





前言
天津南大通用数据技术股份有限公司(GBASE)是国产数据库领军企业,从2004年成立之日起一直坚持国产数据库的研发和推广。专注于数据库软件产品和服务,致力于成为用户最信赖的数据库产品供应商。南大通用GBase连续两年进入Gartner DMSA分析型数据管理解决方案的魔力象限、连续六年被评为“国产数据库第一品牌”、在墨天轮中国数据库流行度排行榜一直名列前茅。
GBase 8a 是南大通用公司面向海量数据分析型应用领域,自主研发的一款高性能国产数据库产品。用于满足数据密集型行业日益增大的数据统计、数据挖掘、关联分析、即席查询和数据备份等需求,可用做数据仓库系统、BI系统和决策支持系统的承载数据库。
本文是笔者在学习南大通用GBase数据库技术的过程中,使用SSBM模型对GBase 8a进行测试和优化的实验报告。通过此实验,对GBase 8a有了更加深入的认知。也希望能以此抛砖引玉,让更多的人了解、学习和使用国产数据库。只有独立自主、自力自强,才不会让任何人卡脖子!支持国产库、愿国产数据库技术更加快速的发展和强大!
一.报告摘要信息
| 测试实验名称 | SSBM模型测试优化实验 |
|---|---|
| 测试时间 | 2021年1月30日 |
| 测试服务器环境 | 三台vmare虚拟机(内存2GB) |
| 服务器OS版本 | CentOS Linux release 7.9.2009 |
| GBase 8a版本 | 9.5.2.35.125594 |
二.测试模型说明
1.SSBM星型模型介绍
SSBM(Star Schema BenchMark),是麻省州立大学波士顿校区的研究人员定义的基于现实商业应用的数据模型。
它是业界公认用来模拟决策支持类应用的数据模型。学术界和工业界普遍采用它来评价决策支持技术应用的性能。
SSBM基准测试包括:
- 1个事实表:lineorder(订单明细表)
- 4个维度表:customer(客户信息表)、part(商品信息表)、dwdate(日期维度表)、supplier(供应商信息表)
- 13条标准SQL查询测试语句:统计查询、多表关联、sum、复杂条件、group by、order by等组合方式。
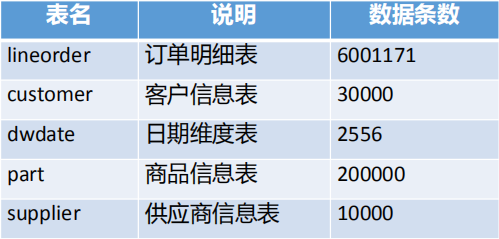
SSBM星形模型基准样例包括5张表,说明如下:
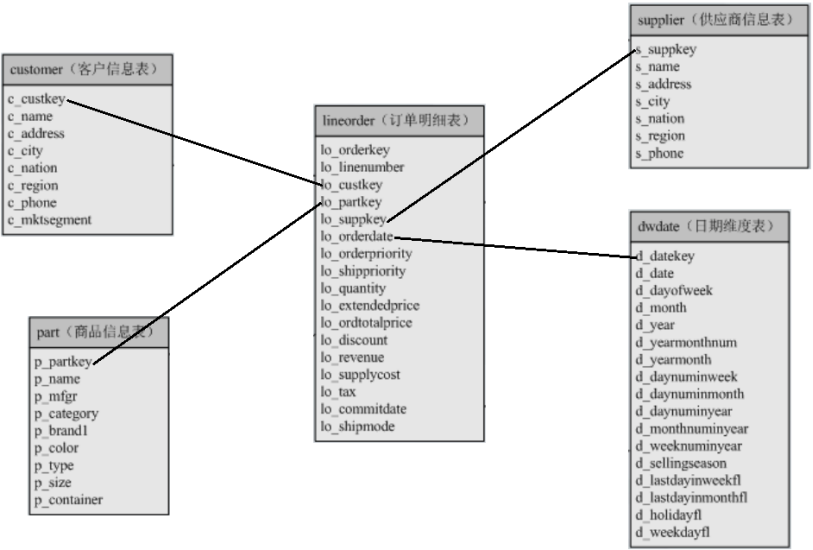
2.测试模型表的关系
测试模型五个表的E-R图如下:
三.测试所用的集群环境情况
本次测试所用的集群,由三个节点的vmware虚拟机组成,主机信息如下:
1.软件版本信息
OS版本:CentOS Linux release 7.9.2009 (3.10.0-1160.el7.x86_64)
GBase 8a集群版本:GBase8a_MPP (9.5.2.35.125594-x86_64)
2.集群节点状态
$ gcadmin
CLUSTER STATE: ACTIVE
================================================================
| GBASE COORDINATOR CLUSTER INFORMATION |
================================================================
| NodeName | IpAddress | gcware | gcluster | DataState |
----------------------------------------------------------------
| coordinator1 | 192.168.20.81 | OPEN | OPEN | 0 |
----------------------------------------------------------------
| coordinator2 | 192.168.20.82 | OPEN | OPEN | 0 |
----------------------------------------------------------------
==============================================================
| GBASE CLUSTER FREE DATA NODE INFORMATION |
==============================================================
| NodeName | IpAddress | gnode | syncserver | DataState |
--------------------------------------------------------------
| FreeNode1 | 192.168.20.81 | OPEN | OPEN | 0 |
