




点击上方蓝字关注我们
REC
点击观看视频
01

原理
1、概述
主要介绍以下几个方面:
流复制如何启动的
主备之间如何传送数据
主节点如何管理多个备节点
主节点如何发现失败的备节点
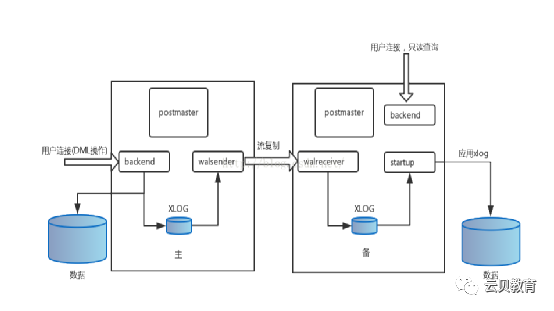
2、开始流复制
1.启动主节点和备节点
2.备节点启动startup进程
3.备节点启动walreceiver进程
4.walreceiver发送一个连接请求到主节点,如果主节点没有运行,walreceiver会周期性的发送请求
5.当主节点接受到一个连接的请求,就会启动一个walsender进程建立连接
6.walreceiver发送备节点最后的LSN,这个阶段在IT领域叫握手机制
7.如果备机点的LSN小于主节点的LSN,walsender发送wal数据,即从节点的LSN到主节点LSN的wal数据,wal数据由存储在主节点的pg_xlog(10版本以后叫pg_wal)目录下的wal segment提供,这个阶段就是备节点追赶主节点的阶段
8.流复制开始工作
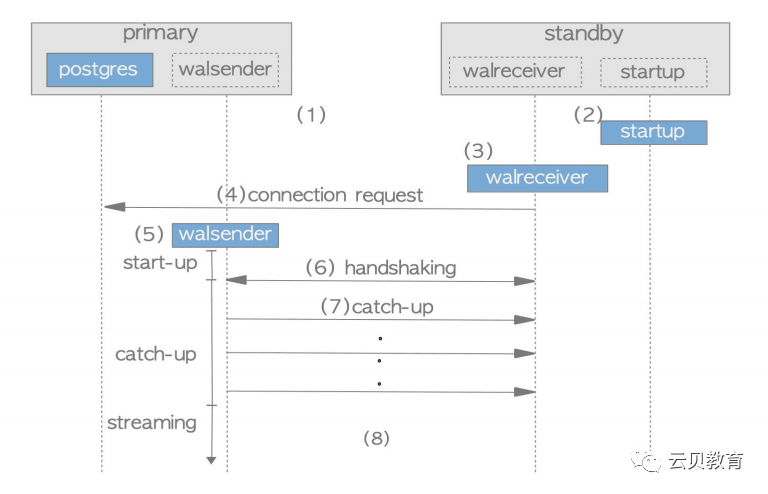
start-up:见上图5~6
catch-up:上图7
streaming:上图8
backup:因为备份发送整个数据库集群的文件,比如pg_basebackup工具
通过 pg_stat_replication视图可以查看:
testdb=# SELECT application_name,state FROM pg_stat_replication;application_name | state------------------+-----------standby1 | streamingstandby2 | streamingpg_basebackup | backup(3 rows)
3、流复制如何处理
4、主节点和同步备节点如何通讯的
假设在备节点配置了以下参数
synchronous_standby_names = 'standby1'hot_standby = offwal_level = archive
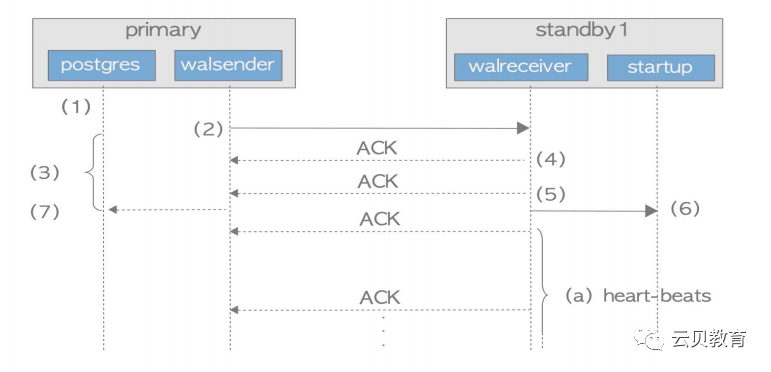
1.后台进程通过执行XLogInsert()和 XLogFlush()函数将wal数据写入并刷新到wal segment。
2.walsender进行将写入wal segment的wal数据发送到walreceiver进程。
3.主节点发送wal数据后,后台进程等待从备节点的ACK响应,更确切的说,后台进程执行内部函数SyncRepWaitForLSN()来获取latch锁,并等待锁释放。
4.备节点的walreceiver进程使用write()函数将wal数据写入到wal segment,并且返回ACK响应给walsender。
5.备节点的walreceiver进程使用fsync()函数将wal数据全部刷新到wal segment,并且返回又一个ACK响应给walsengder,通知startup进程wal已经更新。
6.starup进程回放已经写入wal segment的wal数据。
7.walsender进程在接受到ACK响应后释放latch锁,然后,后台进程提交或者终止的操作就完成了。latch释放的时间依赖于参数synchronous_commit,如果参数是on,则在以上第五步接受ACK响应后释放latch,如果设置是remote_write,那么在第四步接受ACK响应后就释放latch。
备节点发送主节点每一个ACK包含以下内容:
已经写入的最新WAL数据的LSN的位置
已经刷新最新的WAL数据的LSN的位置
startup进程最新回放wal数据的LSN位置
发送ACK的时间戳
通过以下查询可以看到相关LSN的信息:
testdb=# SELECT application_name AS host,write_location AS write_LSN, flush_location AS flush_LSN,replay_location AS replay_LSN FROM pg_stat_replication;host | write_lsn | flush_lsn | replay_lsn----------+-----------+-----------+------------standby1 | 0/5000280 | 0/5000280 | 0/5000280standby2 | 0/5000280 | 0/5000280 | 0/5000280(2 rows)
心跳发送间隔通过wal_receiver_status_interval设置,默认10秒。
5、当失败发生时的行为反应
1.设置以下参数为空串
synchronous_standby_names = ''
2.执行reload命令重载配置文件
pg_ctl -D $PGDATA reload
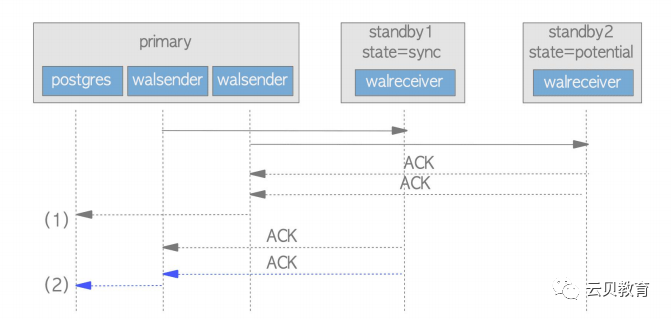
6、管理多个备节点
synchronous_standby_names = 'standby1, standby2'
可以通过以下视图查看这两个值:
testdb=# SELECT application_name AS host,sync_priority, sync_state FROM pg_stat_replication;host | sync_priority | sync_state----------+---------------+------------standby1 | 1 | syncstandby2 | 2 | potential(2 rows)
7、主如何管理多个备节点
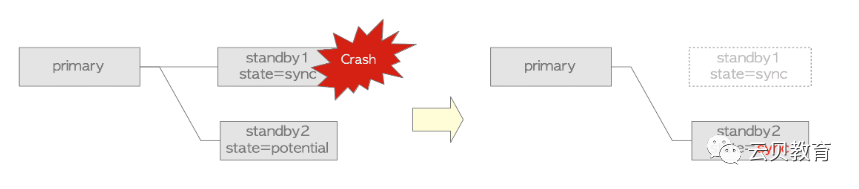
8、故障发生时的行为
9、检测备用服务器的故障
流复制使用两种常见的故障检测程序,而且不需要任何特殊的硬件。
1.备用服务器进程故障检测:当检测到walsender和walreceiver之间的连接断开时,主服务器立即确定备用服务器或walreceiver进程故障。当一个low level网络函数在写或读walreceiver的套接字时返回一个错误,主函数也会立即判断出备用服务器进程故障了。
2.硬件和网络的故障检测:如果walreceiver在wal_sender_timeout参数设置的时间内(默认为60秒)没有返回任何值,则主服务器判定备服务器故障。与上述故障对比,即使备节点由于故障长时间没有任何响应,也需要wal_sender_timeout这么久的时间确认备节点故障。
02
物理复制
1、什么是流复制
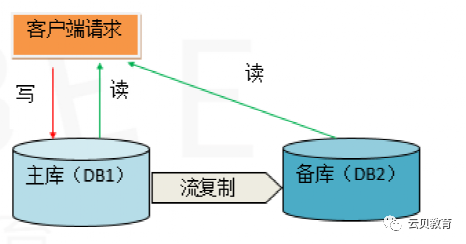
2、流复制原理
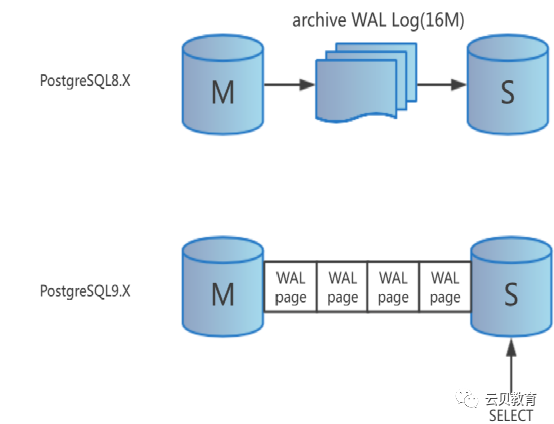
3、流复制不同版本的特性
9.0开始支持1+n的异步流复制.
9.1支持1+1+n的同步和异步流复制
9.2开始支持级联流复制
9.3开始支持跨平台的流复制协议
9.3开始流复制协议增加了时间线文件传输的协议, 支持自动切换时间线.
9.4可以使用流复制做增量数据同步,所以停机服务时间会非常短。
4、流复制的优势
5、异步流复制
流复制传递日志两种方式:
异步流复制
同步流复制
两者的主要区别:
同步复制较高数据一致性规则:
A.考虑数据丢失
1.事物发送到master。
2.事物提交到master。
3.在事物发送到slave之前,master宕机。
4.slave永远都不会收到这个事务。
B.考虑性能问题
6、异步流复制的具体实现
关闭防火墙systemctl status firewalld.servicesystemctl stop firewalld.servicesystemctl disable firewalld.service
SELINUXvi etc/selinux/config将SELINUX=enforcing 改为SELINUX=disabled
流复制配置#创建replica用户create role replica login replication encrypted password 'REPLICA321';
创建物理复制槽select * from pg_create_physical_replication_slot('node1');select * from pg_create_physical_replication_slot('node2');select * from pg_replication_slots;
