




引言
在传统的机器学习中,我们通常关心如何优化特定任务的某个指标,衡量的方式是损失函数,在不断的迭代求解中,最终可以对指定的任务得到较好的结果。但是在现实中,我们可能需要同时处理许多不同的问题,并且这些问题之间存在一定的相关性,这时我们不应该忽略这种相关性,这些任务往往可以通过共享表示信息来相互促进,有助于在我们关心的指标上做的更好,这种方式被称作多任务学习。具体来说,也就是在相关任务中共享神经网络表示信息,提高原始任务的泛化性能。本质上看,这是一种将人类的先验信息融入神经网络中的方式。

本文将围绕深度学习中多任务学习的原理、网络结构与损失函数设计、现有和潜在的应用场景进行分享。
为什么要多任务学习
提出多任务学习的动机有很多角度:首先,从生物学角度考虑,中国有一句成语“触类旁通”很好地解释了这个问题,人类可以从相似或相关的问题中找到灵感,例如一个数学家很可能在物理学领域同样取得瞩目的成就,这说明类似的任务可以互相促进人类的学习;其次,从教学法的角度来看,我们首先学习的任务是那些能够帮助我们掌握更复杂技术的技能,例如在电影Karate Kid中Miyagi先生教会学空手道的小孩磨光地板以及为汽车打蜡这些表面上没关系的任务,然而,结果表明正是这些无关紧要的任务使得他具备了学习空手道相关的技能;最后,从机器学习的角度来看,我们将多任务学习视为一种归约迁移(inductive transfer)。归约迁移(inductive transfer)通过引入归约偏置(inductive bias)来改进模型,使得模型更倾向于某些假设。举例来说,常见的一种归约偏置(Inductive bias)是L1正则化,它使得模型更偏向于那些稀疏的解。