--------------------------------------------------------------
| FreeNode2 | 192.168.20.82 | OPEN | OPEN | 0 |
--------------------------------------------------------------
| FreeNode3 | 192.168.20.83 | OPEN | OPEN | 0 |
--------------------------------------------------------------
0 virtual cluster
2 coordinator node
3 free data node
3.集群分布配置情况
$ cat /opt/gcinstall/gcChangeInfo.xml
<?xml version="1.0" encoding="utf-8"?>
<servers>
<rack>
<node ip="192.168.20.81"/>
<node ip="192.168.20.82"/>
<node ip="192.168.20.83"/>
</rack>
</servers>
$ gcadmin showdistribution node
Distribution ID: 1 | State: new | Total segment num: 6
==================================================================
| nodes | 192.168.20.81 | 192.168.20.82 | 192.168.20.83 |
------------------------------------------------------------------
| primary | 1 | 2 | 3 |
| segments | 4 | 5 | 6 |
------------------------------------------------------------------
|duplicate | 3 | 1 | 2 |
|segments 1| 5 | 6 | 4 |
==================================================================
四.测试实验步骤
1.上传并解压测试数据包
以gbase用户向GBase 8a MPP集群的一个节点上传测试数据包,然后解压,执行过程如下:
[gbase@gb8a1 ~]$ pwd
/home/gbase
[gbase@gb8a1 ~]$ ll
-rw-r--r-- 1 gbase gbase 152951 Jan 30 21:34 SSB.zip
[gbase@gb8a1 ~]$ unzip SSB.zip
[gbase@gb8a1 ~]$ cd SSB
[gbase@gb8a1 SSB]$ tree
.
├── create_table.sql
├── data
│ ├── customer.tbl
│ ├── dbgen
│ ├── dbgen.sh
│ ├── dists.dss
│ ├── dwdate.tbl
│ ├── lineorder.tbl
│ ├── part.tbl
│ └── supplier.tbl
├── expect
├── README.txt
├── reject
├── result
├── run_ssb.sh
└── trace_sql
├── 10.sql
├── 11.sql
├── 12.sql
├── 13.sql
├── 1.sql
├── 2.sql
├── 3.sql
├── 4.sql
├── 5.sql
├── 6.sql
├── 7.sql
├── 8.sql
└── 9.sql
2.生成测试数据
执行过程如下:
$ cd SSB/data
[gbase@gb8a1 data]$ ll
-rw-rw-r-- 1 gbase gbase 144836 Sep 3 2012 dbgen
-rw-rw-r-- 1 gbase gbase 28 Dec 10 2012 dbgen.sh
-rw-rw-r-- 1 gbase gbase 11439 Sep 3 2012 dists.dss
[gbase@gb8a1 data]$ chmod a+x dbgen
[gbase@gb8a1 data]$ ./dbgen -s 1 -T a
done.
Generating data for customers table [pid: 3066]done.
Generating data for date table [pid: 3066]done.
Generating data for lineorder table [pid: 3066]done.