7、异步流复制的具体实现
主库db1配置:
vi $PGDATA/postgresql.conf================listen_addresses = '0.0.0.0' # what IP address(es) to listen on;port = 5432 # (change requires restart)max_connections = 1000 # (change requires restart)superuser_reserved_connections = 13 # (change requires restart)unix_socket_directories = '.' # comma-separated list of directoriesunix_socket_permissions = 0700 # begin with 0 to use octal notationtcp_keepalives_idle = 60 # TCP_KEEPIDLE, in seconds;tcp_keepalives_interval = 10 # TCP_KEEPINTVL, in seconds;tcp_keepalives_count = 10 # TCP_KEEPCNT;shared_buffers = 2048MB # min 128kBvacuum_cost_delay = 10 # 0-100 millisecondsbgwriter_delay = 10ms # 10-10000ms between roundswal_level = replica #minimal replica 逻辑wal_writer_delay = 10ms # 1-10000 millisecondsmax_wal_senders = 10 # max number of walsender processeshot_standby = on # "on" allows queries during recoverywal_receiver_status_interval = 1s # :send replies at least this oftenhot_standby_feedback = on # send info from standby to preventlog_destination = 'csvlog' # Valid values are combinations oflogging_collector = on # Enable capturing of stderr and csvloglog_directory = 'pg_log' # directory where log files are written,log_truncate_on_rotation = on # If on, an existing log file with thelog_rotation_age = 1d # Automatic rotation of logfiles willlog_rotation_size = 10MB # Automatic rotation of logfiles willlog_checkpoints = onlog_connections = onlog_disconnections = onlog_error_verbosity = verbose # terse, default, or verbose messageslog_timezone = 'PRC'datestyle = 'iso, mdy'timezone = 'PRC'lc_messages = 'C' # locale for system error messagelc_monetary = 'C' # locale for monetary formattinglc_numeric = 'C' # locale for number formattinglc_time = 'C' # locale for time formattingfull_page_writes = onsynchronous_commit = on # synchronization level;wal_log_hints = onsynchronous_standby_names = ''max_replication_slots = 20archive_mode = onarchive_command = 'cp %p opt/arch/%f && echo %f >> opt/arch/archive.list'
