




在 HBase 中,数据以 KV 形式存储,只能提供点查能力,不具备复杂的统计分析能力; 无法使用 Bitmap 相关技术,需要将需要的指标事先计算出来,方式不够灵活,不能做集合操作; 流程链路较长,维护复杂度高,不具备模型抽象能力,业务升级有所不便。
针对数据存储层的问题与挑战,我们着力于寻找一款高性能,简单易维护的数据库产品来替换已有的 Spark + HBase 架构,同时也希望在业务层上能突破 Hbase 点查的限制,通过实时多表关联的方式拓展业务层的需求。
目前市面上的 OLAP 数据库产品百花齐放,诸如 Impala、Druid、ClickHouse 及 StarRocks。在经过一系列的对比之后,StarRocks 高效的读写性能在众多产品中脱颖而出。同时,高度活跃的社区生态给开发者与用户带来了良好的开发与使用体验,所以我们选择了 StarRocks 来作为 华米的 OLAP 引擎,替换原有的 HBase 成为存储层的新选择。
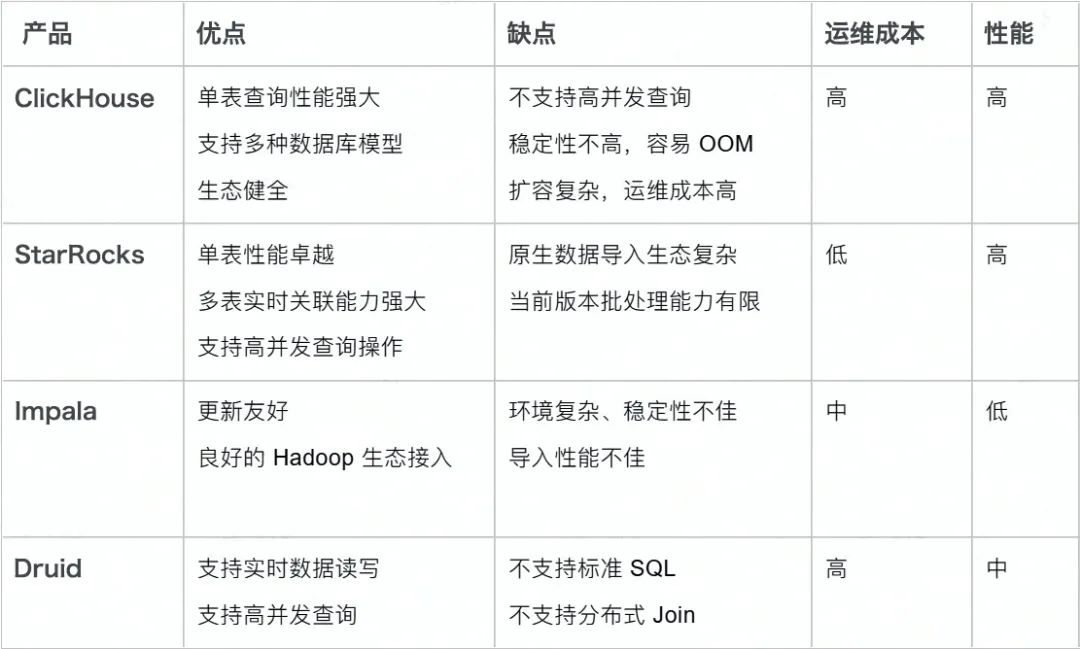
从上面的对比可以看出,StarRocks 是一款极速全场景 MPP 企业级数据库产品,具备水平在线扩缩容、金融级高可用,兼容 MySQL 协议和 MySQL 生态,提供全面向量化引擎与多种数据源联邦查询等重要特性,在全场景 OLAP 业务上提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。
当前产线埋点数据主要来源于 App 以及固件上传的埋点数据,数据经由网关转入 Kafka,采用 Hudi on Flink 的模式进行数据清洗、过滤、转换,基于流式数据湖构建 OLAP 的预处理层。根据数据特性和写入的性能要求,分别基于 Hudi 的 Upsert 和 Append 模式构建 DWD 层(借助 Hudi 的去重、追加能力),定时离线处理数据转入 DWS,考虑数仓的整体架构以及成本优化,将 DWS 数据定时离线导入到 StarRocks 中。最后经由 ZDS(Zepp Data Studio,华米大数据统一查询平台)查询 StarRocks 数据。