3.创建测试用数据库和表
(1)创建测试库
[gbase@gb8a1 SSB]$ gccli -uroot -p
gbase> CREATE DATABASE if not exists ssbm;
Query OK, 1 row affected (Elapsed: 00:00:00.06)
gbase> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| performance_schema |
| gbase |
| gctmpdb |
| empdb |
| gclusterdb |
| ssbm |
+--------------------+
7 rows in set (Elapsed: 00:00:00.00)
(2)创建测试表
gbase> use ssbm;
Query OK, 0 rows affected (Elapsed: 00:00:00.00)
gbase> source create_table.sql;
+------------------+
| STAGE |
+------------------+
| >>>DATABASE ssbm |
+------------------+
1 row in set (Elapsed: 00:00:00.00)
Query OK, 0 rows affected (Elapsed: 00:00:00.06)
Query OK, 1 row affected (Elapsed: 00:00:00.01)
Query OK, 0 rows affected (Elapsed: 00:00:00.00)
+--------------------------+
| >>>CREATETABLE lineorder |
+--------------------------+
| >>>CREATETABLE lineorder |
+--------------------------+
1 row in set (Elapsed: 00:00:00.00)
Query OK, 0 rows affected, 5 warnings (Elapsed: 00:00:00.15)
Query OK, 0 rows affected (Elapsed: 00:00:00.09)
+---------------------+
| STAGE |
+---------------------+
| >>>CREATETABLE part |
+---------------------+
1 row in set (Elapsed: 00:00:00.00)
Query OK, 0 rows affected, 5 warnings (Elapsed: 00:00:00.14)
Query OK, 0 rows affected (Elapsed: 00:00:00.09)
+-------------------------+
| STAGE |
+-------------------------+
| >>>CREATETABLE supplier |
+-------------------------+
1 row in set (Elapsed: 00:00:00.00)
Query OK, 0 rows affected, 5 warnings (Elapsed: 00:00:00.17)
Query OK, 0 rows affected (Elapsed: 00:00:00.11)
+-------------------------+
| STAGE |
+-------------------------+
| >>>CREATETABLE customer |
+-------------------------+
1 row in set (Elapsed: 00:00:00.00)
Query OK, 0 rows affected, 5 warnings (Elapsed: 00:00:00.09)
Query OK, 0 rows affected (Elapsed: 00:00:00.09)
+-----------------------+
| STAGE |
+-----------------------+
| >>>CREATETABLE dwdate |
+-----------------------+
1 row in set (Elapsed: 00:00:00.00)
Query OK, 0 rows affected, 5 warnings (Elapsed: 00:00:00.10)
Query OK, 0 rows affected (Elapsed: 00:00:00.08)
gbase> show tables;
+----------------+
| Tables_in_ssbm |
+----------------+
| customer |
| dwdate |
| lineorder |
| part |
| supplier |
+----------------+
5 rows in set (Elapsed: 00:00:00.00)
4.向表中加载测试数据
gbase> load data infile 'file:///home/gbase/SSB/data/lineorder.tbl' into table ssbm.lineorder fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 6001171 rows affected (Elapsed: 00:00:22.88)
Task 2062 finished, Loaded 6001171 records, Skipped 0 records, Ignored 2 files
gbase> load data infile 'file:///home/gbase/SSB/data/customer.tbl' into table ssbm.customer fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 30000 rows affected (Elapsed: 00:00:00.26)
Task 2063 finished, Loaded 30000 records, Skipped 0 records, Ignored 2 files
gbase> load data infile 'file:///home/gbase/SSB/data/part.tbl' into table ssbm.part fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 200000 rows affected (Elapsed: 00:00:00.88)
Task 2064 finished, Loaded 200000 records, Skipped 0 records, Ignored 2 files
gbase> load data infile 'file:///home/gbase/SSB/data/dwdate.tbl' into table ssbm.dwdate fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 2556 rows affected (Elapsed: 00:00:00.21)
Task 2065 finished, Loaded 2556 records, Skipped 0 records, Ignored 2 files
gbase> load data infile 'file:///home/gbase/SSB/data/supplier.tbl' into table ssbm.supplier fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 10000 rows affected (Elapsed: 00:00:00.16)
Task 2066 finished, Loaded 10000 records, Skipped 0 records, Ignored 2 files
5.执行查询,并统计每个语句的执行时间
(1)开启profiling开关
gbase> set profiling=1;
Query OK, 0 rows affected (Elapsed: 00:00:00.00)
(2)依次执行SQL脚本中的查询语句
(3)查看各语句的执行时间(单位:秒)
gbase> show profiles;
+----------+------------+--------+
| Query_ID | Duration | Query |
+----------+------------+--------+
| 1 | 0.20017300 | 1.sql |
| 2 | 0.16444700 | 2.sql |
| 3 | 0.18299825 | 3.sql |
| 4 | 0.84623800 | 4.sql |
| 5 | 0.78854600 | 5.sql |
| 6 | 0.71789925 | 6.sql |
| 7 | 1.18140550 | 7.sql |
| 8 | 1.01282575 | 8.sql |
| 9 | 1.04080775 | 9.sql |
| 10 | 0.36127600 | 10.sql |
| 11 | 0.89675300 | 11.sql |
| 12 | 0.79826625 | 12.sql |
| 13 | 0.73748850 | 13.sql |
+----------+------------+--------+
13 rows in set (Elapsed: 00:00:00.00)
6.将每个SQL脚本的执行结果记录到文件中保存
[gbase@gb8a1 SSB]$ for i in `seq 1 13`
do
gccli -uroot -Dssbm < ./trace_sql/${i}.sql > ./expect/${i}.sql.result 2>&1
done
7.分析查询语句,优化表类型
(1)测试用数据表的类型
通过查看建表脚本create_table.sql可知:五个测试表,均采用默认的建表方式,即“随机分布表”。
(2)集群的分布配置情况
之前已经对GBase 8a MPP集群做过distribution配置,配置文件内容如下:
$ cat /opt/gcinstall/gcChangeInfo.xml
<?xml version="1.0" encoding="utf-8"?>
<servers>
<rack>
<node ip="192.168.20.81"/>
<node ip="192.168.20.82"/>
<node ip="192.168.20.83"/>
</rack>
</servers>
并做了集群的分片设置,命令如下:
$ cd /opt/gcinstall/
$ gcadmin distribution gcChangeInfo.xml p 2 d 1 pattern 1
gcadmin generate distribution ...