1、注解:
wal_level 表示启动搭建hot Standby v9.6- replicamax_wal_senders 设置为一个大于0的数,表示主库最多可以有多少个并发的standbywal_keep_segments 设置为一个尽量大的值,以防止主库生成WAL日志太快,日志还没有来得及传送到standby就被覆盖,但是需要考虑磁盘空间允许,一个WAL日志文件的大小是16M。
主库创建一个超级用户来专门负责让standby连接去拖WAL日志
------
pg_hba.conf
2、备库db2配置:
从此处开始配置备库,首先通过pg_basebackup命令行工具在从库上生成基础备份
命令如下:
rm -rf pg_rootpg_basebackup -F p -D $PGDATA -h 本节点上级节点IP -p 本节点上级节点端口 -U replicaREPLICA321
recovery.conf pg11版本之前
restore_command='cp opt/arch/%f %p'recovery_target_timeline='latest'standby_mode=onprimary_conninfo='host=本节点上级节点 port=5432 user=replica password=REPLICA321 keepalives_idle=60'primary_slot_name = 'node1' #node2 node3
注意 recovery.conf 的 primary_slot_name 在不同节点值会不同。
3、备库recovery.conf 文件配置
recovery.conf 是一个配置文件,用于主库,备库切换时的参数配置
可以从 $PGHOME/share 目录下复制一份 recovery.conf.sample 到备库 $PGDATA 目录,
也可以通过pg_basebackup制定-R参数生成。
关键参数注释:
standby_mode = '' --标记PG为STANDBY SERVER
primary_conninfo = '' --标识主库信息
trigger_file = ''/temp/aaa.trigger” --标识触发器文件
4、主库创建表并插入数据验证异步流复制
主库下建一张表并添加几条数据:
create table repl_t(id int);insert into repl_t select generate_series(1,10);
查看从库同步效果:
select * from repl_t;
验证从库是否能pg_controldata 执行删除、更新操作:
delete from repl_t ;update repl_t set id=2 where id=1;
5、pg_ctl promote 主备切换
执行完pg_rewind之后,一定要修改下recovery.conf文件中的内容。
select pg_is_in_recovery();select * from pg_stat_replication;SELECT * FROM pg_replication_slots;select pg_reload_conf();
8、同步流复制
主库修改postgresql.conf
vi postgresql.confsynchronous_standby_names = 'standby01,standby02‘
异步流复制recovery.conf
