




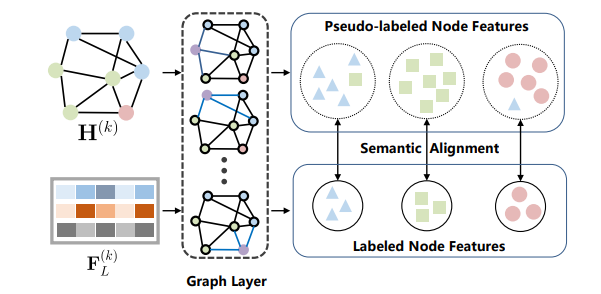
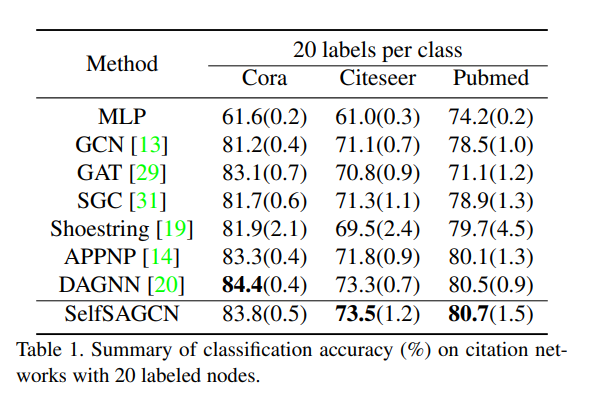
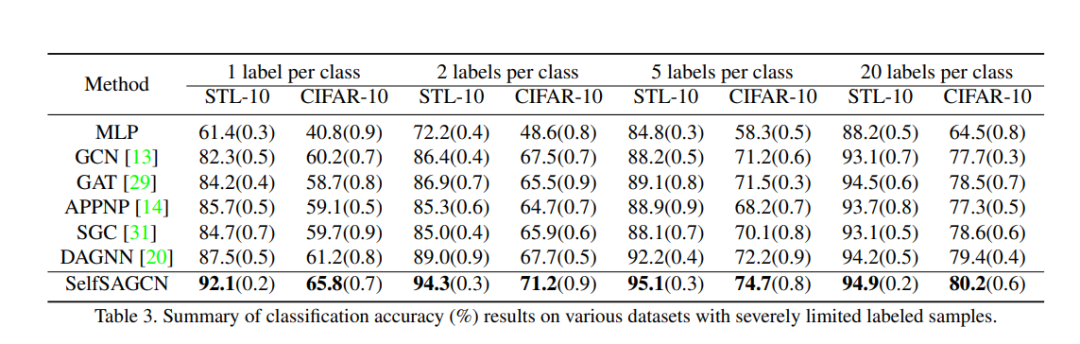
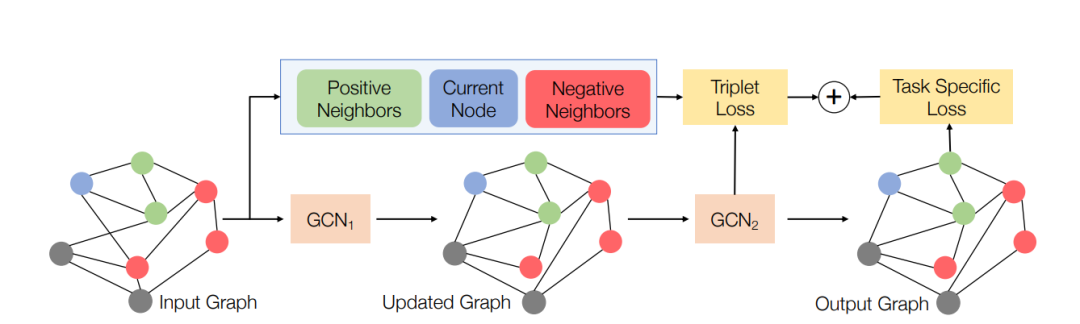
SelfSAGCN: Self-Supervised Semantic Alignment for Graph Convolution Network
Learning Graphs for Knowledge Transfer With Limited Labels
Learning Graph Embeddings for Compositional Zero-Shot Learning
文章转载自深度学习与图网络,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