NOTE: node [192.168.20.81] is coordinator node, it shall be data node too
NOTE: node [192.168.20.82] is coordinator node, it shall be data node too
gcadmin generate distribution successful
以上命令参数说明:
p: 每个数据节点存放的分片数量,必须小于每个rack内的节点数。
d:每个分片的备份数量,取值为0,1 或2。默认为1。
pattern :(缺省为1) 指明distribution 使用模式,1为负载均衡,2为高可用。
当前集群节点状态如下:
$ gcadmin showdistribution node
Distribution ID: 1 | State: new | Total segment num: 6
==================================================================
| nodes | 192.168.20.81 | 192.168.20.82 | 192.168.20.83 |
------------------------------------------------------------------
| primary | 1 | 2 | 3 |
| segments | 4 | 5 | 6 |
------------------------------------------------------------------
|duplicate | 3 | 1 | 2 |
|segments 1| 5 | 6 | 4 |
==================================================================
通过查询每个节点的表的分布情况,也可以验证以上的分布情况:
在三个节点主机上执行:
cd /opt/gnode/userdata/gbase/ssbm/sys_tablespace
ls -1
结果如下:
| 节点1 | 节点2 | 节点3 |
|---|---|---|
| customer_n1 | customer_n1 | customer_n2 |
| customer_n3 | customer_n2 | customer_n3 |
| customer_n4 | customer_n5 | customer_n4 |
| customer_n5 | customer_n6 | customer_n6 |
| dwdate_n1 | dwdate_n1 | dwdate_n2 |
| dwdate_n3 | dwdate_n2 | dwdate_n3 |
| dwdate_n4 | dwdate_n5 | dwdate_n4 |
| dwdate_n5 | dwdate_n6 | dwdate_n6 |
| lineorder_n1 | lineorder_n1 | lineorder_n2 |
| lineorder_n3 | lineorder_n2 | lineorder_n3 |
| lineorder_n4 | lineorder_n5 | lineorder_n4 |
| lineorder_n5 | lineorder_n6 | lineorder_n6 |
| part_n1 | part_n1 | part_n2 |
| part_n3 | part_n2 | part_n3 |
| part_n4 | part_n5 | part_n4 |
| part_n5 | part_n6 | part_n6 |
| supplier_n1 | supplier_n1 | supplier_n2 |
| supplier_n3 | supplier_n2 | supplier_n3 |
| supplier_n4 | supplier_n5 | supplier_n4 |
| supplier_n5 | supplier_n6 | supplier_n6 |
通过以上表分布情况可以看出,完全是按照集群的分布配置来分配到各节点的。
(3)分析每张表的情况
| 表名 | 说明 | 数据条数 | 主键 | 主键数据类型 |
|---|---|---|---|---|
| lindorder | 订单明细表 | 6001171 | lo_orderkey | bigint(20) |
| part | 商品信息表 | 200000 | p_partkey | bigint(20) |
| customer | 客户信息表 | 30000 | c_custkey | bigint(20) |
| supplier | 供应商信息表 | 10000 | s_suppkey | int(11) |
| dwdate | 日期维度表 | 2556 | d_datekey | int(11) |
(4)分析查询语句
①1.sql原来的查询计划为:
gbase> explain select sum(lo_extendedprice*lo_discount) as revenue from lineorder, dwdate where lo_orderdate = d_datekey and d_year = 1993 and lo_discount between 1 and 3 and lo_quantity < 25;
+----+-------------+-------------+----------------+-------------------------------+
| ID | MOTION | OPERATION | TABLE | CONDITION |
+----+-------------+-------------+----------------+-------------------------------+
| 02 | [RESULT] | Step | <01> | |
| | | AGG | | |
| 01 | [GATHER] | INNER JOIN | | (lo_orderdate = d_datekey) |
| | | Step | <00> | |
| | | SCAN | lineorder[DIS] | (lo_discount BETWEEN 1 AND 3) |
| | | | | (lo_quantity{S} < 25) |
| | | AGG | | |
| 00 | [BROADCAST] | SCAN | dwdate[DIS] | (d_year{S} = 1993) |
+----+-------------+-------------+----------------+-------------------------------+
dwate表只有2556行,是个小表,因此可以考虑将其以复制表的形式进行重建,操作如下:
gbase> drop table if exists dwdate;
Query OK, 0 rows affected (Elapsed: 00:00:00.10)
gbase> create table dwdate (
d_datekey int,
d_date varchar(18),
d_dayofweek varchar(9),
d_month varchar(9),
d_year int,
d_yearmonthnum int,
d_yearmonth varchar(7),
d_daynuminweek int,
d_daynuminmonth int,
d_daynuminyear int,
