




文章信息:
Title: You are AllSet: A Multiset Learning Framework for Hypergraph Neural Networks.
Authors: Eli Chien* (UIUC), Chao Pan* (UIUC), Jianhao Peng* (UIUC), Olgica Milenkovic (UIUC).
文章链结:
https://openreview.net/forum?id=hpBTIv2uy_E
代码:
https://github.com/jianhao2016/AllSet
摘要
图机器学习(特别是图神经网络)已经在许多图相关任务取得成功,图可以刻划物件之间的 「俩俩交互」 关係,例如在社群网络中,每个用户为点(node)而朋友(或其他交互关係)为边(edge)。但在现实问题中,我们也有许多非俩俩交互的关係,例如在共同作者网络中,每个作者为点而论文为"边"。可以注意到此处每个"边"可能包含了 「超过两个点」,这也就是所谓的超边(hyperedge),而这种广义的图则被称作超图(hypergraph)。
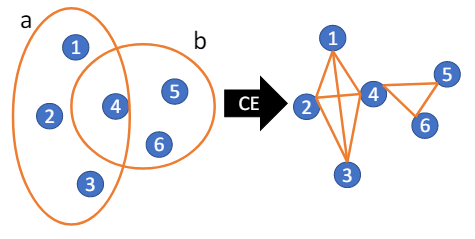
一个最直接处理超图数据的方法就是透过集团扩张(clique-expansion, CE)转换成一般的图,之后便可以套用一般的图神经网络去处理。然而,此种转换是会丢失信息的,进而于其他任务中造成算法次优的表现[Li et al. ICML 2018, Chien et al. AISTATS 2019]。因此,研究者们也提出了许多複杂但直接处理超图的算法,例如多线性PageRank[Gleich et al. SIMAX 2015]与超图上的 特徵问题有紧密的关係,[Tudisco et al. WWW 2021] 也于其工作中指出使用CE做标籤传播的表现在某些情况下会比专门设计的非线性超图标籤传播要差。至此,有两个重要的问题便自然浮现:
是否存在一统一框架可以包含CE、Z-based以及其他超图传播? 我们能否设计超图神经网络使其能根据数据学习不同且合适的超图传播?
本文中我们对两者给出了肯定的答案。
AllSet 框架
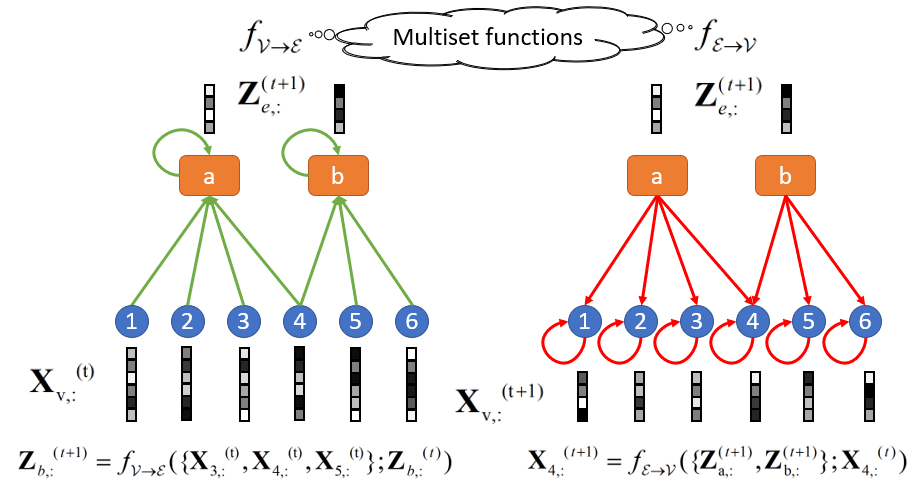
我们首先列出一些定义:一个超图 包含了点集 与超边集 。每个超边 为点集的子集 ,为了方便起见我们也直接用 表示该超边的编号。我们用 代表节点表示(representation)矩阵而 为关联矩阵
最后,我们定义 为超边 所对应的节点表示多重集。同理, 为节点 所对应的超边表示多重集,且 为超边表示矩阵。而我们的AllSet框架的传播规则如下:
其中, 为两个多重集函数。注意,这裡我们也假设了, 皆有完整的超图拓谱信息,使其能还原度正则化(degree normalization)。
我们的理论贡献如下:
(Theorem 3.4) AllSet框架的表达能力(expressive power)「严格大于」许多现有的超图神经网络,包含HGNN [Feng et al. AAAI 2019], HyperGCN [Yadati et al. NeurIPS 2019], HCHA [Bai et al. PR 2021], HyperSAGE [Arya et al. 2020], HNHN [Dong et al. 2020]. (Theorem 3.3) CE-based 与 Z-based 传播定义皆可被AllSet还原。 (Theorem 3.5) AllSet是MPNN架构[Gilmer et al. ICML 2017]的超图推广。
值得一提的是,先前绝大部分的工作在设计超图神经网络时,还是基于类似图卷积(graph convolution)的思想,也就是根据超图定义下的拉普拉斯算子(Laplacian)来设计。其中HGNN与HCHA比较接近CE-based定义下的超图拉普拉斯算子,如 。而HNHN与我们类似的定义了 与的两个传播,但(粗略地说)只是将一般连接矩阵的角色替换成关联矩阵。我们工作的创新性在于不去纠结该用何种超图拉普拉斯算子定义传播,而是将其看作两个多重集函数,让模型能自适应的去学习适合数据的传播方式。
如何学习AllSet layer?
