是,在人工智能算法不断精进的过程中,偏见、歧视、不公平等问题将会一直伴随其左右。对于算法模型来说,输入数据只不过是一串冷冰冰的数字,但是在数据背后,可能是一个等待房贷的年轻家庭,是一个紧张万分的求职者,是一个渴求知识的学生。因此,在不断研究深度学习算法背后的原理机制的前提下,人类仍然不能过分依赖并信任这些看似“高大上”的新系统。在开发使用这些系统产品时,完善可解释性、透明度、问责制和正当程序机制,确保以有效、公平、合乎法律与道德的方式来服务大众。
参考文献
[1] Zhang Y , Zhou L . Fairness Assessment for Artificial Intelligence in Financial Industry[J]. arXiv:1912.07211. 2019.
[2] Du M , Yang F , Zou N , et al. Fairness in Deep Learning: A Computational Perspective[J]. arXiv:1908.08843. 2019.
[3] Bird S , Kenthapadi K , Kiciman E , et al. Fairness-Aware Machine Learning: Practical Challenges and Lessons Learned[C]. the Twelfth ACM International Conference, ACM. 2019.


上海市计算机软件评测重点实验室(简称SSTL)由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