d_monthnuminyear int,
d_weeknuminyear int,
d_sellingseason varchar(12),
d_lastdayinweekfl int,
d_lastdayinmonthfl int,
d_holidayfl int,
d_weekdayfl int
) REPLICATED;
Query OK, 0 rows affected (Elapsed: 00:00:00.05)
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/dwdate.tbl' into table ssbm.dwdate fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 2556 rows affected (Elapsed: 00:00:00.07)
Task 3075 finished, Loaded 2556 records, Skipped 0 records, Ignored 0 files
②再次查看执行计划:
gbase> explain select sum(lo_extendedprice*lo_discount) as revenue from lineorder, dwdate where lo_orderdate = d_datekey and d_year = 1993 and lo_discount between 1 and 3 and lo_quantity < 25;
+----+----------+-------------+----------------+-------------------------------+
| ID | MOTION | OPERATION | TABLE | CONDITION |
+----+----------+-------------+----------------+-------------------------------+
| 01 | [RESULT] | Step | <00> | |
| | | AGG | | |
| 00 | [GATHER] | INNER JOIN | | (lo_orderdate = d_datekey) |
| | | SCAN | lineorder[DIS] | (lo_discount BETWEEN 1 AND 3) |
| | | | | (lo_quantity{S} < 25) |
| | | SCAN | dwdate[REP] | (d_year{S} = 1993) |
| | | AGG | | |
+----+----------+-------------+----------------+-------------------------------+
可以看到执行计划已经发现了变化。
③再次执行1~3.sql
可以看到执行速度已经大大加快,以下是执行时间比较:
| 原来的执行时间(秒) | 优化后的执行时间(秒) | 加快倍数 | |
|---|---|---|---|
| 1.sql | 0.200173 | 0.071464 | 2.8 |
| 2.sql | 0.164447 | 0.03577425 | 4.6 |
| 3.sql | 0.18299825 | 0.0370655 | 4.9 |
④分析4.sql
此查询涉及到两张大表(lineorder、part)和两张小表(dwdate、supplier),
先来看原来的查询执行计划:
gbase> explain select sum(lo_revenue), d_year, p_brand1 from lineorder, dwdate, part, supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_category = 'MFGR#12' and s_region = 'AMERICA' group by d_year, p_brand1 order by d_year, p_brand1;
+----+------------------+---------------+----------------+-----------------------------------+
| ID | MOTION | OPERATION | TABLE | CONDITION |
+----+------------------+---------------+----------------+-----------------------------------+
| 04 | [RESULT] | Step | <03> | |
| | | ORDER | | ORDER BY d_year ASC, p_brand1 ASC |
| 03 | [GATHER] | Step | <02> | |
| | | GROUP | | GROUP BY d_year, p_brand1 |
| 02 | [REDIST(d_year)] | INNER JOIN | | (lo_partkey = p_partkey) |
| | | INNER JOIN | | (lo_suppkey = s_suppkey) |
| | | Step | <00> | |
| | | INNER JOIN | | (lo_orderdate = d_datekey) |
| | | Table | lineorder[DIS] | |
| | | Table | dwdate[REP] | |
| | | Step | <01> | |
| | | GROUP | | GROUP BY d_year, p_brand1 |
| 01 | [BROADCAST] | SCAN | part[DIS] | (p_category{S} = 'MFGR#12') |
| 00 | [BROADCAST] | SCAN | supplier[DIS] | (s_region{S} = 'AMERICA') |
+----+------------------+---------------+----------------+-----------------------------------+
⑤调整两个大表(lineorder、part)为hash分布表,并将两张小表(dwdate、supplier)重建为复制表:
gbase> drop table if exists lineorder;
Query OK, 0 rows affected (Elapsed: 00:00:00.05)
gbase> create table lineorder (
lo_orderkey bigint,
lo_linenumber int,
lo_custkey int,
lo_partkey int,
lo_suppkey int,
lo_orderdate int,
lo_orderpriority varchar(15) comment 'lookup',
lo_shippriority varchar(1) comment 'lookup',
lo_quantity int,
lo_extendedprice int,
lo_ordtotalprice int,
lo_discount int,
lo_revenue int,
lo_supplycost int,
lo_tax int,
lo_commitdate int,
lo_shipmode varchar(10) comment 'lookup'
) DISTRIBUTED BY('lo_partkey');