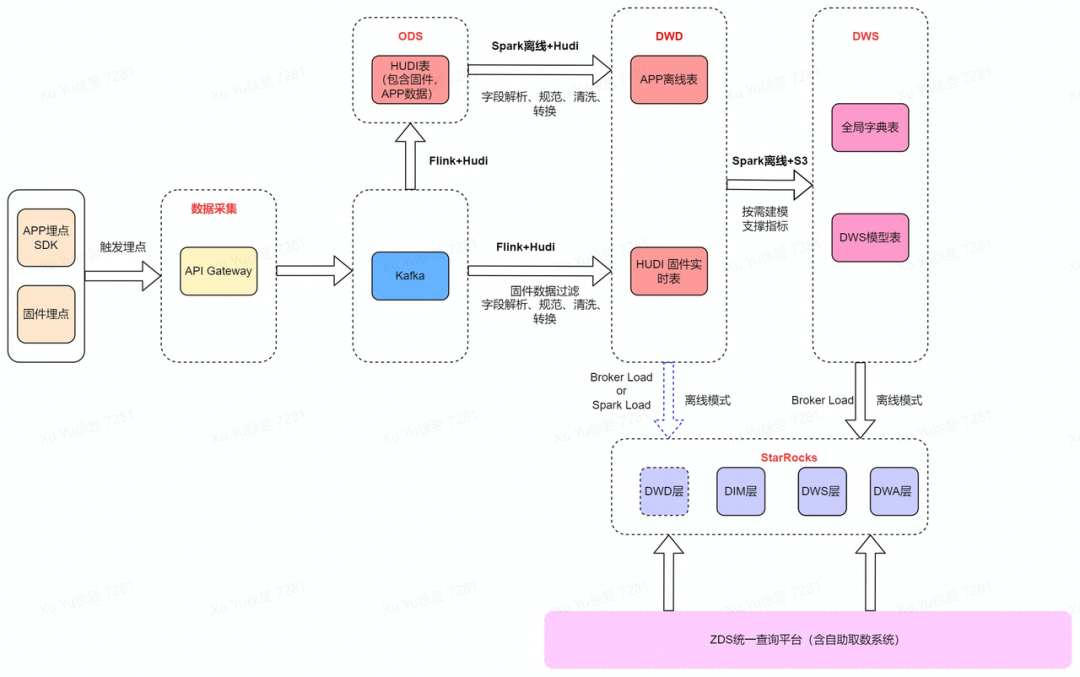
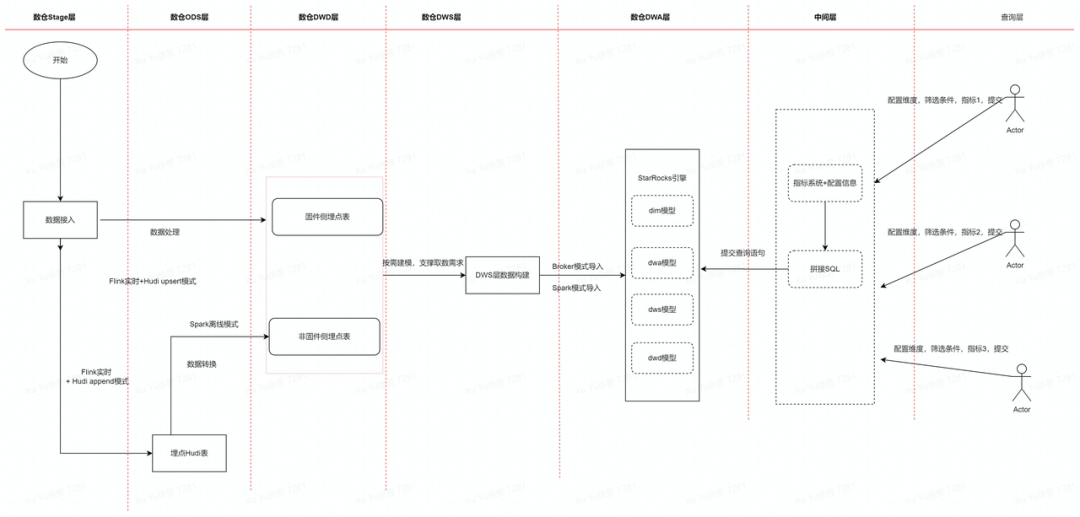
详细流程如下:
4. 用户根据大数据统一查询平台进行自助业务指标查询。
灵活:满足多维度、多时间段自由组合的指标统计分析,不需要提前计算冗余统计指标。
节约空间:StarRocks自身的高效存储结构,同等业务量的数据存储成本较以往下降 20%。
简单:相较于 ClickHouse,维护管理所需的人力成本有所降低。
便捷:用户自助查询便捷,取数体验有所提升,部分指标点查速度从之前的分钟级降低到秒级,部分指标可以达到毫秒级。
开放活跃的社区环境也是我们产品选型的一个重要的指标,作为用户,开放的社区可以更快捷高效的帮助我们了解产品的特性,处理产品使用中的问题。同时,作为一个大数据技术从业者,我们也愿意参与到开源社区的共建之中,希望通过我们的努力回馈开源社区,共同进步。华米计算框架部在使用过程中对 StarRocks 做出以下改进,并合入社区主分支:
修复发现的 StarRocks 建立物化视图过程中的 Bug
支持更多 StarRocks 数据导入的对象存储类型
丰富特定数据导入场景下的参数配置
当前生成 Bitmap 需要将明细数据增量导入到聚合模型中,尚不能直接导入 Bitmap 字段的 Parquet 文件,在异构存储的场景下方式不够高效。华米计算框架部也正与 StarRocks 社区协同,关注及解决该问题,详见:https://github.com/StarRocks/starrocks/issues/3279
华米将进一步建立海外 OLAP 平台,推动 StarRocks 落地并服务于全球业务。
作者
任职于大数据及云平台计算框架部,主导/参与华米科技集成平台、元数据管理、数据门户 ZDS、OLAP 平台建设以及大数据基础设施性能优化等相关工作。
推 荐 案 例
如希望了解更多详情请关注我们!