recovery_target_timeline='latest'standby_mode = 'on'primary_conninfo = 'user=repl password=111111 host=192.168.137.220 port=1921 sslmode=disable sslcompression=1'
从库recovery.conf的配置:
standby_mode = 'on'primary_conninfo = 'application_name=standby02 user=repl password=111111 host=192.168.137.220 port=1921'
9、会话级别异步、同步复制的切换
10、流复制管理命令
手动切换主备角色的步骤:
1)关闭主库,建议使用 -m fast模式关闭
2)备库执行pg_ctl promote -D $PGDATA,激活备库升级为主库
3)创建或修改原主库的recovery.conf文件primary_conninfo参数指向新主库
4)启动原主库,检查验证状态是否正常
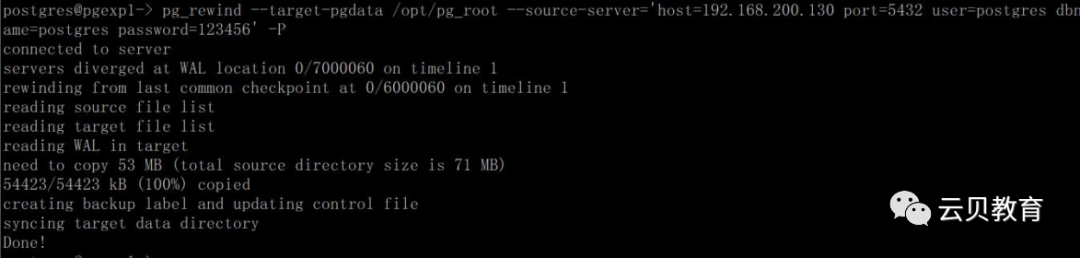
1.8.2 修复备库-pg_rewind
使用pg_rewind 的前提条件为以下之一
postgresql.conf配置文件wal_log_hints参数设置为on;
PG 在initdb初始化数据库时开启 checksums 功能 ,示例:initdb --data-checksums
pg_rewind --target-pgdata opt/pg_root --source-server='host=192.168.200.142 port=5432 user=postgres dbname=postgres password=123456' -P
11、恢复备库-pg_rewind
pg_rewind是如何工作的?
1.从最后一个检查点开始扫描老集群的WAL日志,在该检查点之前,新集群的时间线历史从老集群被创建出来。对于每一个WAL记录,做一个数据块被触及的记录。在新的集群被创建出来以后,这产生所有在老集群中被更改的数据块的列表。
2.从新集群复制所有这些被更改的数据块到老集群。
3.从新集群复制所有其它像clog,conf这样的文件等等到老集群。每个文件,除了表文件。
4.从新集群应用WAL,从故障转移创建的检查点开始。(严格的说,pg_rewind不应用WAL,它只是创建一个备份标签文件以表明PostgreSQL被启动了,它会从检查点重放并应用所有需要的WAL)
03
逻辑复制
1、什么是逻辑复制(pglogical)
2、逻辑复制应用场景
可基于表级别复制,是一种粒度可细的复制,主要用在以下场景:
1、满足业务上需求,实现某些指定表数据同步
2、报表系统,采集报表数据
3、可从多个上游服务器,做数据的聚集和合并
4、PostgreSQL 跨版本数据同步
5、PostgreSQL 大版本升级
3、逻辑复制原理
回放WAL日志中的逻辑条目
发布者/订阅者模型
使用复制槽
订阅连接槽
并行流
复制SQL操作的结果,不是SQL本身
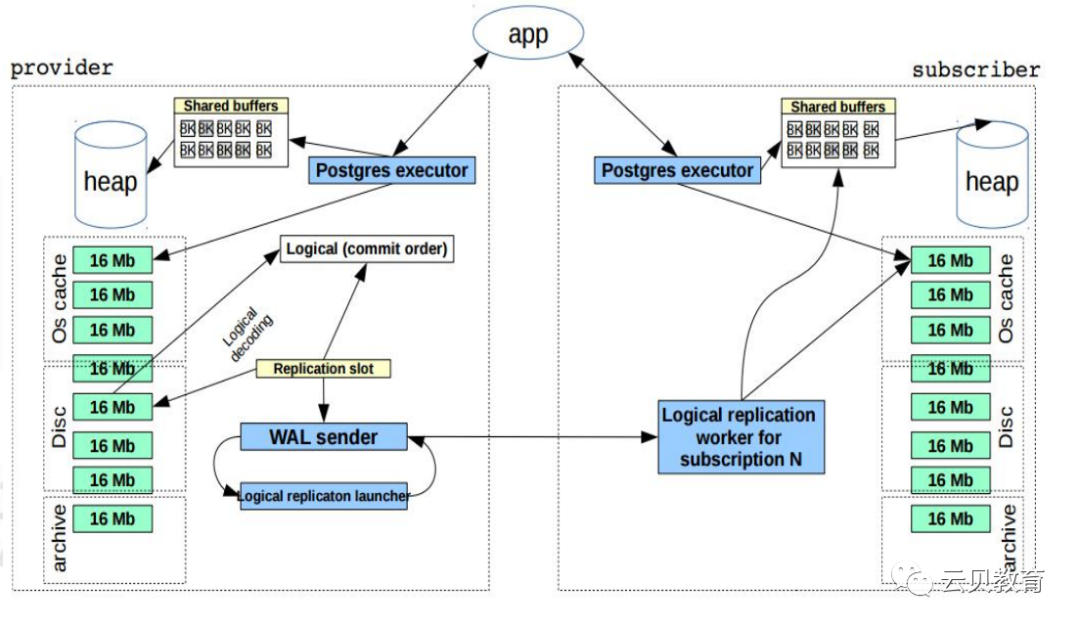
4、逻辑复制相关概念-逻辑复制-发布
publication - 发布
5、逻辑复制相关概念-逻辑复制-发布语法
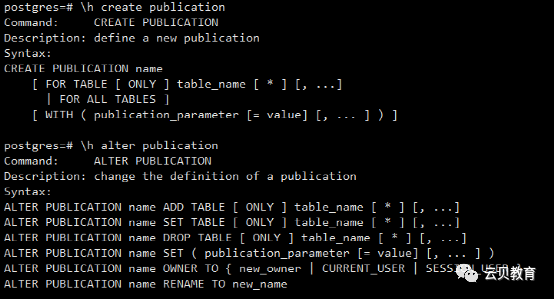
6、逻辑复制-发布
Create table t1(id int);Create table t2(id int);publication - 发布语法示例#创建一个发布,发布两个表中所有更改:CREATE PUBLICATION mypublication FOR TABLE t1, t2;#创建一个发布,发布所有表中的所有更改:CREATE PUBLICATION alltables FOR ALL TABLES;#创建一个发布,只发布一个表中的INSERT操作:CREATE PUBLICATION insert_only FOR TABLE mydata WITH (publish = 'insert');#将发布修改为只发布删除和更新:ALTER PUBLICATION noinsert SET (publish = 'update, delete');#给发布添加一些表:ALTER PUBLICATION mypublication ADD TABLE users, departments;#查看发布select * from pg_publication;