Query OK, 0 rows affected (Elapsed: 00:00:00.06)
gbase> drop table if exists part;
Query OK, 0 rows affected (Elapsed: 00:00:00.05)
gbase> create table part (
p_partkey bigint,
p_name varchar(22),
p_mfgr varchar(6) comment 'lookup',
p_category varchar(7) comment 'lookup',
p_brand1 varchar(9) comment 'lookup',
p_color varchar(11) comment 'lookup',
p_type varchar(25) comment 'lookup',
p_size int,
p_container varchar(15) comment 'lookup'
) DISTRIBUTED BY('p_partkey');
Query OK, 0 rows affected (Elapsed: 00:00:00.06)
gbase> drop table if exists supplier;
Query OK, 0 rows affected (Elapsed: 00:00:00.06)
gbase> create table supplier (
s_suppkey int,
s_name varchar(25),
s_address varchar(25),
s_city varchar(10) comment 'lookup',
s_nation varchar(15) comment 'lookup',
s_region varchar(12) comment 'lookup',
s_phone varchar(15)
) REPLICATED;
Query OK, 0 rows affected (Elapsed: 00:00:00.04)
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/lineorder.tbl' into table ssbm.lineorder fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 6001171 rows affected (Elapsed: 00:00:24.51)
Task 3080 finished, Loaded 6001171 records, Skipped 0 records, Ignored 0 files
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/part.tbl' into table ssbm.part fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 200000 rows affected (Elapsed: 00:00:00.88)
Task 3081 finished, Loaded 200000 records, Skipped 0 records, Ignored 0 files
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/supplier.tbl' into table ssbm.supplier fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 10000 rows affected (Elapsed: 00:00:00.10)
Task 3084 finished, Loaded 10000 records, Skipped 0 records, Ignored 0 files
⑥重新查看4.sql的执行计划:
gbase> explain select sum(lo_revenue), d_year, p_brand1 from lineorder, dwdate, part, supplier where lo_orderdate = d_datekey and lo_partkey = p_partkey and lo_suppkey = s_suppkey and p_category = 'MFGR#12' and s_region = 'AMERICA' group by d_year, p_brand1 order by d_year, p_brand1;
+----+------------------+---------------+-----------------------+-----------------------------------+
| ID | MOTION | OPERATION | TABLE | CONDITION |
+----+------------------+---------------+-----------------------+-----------------------------------+
| 02 | [RESULT] | Step | <01> | |
| | | ORDER | | ORDER BY d_year ASC, p_brand1 ASC |
| 01 | [GATHER] | Step | <00> | |
| | | GROUP | | GROUP BY d_year, p_brand1 |
| 00 | [REDIST(d_year)] | INNER JOIN | | (lo_suppkey = s_suppkey) |
| | | INNER JOIN | | (lo_orderdate = d_datekey) |
| | | INNER JOIN | | (lo_partkey = p_partkey) |
| | | SCAN | part[p_partkey] | (p_category{S} = 'MFGR#12') |
| | | Table | lineorder[lo_partkey] | |
| | | Table | dwdate[REP] | |
| | | SCAN | supplier[REP] | (s_region{S} = 'AMERICA') |
| | | GROUP | | GROUP BY d_year, p_brand1 |
+----+------------------+---------------+-----------------------+-----------------------------------+
⑦再次执行4~6.sql,与之前的查询时间进行比较:
| 原来的执行时间(秒) | 优化后的执行时间(秒) | 加快倍数 | |
|---|---|---|---|
| 4.sql | 0.846238 | 0.37130175 | 2.3 |
| 5.sql | 0.788546 | 0.31571525 | 2.5 |
| 6.sql | 0.71789925 | 0.3527365 | 2 |
⑧分析7.sql
将customer表进行hash分布重建:
gbase> drop table if exists customer;
Query OK, 0 rows affected (Elapsed: 00:00:00.06)
gbase> create table customer (
c_custkey bigint,
c_name varchar(25),
c_address varchar(25),
c_city varchar(10) comment 'lookup',
