







点击上方 蓝字关注我们
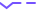

图对比学习中的负采样
题目:Negative sampling strategies for contrastive self-supervised learning of graph representations
URL: https://www.sciencedirect.com/science/article/pii/S0165168421003479
作者信息
Hakim Hafidi ab
MounirGhogho a
PhilippeCiblat b
AnanthramSwami c
a TICLab, College of Engineering and Architecture, Université Internationale de Rabat, Morocco
b LTCI, Telecom Paris, Institut Polytechnique de Paris, France
c United States Army Research Laboratory, Adelphi, Maryland, USA

负采样已被证明是对比学习框架成功的关键因素。本文想要解决下面的问题:
大量的负样本采样对图对比学习是否总是有效?
Hard example是否能够提高嵌入的质量?
最近在CV上研究表明不进行负样本也可以进行对比学习,那么在图上能不能不进行负采样而进行对比学习呢?
作者在此介绍了三种负采样策略:第一种是Random sampling;这个就是大家常用的方式
第二种是根据feature进行选择,一般认为负样本与正样本的相似度越大越难区分,相似度越小,越容易区分,作者选择不大不小的。
而第三种是本文提出的:计算图上节点的距离,对于每一个节点选择l-order的邻居。l等于多少呢?看一下在cora上的实验结果。

总体上看,本文提出了一个以自监督的方式进行学习节点表示的一般框架,称为Graph Constrastive Learning (GraphCL). 它通过最大化同一图中两个随机扰动的节点表示之间的相似性来学习节点嵌入。本文主要研究不同的负抽样策略,以及没有负采样方法的下的图对比学习。
不用负样本呢?
仅仅最大化两个view的一致性而不适用任何的负样本会怎么样呢?
为了研究这个问题,作者训练了一个Siamese神经网络,并且采用stop-gradient, BN等策略。实验发现stop-gradient, BN能够有效防止模型坍塌,但是效果跟有负采样的对比学习相比还是非常的差。
理论分析
虽然有理论上的lower bound

但是作者的实验表明,对比学习的成功在很大程度上取决于其他参数设计,因此不能仅仅归因于相互信息的属性。更确切地说,编码器选择对对比学习的影响也很大。消融研究也发现了负采样策略的效果,以及hard example对于学习好的表示的很重要。
通过Alignment和Uniformity分析对比学习的结果
Alignment在于所有的view的相同的节点表示应该有一定的一致性,那么正样本的相似度大于负样本的相似度,这样的话,我们计算一下所有点的相似度,然后平均值就能衡量模型alignment的好坏了。
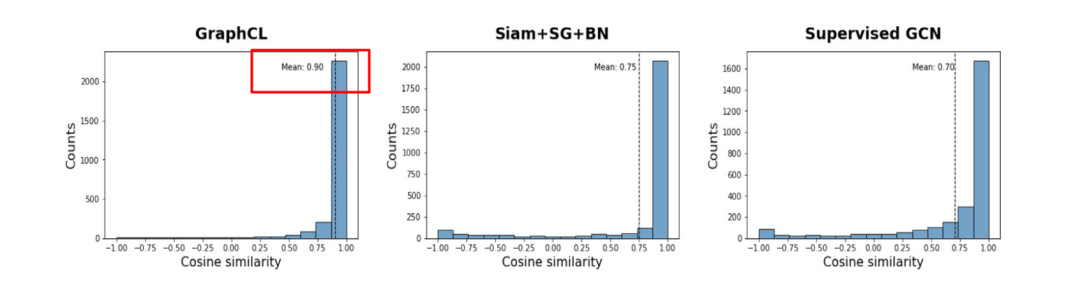
Uniformity在于熵要高,尽可能保持多的信息
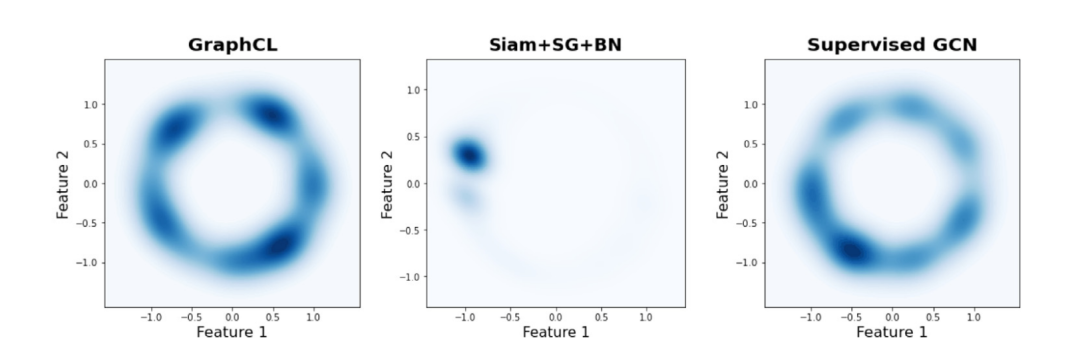
Feature distributions in R^2 using Gaussian kernel density estimation (Bottom).
GraphCL embeddings clearly display both properties.