7、逻辑复制-订阅
subscription - 订阅
subscription - 订阅语法
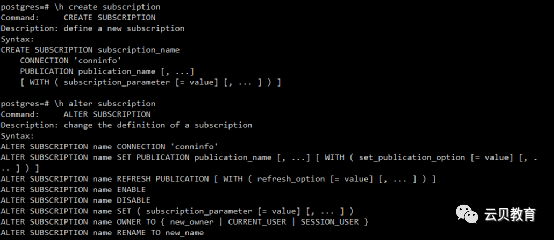
subscription - 订阅语法示例
CREATE SUBSCRIPTION mysubCONNECTION 'host=192.168.200.142 port=5432 user=postgres dbname=postgres'PUBLICATION mypublication;vi postgresql.conf wal_level = logical
CREATE SUBSCRIPTION mysubCONNECTION 'host=192.168.1.50 port=5432 user=foo dbname=foodb'PUBLICATION insert_onlyWITH (enabled = false);
将订阅的发布更改为insert_only:
ALTER SUBSCRIPTION mysub SET PUBLICATION insert_only;
禁用(停止)订阅:
ALTER SUBSCRIPTION mysub DISABLE;
8、逻辑复制-配置
subscription - 订阅相关配置
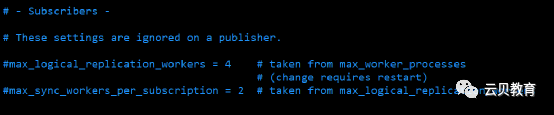
9、逻辑复制-复制槽
Replication Slots - 复制槽(发布端)
#postgresql.conf关联配置wal_level = logical #minimal replicamax_replication_slots = 10 #max_replication_slots 值最少需设置成 1,设置后重启数据库生效。#创建复制槽select * from pg_create_logical_replication_slot('log_slot1', 'test_decoding');#查看复制槽信息select * from pg_replication_slots where slot_name='log_slot1';#查看复制槽解析记录,记录只能查询一次,之后查询为空,如果想重复查询到日志,需使用pg_logical_slot_peek_changes() 函数SELECT * FROM pg_logical_slot_get_changes('log_slot1', NULL, NULL);#使用 pg_recvlogical 接收数据变化pg_recvlogical -h 127.0.0.1 -d postgres --slot log_slot1 --start -f -
10、逻辑复制的限制
版本限制
pglogical是逻辑复制的技术组件,功能使用存在数据库版本限制:
11、逻辑复制-其它限制
不支持DDL复制(ALTER TABLE/CREATE TABLE)
不支持TEMPRORARY表和UNLOGGED表复制
不支持Sequences复制( serial/bigserial/identity)
不支持TRUNCATE操作复制
不支持大对象复制(Bytea)
不支持视图、物化视图、外部表复制
以下两种情况逻辑复制不支持:
publisher->public.foo replicates to subscriber→private.foo
publisher->public.foo replicates to subscriber->partitioned->public.foo
分区表的逻辑复制,需要面向子表创建发布:
CREATE TABLE parttest (id bigint, test text);– PRIMARY KEYS don’t work on partitioned tablesCREATE TABLE parttest0 PARTITION OFparttest FOR VALUES FROM (1) TO (100);CREATE TABLE parttest1 PARTITION OFparttest FOR VALUES FROM (101) TO (200);CREATE PUBLICATION parttest FOR TABLE parttest0,parttest1;