c_nation varchar(15) comment 'lookup',
c_region varchar(12) comment 'lookup',
c_phone varchar(15),
c_mktsegment varchar(10) comment 'lookup'
) DISTRIBUTED BY('c_custkey');
Query OK, 0 rows affected (Elapsed: 00:00:00.04)
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/customer.tbl' into table ssbm.customer fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 30000 rows affected (Elapsed: 00:00:00.27)
Task 3090 finished, Loaded 30000 records, Skipped 0 records, Ignored 0 files
⑨再次执行7~10.sql,与之前的执行时间比较:
| 原来的执行时间(秒) | 优化后的执行时间(秒) | 加快倍数 | |
|---|---|---|---|
| 7.sql | 1.1814055 | 0.7007135 | 1.7 |
| 8.sql | 1.01282575 | 0.44106075 | 2.3 |
| 9.sql | 1.04080775 | 0.37610875 | 2.8 |
| 10.sql | 0.361276 | 0.204797 | 1.8 |
⑩再次执行11~13.sql,与之前的执行时间比较:
| 原来的执行时间(秒) | 优化后的执行时间(秒) | 加快倍数 | |
|---|---|---|---|
| 11.sql | 0.896753 | 0.770568 | 1.2 |
| 12.sql | 0.79826625 | 0.61401125 | 1.3 |
| 13.sql | 0.7374885 | 0.38420875 | 1.9 |
⑪优化前后的查询执行时间比较:
| 原来的执行时间(秒) | 优化后的执行时间(秒) | 加快倍数 | |
|---|---|---|---|
| 1.sql | 0.200173 | 0.071464 | 2.8 |
| 2.sql | 0.164447 | 0.03577425 | 4.6 |
| 3.sql | 0.18299825 | 0.0370655 | 4.9 |
| 4.sql | 0.846238 | 0.37130175 | 2.3 |
| 5.sql | 0.788546 | 0.31571525 | 2.5 |
| 6.sql | 0.71789925 | 0.3527365 | 2 |
| 7.sql | 1.1814055 | 0.7007135 | 1.7 |
| 8.sql | 1.01282575 | 0.44106075 | 2.3 |
| 9.sql | 1.04080775 | 0.37610875 | 2.8 |
| 10.sql | 0.361276 | 0.204797 | 1.8 |
| 11.sql | 0.896753 | 0.770568 | 1.2 |
| 12.sql | 0.79826625 | 0.61401125 | 1.3 |
| 13.sql | 0.7374885 | 0.38420875 | 1.9 |
8.修改表压缩方式,比较存储空间的变化
(1)查看压缩前的数据目录大小
在压缩表之前,通过du命令查看各节点ssbm目录的大小(KB),情况如下:
| 节点1 | 节点2 | 节点3 |
|---|---|---|
| 134036 | 134128 | 134240 |
(2)执行修改表命令
gbase> alter table lineorder COMPRESS(1,3);
Query OK, 0 rows affected (Elapsed: 00:00:00.11)
但是此方式经实验检验,发现并没有对已经有数据的表进行压缩。
(3)导出表的创建语句
gcdump -uroot -W vcname000001 -B ssbm
(4)根据导出的建表语句,采用压缩方式重建表
USE ssbm;
DROP TABLE IF EXISTS customer;
CREATE TABLE customer (
c_custkey bigint(20) DEFAULT NULL,
c_name varchar(25) DEFAULT NULL,
c_address varchar(25) DEFAULT NULL,
c_city varchar(10) DEFAULT NULL COMMENT 'lookup',
c_nation varchar(15) DEFAULT NULL COMMENT 'lookup',
c_region varchar(12) DEFAULT NULL COMMENT 'lookup',
c_phone varchar(15) DEFAULT NULL,
c_mktsegment varchar(10) DEFAULT NULL COMMENT 'lookup'
) COMPRESS(1, 3) ENGINE=EXPRESS DISTRIBUTED BY('c_custkey') DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace';
DROP TABLE IF EXISTS dwdate;
CREATE TABLE dwdate (
d_datekey int(11) DEFAULT NULL,
d_date varchar(18) DEFAULT NULL,
d_dayofweek varchar(9) DEFAULT NULL,
d_month varchar(9) DEFAULT NULL,
d_year int(11) DEFAULT NULL,
d_yearmonthnum int(11) DEFAULT NULL,
d_yearmonth varchar(7) DEFAULT NULL,
d_daynuminweek int(11) DEFAULT NULL,
d_daynuminmonth int(11) DEFAULT NULL,
d_daynuminyear int(11) DEFAULT NULL,
d_monthnuminyear int(11) DEFAULT NULL,
d_weeknuminyear int(11) DEFAULT NULL,
d_sellingseason varchar(12) DEFAULT NULL,
d_lastdayinweekfl int(11) DEFAULT NULL,
d_lastdayinmonthfl int(11) DEFAULT NULL,
d_holidayfl int(11) DEFAULT NULL,
d_weekdayfl int(11) DEFAULT NULL
) COMPRESS(1, 3) ENGINE=EXPRESS REPLICATED DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace';
DROP TABLE IF EXISTS lineorder;
CREATE TABLE lineorder (
lo_orderkey bigint(20) DEFAULT NULL,
lo_linenumber int(11) DEFAULT NULL,
lo_custkey int(11) DEFAULT NULL,