多任务学习的共享模式
硬共享
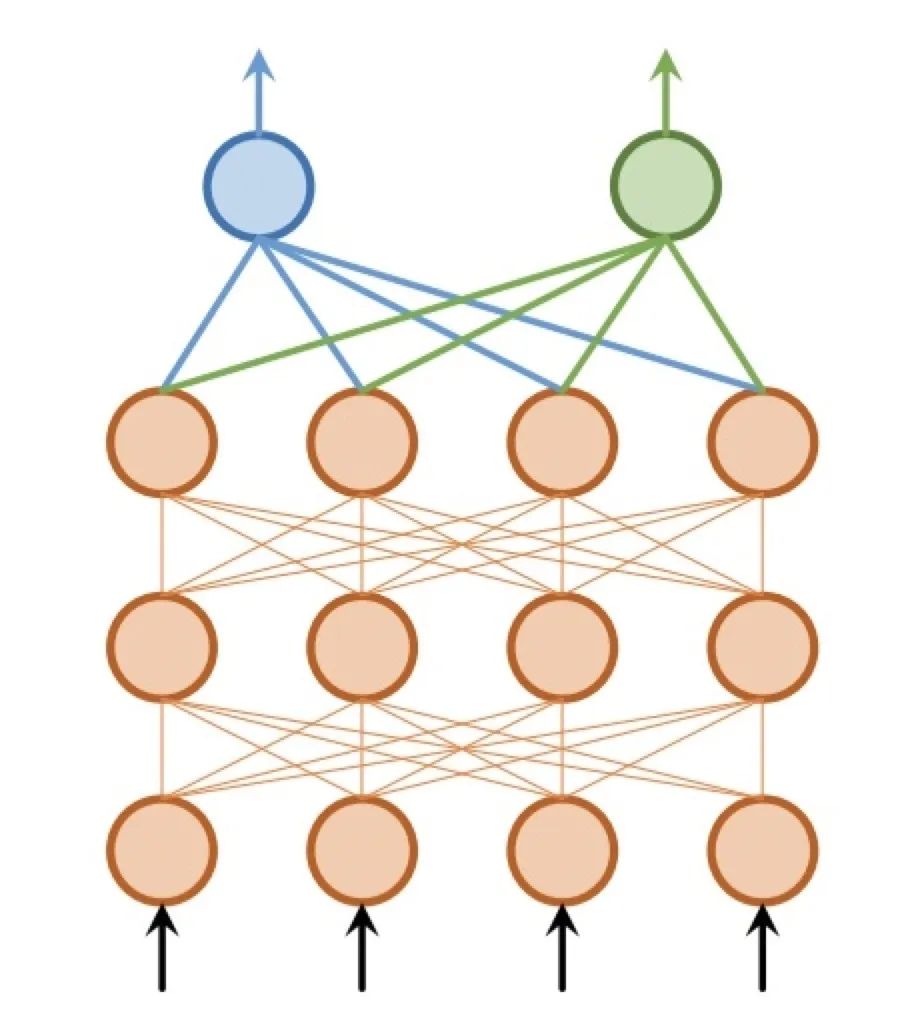
参数的硬共享机制是神经网络的多任务学习中最常见的一种方式,一般来讲,它可以应用到所有任务的所有隐层上,而保留任务相关的输出层。硬共享机制降低了过拟合的风险。Baxter[1]证明了这些共享参数过拟合风险的阶数是N,其中N为任务的数量,比非共享网络参数的过拟合风险要小。一般来说,硬共享机制在相似度较高的问题中具有良好的结果,但遇到弱相关任务时常常表现很差。
软共享
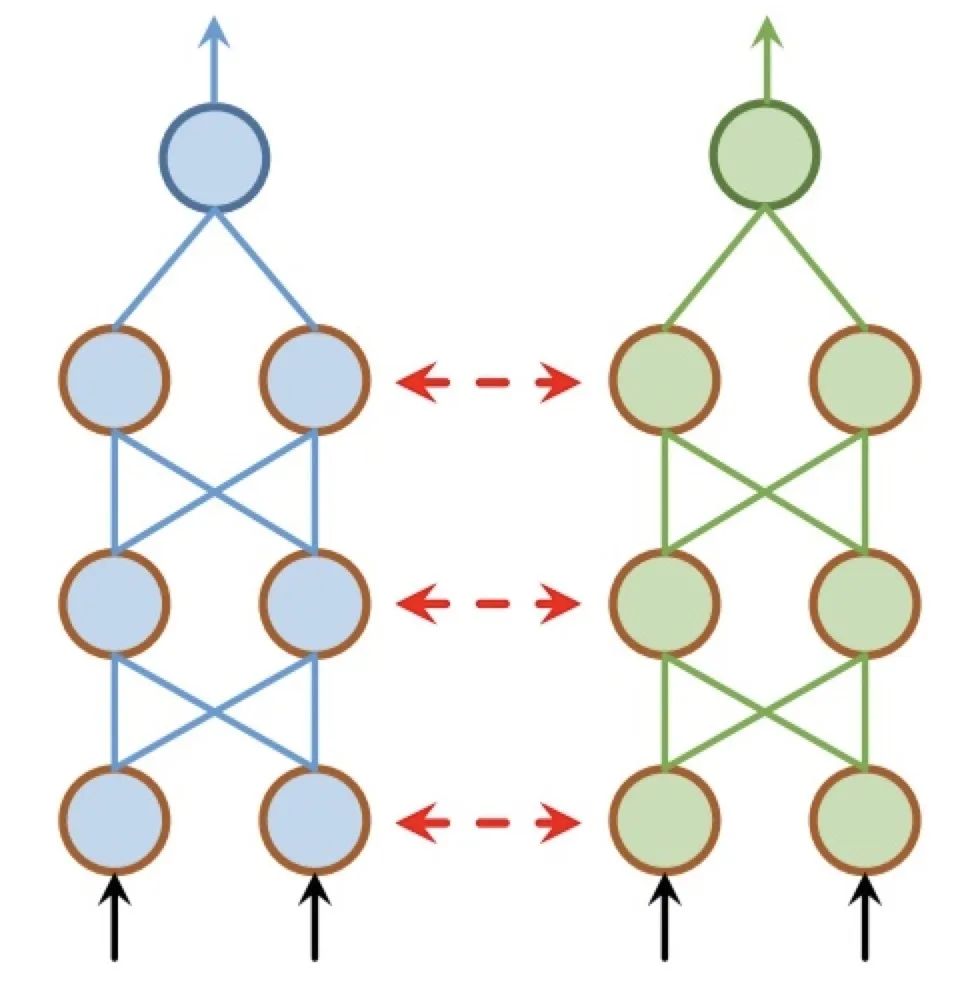
每个任务都有自己的模型与参数。通常对模型参数的距离进行正则化来保障参数的相似。Duong[2]使用L2距离正则化,而Yang[3]使用迹正则化(trace norm)。用于深度神经网络中软共享机制的约束很大程度上是受传统多任务学习中正则化技术的影响。软共享机制的特点是每个任务并没有共享任何参数,只是保证参数之间的相似度。软共享机制非常灵活,不需要对任务相关性做任何假设,但是,由于为每个任务分配一个网络,常常需要增加很多参数。
分层共享
由于神经网络在前层提取到低维特征(如形状、纹理),而后层提取高维特征(模式、姿态),分层共享机制根据这一点,提出了一种基于层级之间的网络共享机制。这种机制是在网络的低层做较简单的任务,在高层做较困难的任务。分层共享比硬共享要更灵活,同时所需的参数又比软共享少,但是为多个任务设计高效的分层结构依赖专家经验。

