







点击上方 蓝字关注我们

对比Laplacian特征图
Contrastive Laplacian Eigenmaps
https://neurips.cc/Conferences/2021/ScheduleMultitrack?event=26953
tein距离
作者:Hao Zhu (Australian National University)Ke Sun (Data61 and Australian National University)Peter Koniusz
图对比学习可以认为是让相似的节点嵌入相近的位置而让不相似的节点嵌入较远的位置。我们一般使用息最大化来实现该目标,这种方式可以转换成JS散度。而本文argue JS散度有缺陷,建议使用另外一种方式,这种方式可以认为是最小化Wasserstein距离
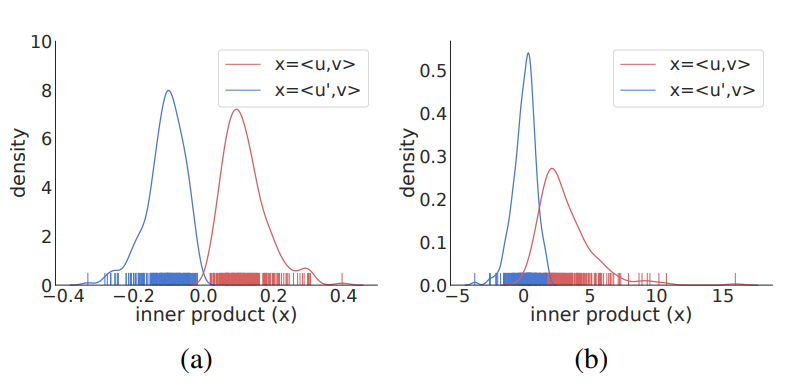
锚点/正嵌入和锚点/负嵌入(GCN 对比设置)之间的点积密度得分 (红色和蓝色曲线)。左图/右图使用在 Cora 上采样的两个不同的小批量。由于分布重叠很小,许多依赖 JS 散度的对比方法可能表现不佳
读过GAN相关的论文的同学,应该知道Wasserstein距离相对于JS散度和KL散度的优势在于:即使两个分布的支撑集没有重叠或重叠非常少,仍然能反映两个分布的远近,而JS散度在此情况下是常量,KL散度可能无意义。
具体来说,在本文中,作者通过对比学习扩展拉普拉斯特征图,并将它们称为对比拉普拉斯特征图(COLES)。作者通过分析,证明了 COLES 实际上是最小化 Wasserstein 距离的surrogate,而Wasserstein 距离可以很好地应对不相交(disjoint)的分布。
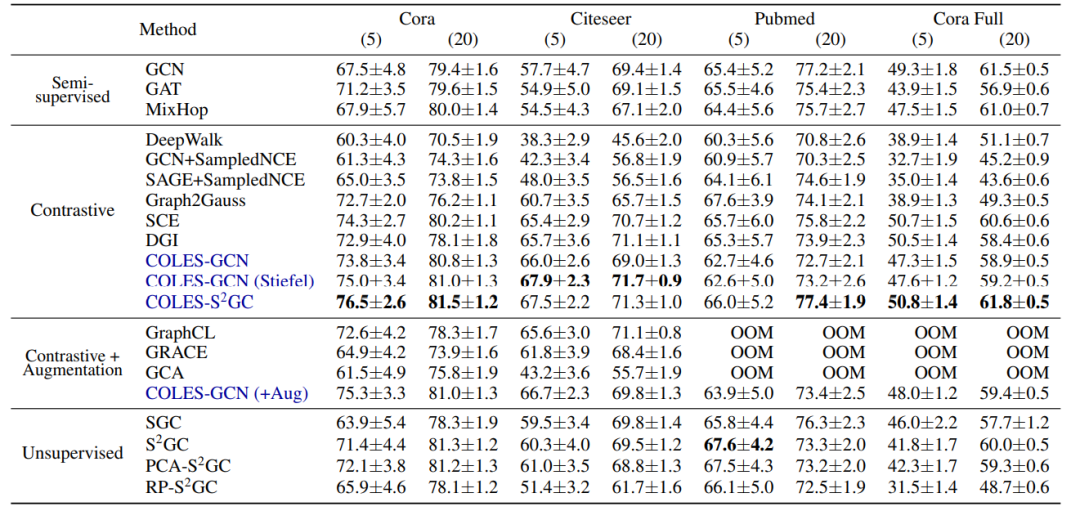
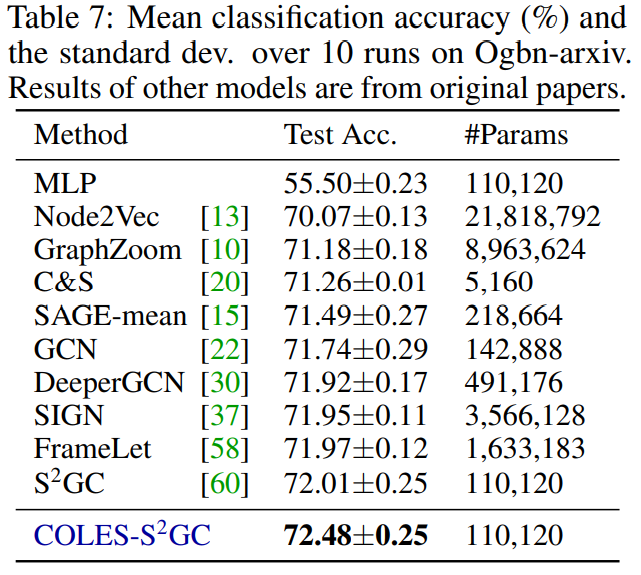
此外,COLES属于的block 对比loss的一种。作者在众多baselines上表明,与 DeepWalk、GCN、Graph2Gauss、DGI 和 GRACE 基线相比,COLES 提供了良好的准确性/可扩展性。

本文贡献:
i. 基于 SampledNCE 框架 [33, 28] 推导出 COLES,将拉普拉斯特征图重新表述为对比设置。
ii.通过使用受 GAN 启发的公式,表明,与传统对比学习中出现的 Jensen-Shannon (JS) 散度相反,COLES 基本上最小化了 Wasserstein 距离的替代项。具体来说,通过展示公式的 Lipschitz 连续性质,证明公式在 Wasserstein 距离上具有 Kantorovich-Rubinstein 对偶性。
iii展示了 COLES 是block-contrastive loss (比pair-wise loss更优秀)[3]
得分:6/5/7/6
Meta review: 这篇论文的评论非常分裂。作者对每位审稿人的批评做出了非常彻底的回应。虽然两个正面评论回应说他们对作者的回复感到满意,但负面评论者都没有回应作者的反馈。一位负面评论者唯一的反对意见是缺乏与 You 等人的比较。作者在响应中提供了这样的比较,表明他们的方法相对于基线的结果很好。另一个审稿人有更详细的批评,但根据我对作者回应的估计,这些批评得到了很好的反驳。不幸的是,我不知道审稿人自己是否认为批评得到了很好的回答。我倾向于推荐接受这篇论文,因为我相信这些回复已经回答了大多数审稿人的批评,而且审稿人自己没有回答作者的问题。
https://openreview.net/forum?id=iLn-bhP-kKH