lo_partkey int(11) DEFAULT NULL,
lo_suppkey int(11) DEFAULT NULL,
lo_orderdate int(11) DEFAULT NULL,
lo_orderpriority varchar(15) DEFAULT NULL COMMENT 'lookup',
lo_shippriority varchar(1) DEFAULT NULL COMMENT 'lookup',
lo_quantity int(11) DEFAULT NULL,
lo_extendedprice int(11) DEFAULT NULL,
lo_ordtotalprice int(11) DEFAULT NULL,
lo_discount int(11) DEFAULT NULL,
lo_revenue int(11) DEFAULT NULL,
lo_supplycost int(11) DEFAULT NULL,
lo_tax int(11) DEFAULT NULL,
lo_commitdate int(11) DEFAULT NULL,
lo_shipmode varchar(10) DEFAULT NULL COMMENT 'lookup'
) COMPRESS(1, 3) ENGINE=EXPRESS DISTRIBUTED BY('lo_orderkey') DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace';
DROP TABLE IF EXISTS part;
CREATE TABLE part (
p_partkey bigint(20) DEFAULT NULL,
p_name varchar(22) DEFAULT NULL,
p_mfgr varchar(6) DEFAULT NULL COMMENT 'lookup',
p_category varchar(7) DEFAULT NULL COMMENT 'lookup',
p_brand1 varchar(9) DEFAULT NULL COMMENT 'lookup',
p_color varchar(11) DEFAULT NULL COMMENT 'lookup',
p_type varchar(25) DEFAULT NULL COMMENT 'lookup',
p_size int(11) DEFAULT NULL,
p_container varchar(15) DEFAULT NULL COMMENT 'lookup'
) COMPRESS(1, 3) ENGINE=EXPRESS DISTRIBUTED BY('p_partkey') DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace';
DROP TABLE IF EXISTS supplier;
CREATE TABLE supplier (
s_suppkey int(11) DEFAULT NULL,
s_name varchar(25) DEFAULT NULL,
s_address varchar(25) DEFAULT NULL,
s_city varchar(10) DEFAULT NULL COMMENT 'lookup',
s_nation varchar(15) DEFAULT NULL COMMENT 'lookup',
s_region varchar(12) DEFAULT NULL COMMENT 'lookup',
s_phone varchar(15) DEFAULT NULL
) COMPRESS(1, 3) ENGINE=EXPRESS REPLICATED DEFAULT CHARSET=utf8 TABLESPACE='sys_tablespace';
(5)重新导入表数据
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/lineorder.tbl' into table ssbm.lineorder fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 6001171 rows affected (Elapsed: 00:00:25.16)
Task 3108 finished, Loaded 6001171 records, Skipped 0 records, Ignored 0 files
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/part.tbl' into table ssbm.part fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 200000 rows affected (Elapsed: 00:00:00.95)
Task 3109 finished, Loaded 200000 records, Skipped 0 records, Ignored 0 files
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/supplier.tbl' into table ssbm.supplier fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 10000 rows affected (Elapsed: 00:00:00.11)
Task 3110 finished, Loaded 10000 records, Skipped 0 records, Ignored 0 files
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/customer.tbl' into table ssbm.customer fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 30000 rows affected (Elapsed: 00:00:00.35)
Task 3111 finished, Loaded 30000 records, Skipped 0 records, Ignored 0 files
gbase> load data infile 'file://192.168.20.81/home/gbase/SSB/data/dwdate.tbl' into table ssbm.dwdate fields terminated by '|' SKIP_BAD_FILE 1;
Query OK, 2556 rows affected (Elapsed: 00:00:00.06)
Task 3112 finished, Loaded 2556 records, Skipped 0 records, Ignored 0 files
(6)对比压缩前后的数据目录大小(KB)
| 节点1 | 节点2 | 节点3 | |
|---|---|---|---|
| 压缩前 | 134036 | 134128 | 134240 |
| 压缩后 | 94692 | 69604 | 69656 |
五.测试实验报告小结
通过本次测试优化实验,对GBase 8a MPP集群的搭建、配置,以及建库建表、数据加载、表结构导出、查询等进行了综合的实践。对所学习的GBase 8a MPP的相关知识点进行了一次较全面的回顾和复习。从理论向实践更进了一步。
同时,也发现了我在学习中的薄弱之处,例如:如何快速精准的分析执行计划并做出优化调整、如何检查集群的表数据是否出现倾斜?这些还需要后续不断的深入学习和实践。