稀疏共享
稀疏共享是2020年复旦大学邱锡鹏团队[4]在AAAI 2020上录用的论文中提出的方法,这是一种最新的参数共享机制,能够同时解决软共享、硬共享与分层共享的问题。稀疏共享可以为每个任务从基网络中抽取出一个对应的子网络来处理该任务,这些子网络部分重叠,算法可以为强相关的任务抽取出相似的子网络(具有较高的参数重叠率),为弱相关的任务抽取出差异较大的子网络(具有较低的参数重叠率)。得到这些子网络后,再使用多个任务的数据联合训练。

论文中还提出了一种训练的模式,以适应不同任务的训练。
1)随机挑选一个任务t;
2)为任务t随机采样一个batch数据;
3)将该batch数据输入到任务t对应的子网络中;
4)使用该batch数据的梯度更新子网络的参数;
5)回到 1)。
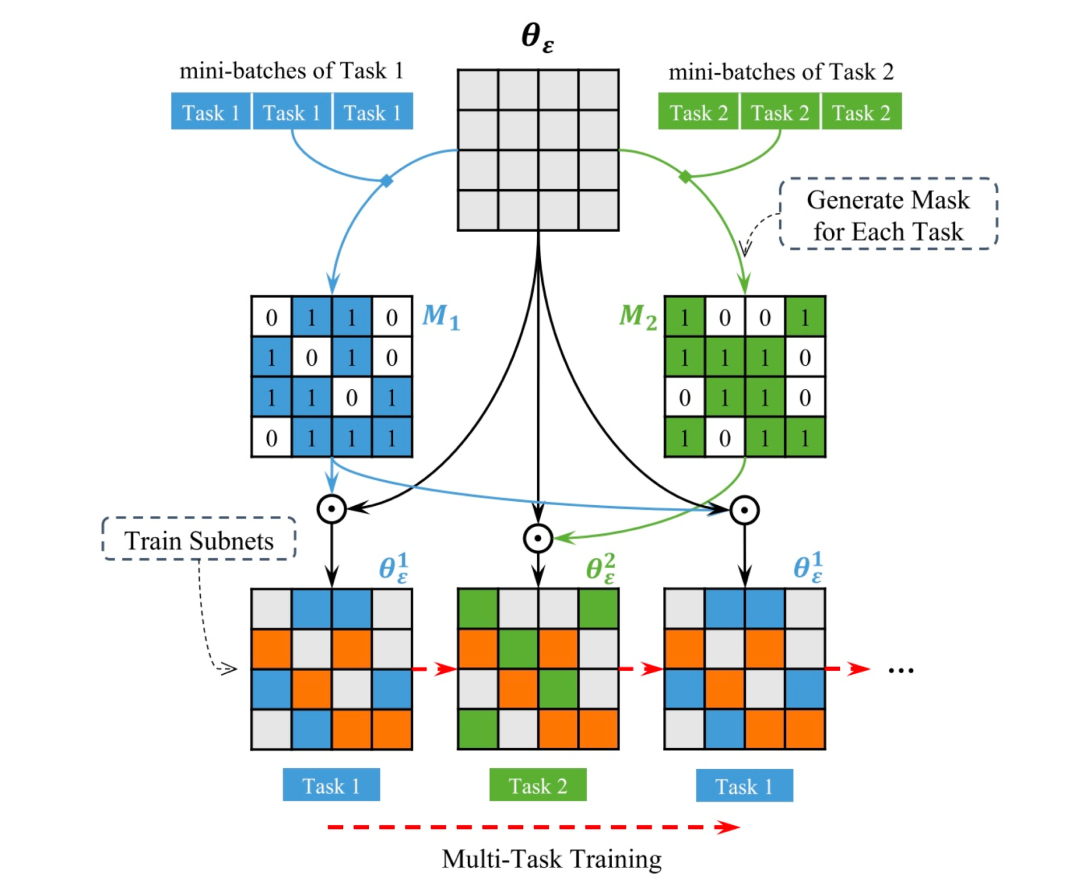
这种训练方式有效规避了损失函数的设计问题,同时可以用自适应的方式进行多任务协作训练。在三个序列标注任务(POS tagging、NER、Chunking)上进行了实验,结果表明稀疏共享超越了单任务学习、硬共享、软共享和分层共享的效果,同时所需参数量最少。
损失函数的设置方式
在多任务学习的训练中,除了上文介绍的“串行式”训练方法外,还有一种“并行化”的训练方式,也就是说同时对多个任务进行训练,那么就需要设计一个损失函数来同时考虑多种任务的损失,常见的做法是对不同的任务进行加权,但是任务之间的难度并不会完全相同,这样的训练后果是让神经网络很快的学习到更简单的任务而选择性放弃相对困难的任务,仿佛是在“偷懒”。为了避免这种情况发生,Alex[5]提出了一种基于任务的不确定性构建损失函数的方法。考虑每个任务之间的同方差不确定性(homoscedastic uncertainty)来设置不同任务损失函数的权值,建立多个任务的极大似然函数优化多任务的概率模型,得到在两个任务的损失函数:

将该方法应用于深度回归,语义和实例分割,实验结果表明,这种多任务统一的损失函数训练优于每一个模型任务单独训练的效果。
损失函数的设置方式
多任务学习可以被认为是一种将先验信息融入网络的做法,在多个任务互相有关联的时候往往可以使用。举例来说,在计算机视觉领域中,可以同时对目标检测、图像分类等任务进行学习,在合理的结构下,目标检测可以提供目标物体的位置信息,而图像分类提供类别信息,很多物体出现的位置是相关的,例如太阳出现在天空中,所以可以预见这些任务是可以进行相互促进的;而在自然语言处理中,命名实体识别与Q&A问答也是密不可分的上下游任务,通过合理的结构组合,有望让这两个分属于基础的上游任务和偏向于应用的下游任务进行合并提高。
总结
尽管多任务学习被频繁使用,但是近20年来,参数硬共享机制仍旧是神经网络中多任务学习的主要范式。探索学习共享哪些信息的工作看起来更具前景。同时,我们对于任务的相似性、任务间的关系、任务的层次以及多任务学习的收益等理解仍旧是有限的,我们需要更多的研究以进一步理解深度神经网络中多任务学习的泛化能力。
参考文献
[1] Baxter, J. 1997. A Bayesian / Information Theoretic Model of Learning to Learn via Multiple Task Sampling. Machine Learning. 28, 7-39.
[2] Duong, L., Cohn. et.al. 2015. Low Resource Dependency Parsing Cross-Lingual Parameter Sharing in a Neural Network Parser. ACL2015.
[3] Yang, Y. et. al. 2017. Trace Norm Regularized Deep Multi-Task Learning. ICLR2017 workshop.
[4] Tian S. et. Al. 2019. Learning Sparse Sharing Architectures for Multiple Tasks. https://arxiv.org/abs/1911.05034
[5] Alex K., Yarin G. 2018.Roberto C. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7482-7491
[6] Sebastian Ruder, 2017. An Overview of Multi-Task Learning in Deep Neural Networks. https://arxiv.org/abs/1706.05098


上海市计算机软件评测重点实验室(简称SSTL)由上海市科委批准成立于1997年,是全国最早开展信息系统质量与安全测评的第三方专业机构之一,隶属于上海计算机软件技术开发中心。
扫码关注:上海市计算机软件评测重点实验室

觉得内容还不错的话,给我点个“在看”呗
我知道你在看哟