至此我们说明了AllSet框架的理论表达能力,但仍尚未说明如何学习两个多重集函数, 。根据我们AllSet的思想,我们必须确保模型为多重集函数的万能模拟性质(universal approximation)。Deep Sets [Zaheer et al. NeurIPS 2017] 与 Set Transformer [Lee et al. ICML 2019]皆具有此一性质,因此为良好的选择。我们将这些组合后得到的超图神经网络层分别称为AllDeepSets 与 AllSetTransformer。
其中MH为多头注意力机制(multihead attention),表示串联(concatenation),LN表示层正则化(layer normalization)。结合我们关于AllSet的理论结果,我们的AllSetTransformer 与 AllDeepSets的表达能力在理论上皆比现有的超图神经网络强。
实验结果
我们将实验重点放在节点分类任务上。除了五个常用的引用网络数据集,我们也蒐集了另外三个较少使用的UCI数据集(Zoo, 20News, Mushroom)与两个CV相关的数据集(NTU2012, ModelNet40)。另外,我们也新提出了三个超图数据集(Yelp, House, Walmart),且将许多现有的超图神经网络整合到我们的代码中统一测试,有鑑于在超图任务上尚未有像OGB的整合,我们的代码与新数据可以看做对于超图神经网络测试基准化的第一步。
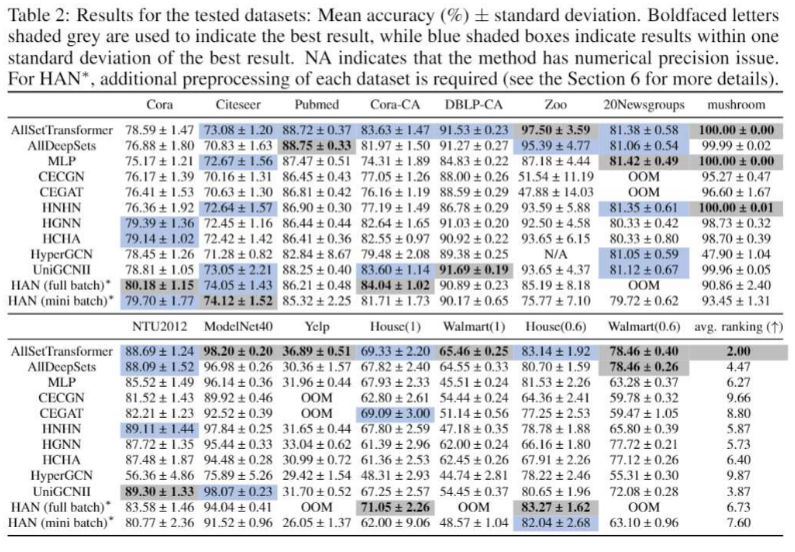
我们可以看到我们的AllSetTransformer总体来说表现最好,除cora外在6个数据集上取得最佳表现与在其馀的数据集与最佳模型表现相似。而其他模型都至少在两个数据集上表现不佳。例如最强的基线(baseline)模型UniGCNII [Huang et al. 2021 IJCAI]在Yelp 以及Walmart上表现明显差于AllSetTransformer。此一结果也凸显的仅在基本的引用网络数据集测试超图神经网络是不足的,我们必须增加更多不同的超图数据集已确保超图神经网络的泛用性。
另外值得注意的是,虽然AllDeepSets与AllSetTransformer在理论上的表达能力相同,但如同Set Transformer作者提到,其注意力机制能帮助模型在现实中学习的更好,这点与我们的实验结果也相吻合。
结论
我们针对超图神经网络提出了一个泛用的框架AllSet,我们证明了大部分现有超图神经网络层的表达能力皆严格弱于AllSet,且证明了AllSet为MPNN的超图推广。我们利用近年深层多重集函数学习的结果,结合AllSet概念设计出可学习的AllSet层AllSSetTransformer。我们的实验显示在节点分类任务中AllSetTransformer的表现优于SOTA超图神经网络,且我们也引入了新的超图数据集,为超图神经网络的测试基准化做了初步的贡献。


大家好我们是深度学习与图网络公众号
如果你有论文想要更多人看到,
欢迎联系我们:GNN4AI
欢迎关注我们