12、逻辑复制-示例1
1. 规划发布、订阅节点(可以是一台主机的两个实例,或者不同主机的两个实例)
2. 发布节点配置文件
postgresql.conf :wal_level = logical & listen_addresses = '*'pg_hba.conf: host all repuser 订阅端ip/32 md5
3. 发布节点创建复制用户
create role repuser login CONNECTION LIMIT 10 replication encrypted password 'repuser';\du
备注:用于逻辑复制的用户必须是 replication 角色 superuser 角色
4. 发布节点为复制用户授权
create table test_lr1(id int4 primary key ,name text);insert into test_lr1 values (1,'a');grant connect on database postgres to repuser;grant usage on schema public to repuser;grant select on test_lr1 to repuser;\dp+ test_lr1;
5. 发布节点为复制表创建发布
create PUBLICATION pub1 FOR TABLE test_lr1; #为表test_lr1创建发布select * from pg_publication; #查看创建的发布

6. 订阅节点创建接收表及订阅
create table test_lr1(id int4 ,name text);create subscription sub1 connection 'host=192.168.200.142 port=5432 dbname=postgres user=repuser password=repuser' publication pub1;select * from pg_subscription;

7. 配置完成,发布节点分别向表中插入数据
insert into test_lr1 values (6,'e');
8. 订阅节点查看逻辑复制效果
select * from test_lr1 ;
13、逻辑复制-示例2
1. 发布节点修改发布,测试插入1000万数据的逻辑同步
create table test_big2(id int4 primary key, create_time timestamp without time zone default clock_timestamp(), name character varying(32));grant select on test_big2 to repuser;ALTER PUBLICATION pub1 add TABLE test_big2;
2. 订阅节点创建同步表并手动执行刷新命令
create table test_big2(id int4 primary key, create_time timestamp without time zone default clock_timestamp(), name character varying(32));ALTER SUBSCRIPTION sub1 REFRESH PUBLICATION ;
3. 逻辑同步结果
上游节点插入数据
insert into test_big2(id,name) select n,n*random()*10000 from generate_series(1,10000000) n ;select * from test_big2 ;
1000万数据同步大概用了不到30秒,速度很快。
14、逻辑复制-小结
publication - 发布者
subscription - 订阅者
流复制与逻辑复制主要差异:

