点击上方蓝字【囧囧妹】一起学习,一起成长!
一、开篇
前面我们聊了IO多路复用内核实现,linux的io多路复用技术主要有select、poll、epoll,这三种方式的选择要不同的场景、需求来进行选择。我们现在总结归纳一下。
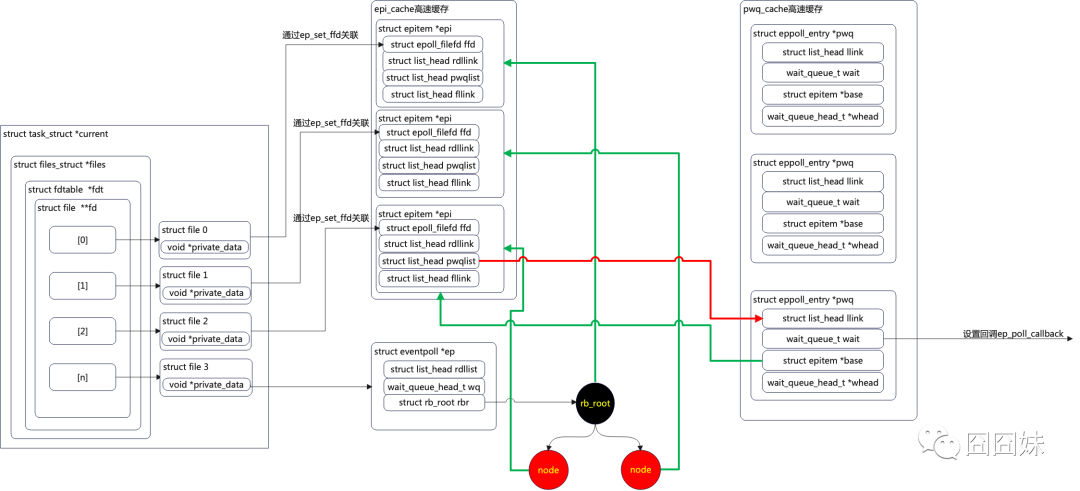
二、epoll结构图
先把上一节遗留的epoll数据结构放这,然后可以结合该结构再根据源码实现来理解理解epoll。
其实,早在1999年就有人提出了一个C10K的问题,这里C就是client的缩写,C10K就是单机同时处理1万个请求,当时服务器只有32位系统,运行着linux2.2版本,配置了很少的内存和千兆网。从物理资源来说,对于一个2G内存千兆网服务器,要同时处理1万个请求是足够的,每个请求占用200KB内存,带宽100Kbit,从资源角度讲是没问题的,但是在C10K以前,linux网络处理模型都采用同步阻塞,也就是为每一个请求分配一个进程或线程,这时当有1万个连接时进程或线程的上下文切换、内存都会成为瓶颈。于是就有人提出用IO多路复用技术来解决C10K问题。Ø 第一种方式,采用select或者poll,在一个线程或进程中所有监听的文件描述符,这样达到使用一个进程或线程来处理多个连接。select有1024个描述符的限制,同时select和poll又都是将用户态监听的文件描述符集合拷贝到内核态,内核态将监听的文件描述符状态修改后再拷贝回用户态进行处理,处理完后,用户程序要重新将需要监听的文件描述符再次加入select或poll,这一系列拷贝都是时间和内存的成本,在poll源码中我们还看见poll自身的设计是在栈上分配32个描述符监听,如果再增加监听描述符,poll会从堆上进行分配,这样虽然避免了1024的限制,但是内存分配会非常损耗性能,但是采用select也有一定好处就是开发简单,跨平台容易,windows、linux、mac都是支持select的。Ø 第二种方式,采用epoll,epoll不需要遍历所有描述符,通过红黑树在内核管理监听的文件描述符集合,而且只用添加一次,不需要来回拷贝所有的文件描述符,内核只把就绪链表上的节点拷贝到用户态,虽然这样解决了第一种方案的问题,但是epoll的开发难度比较大,需要对epoll有一定的深入理解,特别是网络环境中涉及的一些异常处理,比如对端正常关闭异常关闭触发的事件处理。虽然也有些不足,但是这两种方式都很轻松地解决了C10K问题。其实这个原理可以轻松地解决到C100K,遇到C1000K就不容易解决了。还是先从物理资源来说,2G内存肯定不够的,千兆网带宽每个请求分配1Kbit这也是不够的,对于协议栈缓存也会成为大问题,大量连接可能会把缓存直接干崩溃。所以面对C1000K就要升级硬件了,同时还要对软件做更深度的优化,比如优化数据链路、异步io等。再往上呢?C10M问题我们就要通过了解内核协议栈,通过内核旁路的一些机制来解决,比如大家都知道的dpdk。Dpdk就会跳过内核协议栈,直接由用户态进程来处理网络数据。在之前我设计了一种PCIE的io虚拟化技术,也是跳过内核来由用户直接处理,这样在性能方面提升了不少,同时我们的容器数量也由原来的8个提升到了64个甚至更多。那么,epoll总比select/poll高效吗?Ø 前面我们通过源码实现可以发现,epoll在内核态维护一颗红黑树和非常多的等待队列、链表,这在资源消耗上是比较大的,如果监听的数量不多,那对于底层是消耗比较大的。Ø 通过源码我们还发现epoll中注册了回调,一旦有事件触发就会调用回调并将该fd结构挂载到就绪链表,那么如果活跃的数量太多了,那这一层层的回调,将入就绪链表,这对服务器的消耗还是比较大的。所以,当连接量相对小的时候我们可以选用select来处理,开发难度低,性能损耗内存占用也不是很大,如果连接量比较大,我们最好选用epoll来解决,如果此时活跃量也很大,epoll可能就不是很好的解决方式了。http://www.xmailserver.org/linux-patches/nio-improve.html总结,我们前面了解了字符设备驱动、同步与锁机制、io多路复用,那么我们就可以构建一套通过字符设备来进行用户态进程间通信的机制我们暂且命名为msg-channel,这个机制接下来几节我们可以一起来实现一下。觉得不错,点击“分享”,“赞”,“在看”传播给更多热爱嵌入式的小伙伴吧!