







点击上方 蓝字关注我们
How Attentive are Graph Attention Networks?
ICLR 2022
https://openreview.net/forum?id=F72ximsx7C1
作者:Shaked Brody, Uri Alon, Eran Yahav
得分:5568
摘要:图注意网络 (GAT) 是最流行的 GNN 架构之一,被认为是图表示学习的先进架构。在 GAT 中,每个节点都关注其邻居,将其自己的表示作为查询,比如下面的公式。
where are learned, and denotes vector concatenation. These attention scores are normalized across all neighbors using softmax, and the attention function is defined as:
Then, GAT computes a weighted average of the transformed features of the neighbor nodes (followed by a nonlinearity ) as the new representation of , using the normalized attention coefficients:
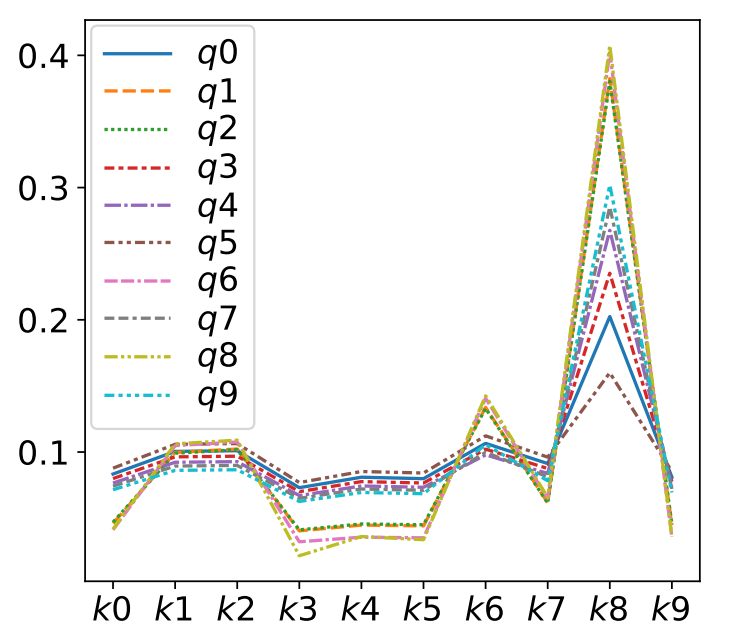
在本文中,作者通过实验展示了 GAT 计算的注意力非常有限:注意力分数的排名不受查询节点的限制。作者将这种受限类型的注意力定义为静态注意力,也就是下面的定义,对应的作者也进行了一系列的实验,如图所示。
Definition 3.1 (Static attention). A (possibly infinite) family of scoring functions computes static scoring for a given set of key vectors and query vectors , if for every there exists a "highest scoring" key such that for every query and key it holds that We say that a family of attention functions computes static attention given and , if its scoring function computes static scoring, possibly followed by monotonic normalization such as softmax.
Static attention is very limited because every function has a key that is always selected, regardless of the query. Such functions cannot model situations where different keys have different relevance to different queries. Static attention is demonstrated in Figure .
怎么理解呢?
GAT 使用静态注意力机制,所以存在 GAT 无法表达的简单图问题:在受控问题中,作者表明静态注意力甚至会阻碍 GAT 拟合训练数据。为了消除这个限制,作者通过修改操作顺序引入了一个简单的修复,并提出了 GATv2:一种动态注意力机制图神经网络变体,它比 GAT 更具表现力。作者进行了广泛的评估,并表明 GATv2 在 OGB 和其他基准测试中的表现优于 GAT,参数相当。
代码:https://github.com/tech-srl/how_attentive_are_gats
作者的方法也比较简单,也就是调换了一下顺序,如下面公式所示,虽然顺序换了之后,表示能力显著增加
GATv2 The main problem in the standard GAT scoring function (Equation ) is that the learned layers and are applied consecutively, and thus can be collapsed into a single linear layer. To fix this limitation, we simply apply the layer after the nonlinearity (LeakyReLU), and the layer after the concatenation, 5 effectively applying an MLP to compute the score for each query-key pair: GAT
(Veličković et al., 2018):
GATv2 (our fixed version):
The simple modification makes a significant difference in the expressiveness of the attention function.
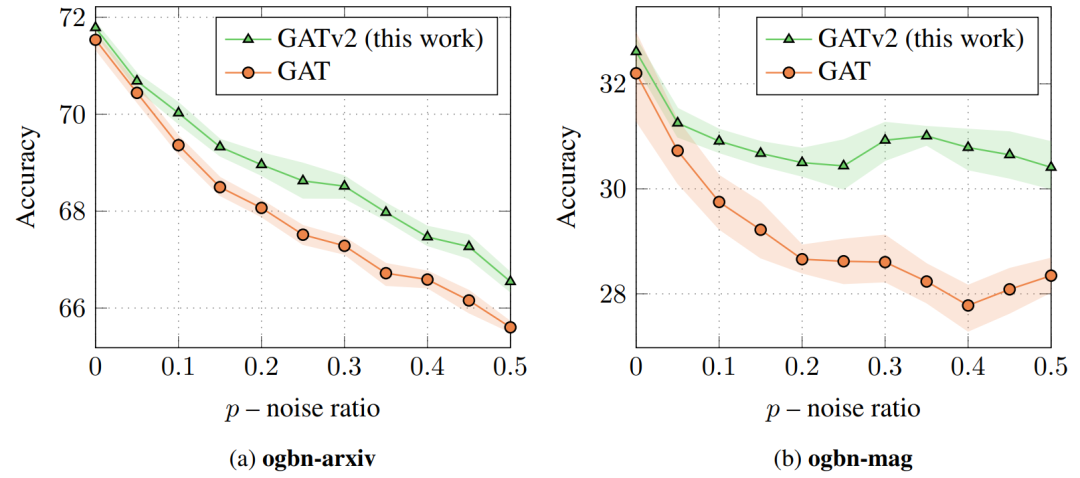




我们应该使用哪种图注意力机制?通常不可能事先确定哪种架构性能最好。
理论上较弱的模型在实践中可能会表现得更好,因为如果任务“太简单”并且不需要这种表达能力,那么更强的模型可能会过度拟合训练数据。直观地说,作者认为节点之间的交互越复杂——GNN 可以从理论上更强大的图注意力机制(如 GATv2)中获得更多好处。主要问题是问题是否具有“有影响力”节点的全局排名(GAT 就足够了),还是不同节点的邻居排名不同(使用 GATv2)。GAT 的作者 Velickovi ˇ c 在 Twitter ´ 6 上证实,GAT 旨在用于当时(2017 年)“易于过度拟合”的数据集,例如 Cora、Citeseer 和 Pubmed(Sen 等人。, 2008),其中数据可能具有“全球重要”节点的潜在静态排名。Velickovi ˇ c´ 同意更新和更具挑战性的基准可能需要更强大的注意力机制,例如 GATv2。在本文中,作者重新审视了传统假设,并表明许多现代图形基准和数据集包含更复杂的交互,因此需要动态关注。


大家好我们是深度学习与图网络公众号
关注图神经网络,图神经网络的应用,最新的图学习研究进展
欢迎关注我们

