





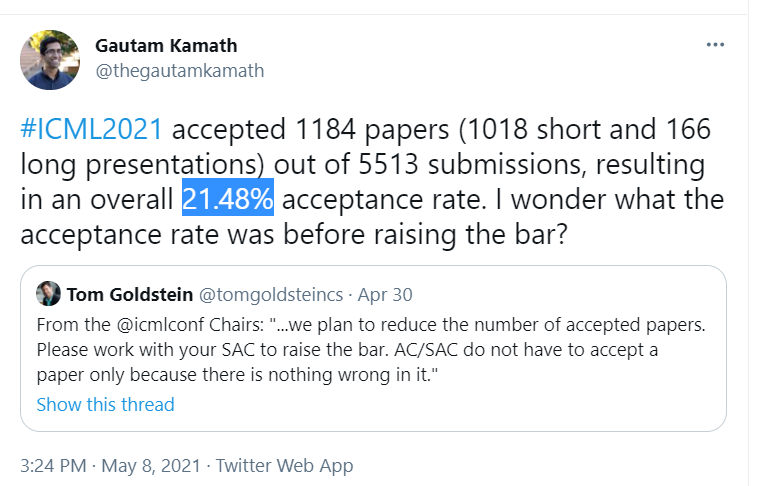
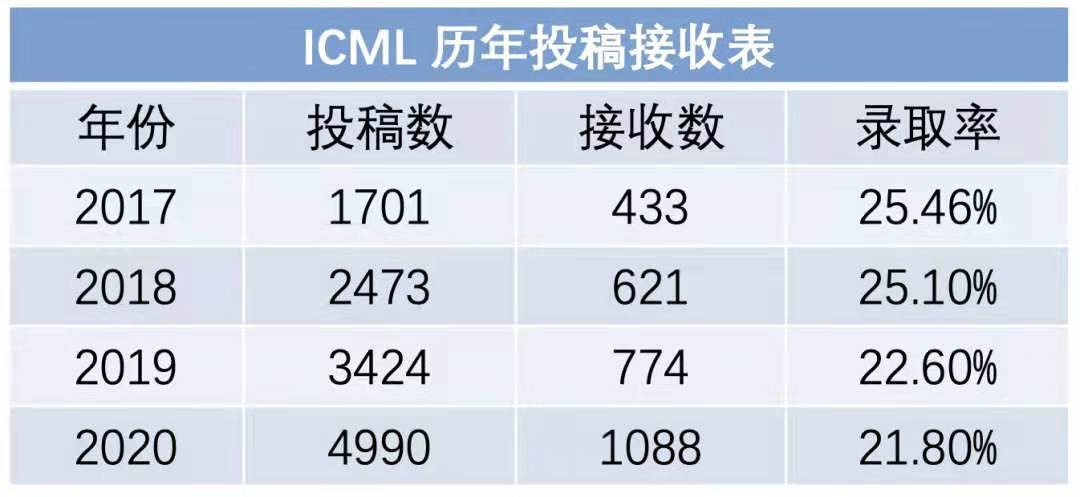
今年一共有5513篇有效投稿,其中1184篇论文被接收,接收率为21.48% 。另外在这1184篇被接收论文中,有166篇长presentations和1018篇短presentations。
ICML是 International Conference on Machine Learning的缩写,即国际机器学习大会。今年第37届ICML原定于2020年7月18-24日在线举行。
从下表可以看出,在投稿量增长523篇(10%增长)的情况下,今年21.4%的接收率仍为近五年最低。
下面简单学习一下五篇相关的研究论文:
Lipschitz Normalization for Self-Attention Layers with Application to Graph Neural Networks
Directional Graph Networks
Optimization of Graph Neural Networks: Implicit Acceleration by Skip Connections and More Depth
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
Information Obfuscation of Graph Neural Networks
自注意力层的Lipschitz归一化及其在图神经网络中的应用
Lipschitz Normalization for Self-Attention Layers with Application to Graph Neural Networks


Noah’s Ark Lab, Huawei Technologies France等
George Dasoulas Kevin Scaman Aladin Virmaux
https://arxiv.org/pdf/2103.04886.pdf
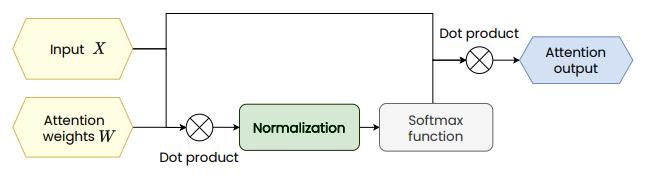
基于注意力的神经网络在许多应用中都是最新技术。然而,当层数增加时,它们的性能趋于下降。在这项工作中,我们表明通过标准化注意力得分来加强Lipschitz连续性可以显着改善深度注意力模型的性能。首先,我们表明,对于深图注意力网络(GAT),在训练过程中会出现梯度爆炸,从而导致基于梯度的训练算法的性能较差。为了解决这个问题,我们对注意力模块的Lipschitz连续性进行了理论分析,并介绍了LipschitzNorm,这是一种用于自注意力机制的简单且无参数的归一化方法,可将模型强制为Lipschitz连续性。然后,我们将LipschitzNorm应用于GAT和Graph Transformers,并显示它们在深层设置(10到30层)中的性能得到了显着改善。更具体地说,我们证明,使用LipschitzNorm的深层GAT模型可实现具有长期依赖性的节点标签预测任务的最新结果,同时在基准节点分类任务中显示出与未归类的同类任务相比具有一致的改进。
有向图网络Directional Graph Networks

https://arxiv.org/abs/2010.02863
Directional Graph Networks
图神经网络(GNN)中缺乏各向异性核极大地限制了其表达能力,导致了一些众所周知的问题,如过度平滑。为了克服这个限制,作者提出了第一个全局一致的各向异性核GNN,允许根据拓扑导出的方向流定义图卷积。首先,通过在图中定义矢量场,提出了一种方法应用方向导数和平滑投影节点特定的信息到场。然后,用拉普拉斯特征向量作为这种向量场。在Weisfeiler-Lehman 1-WL检验方面,证明了该方法可以在n维网格上泛化CNN,并证明比标准的GNN更有分辨力。
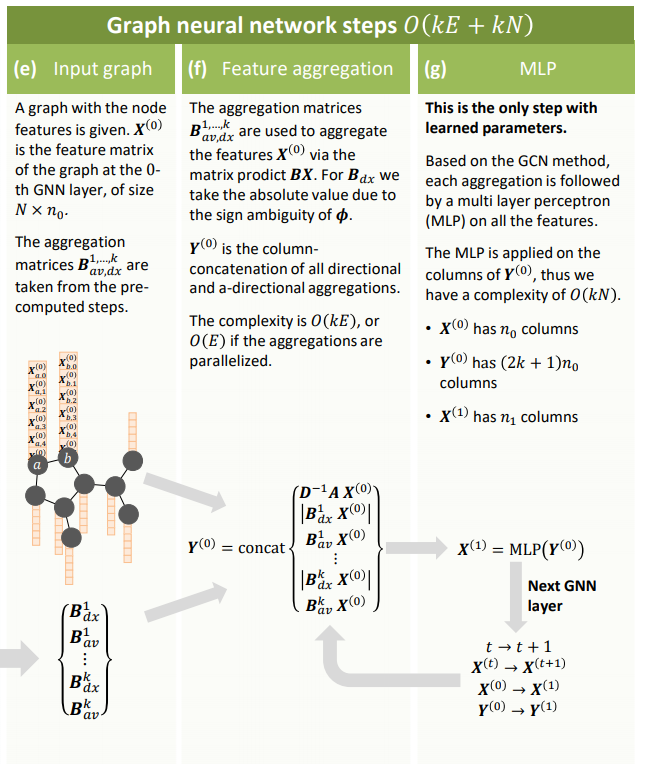
在不同的标准基准上评估了我们的方法,发现在CIFAR10图数据集上相对误差减少了8%,在分子锌数据集上相对误差减少了11%到32%,在MolPCBA数据集上相对精度提高了1.6%。这项工作的重要成果是,它使图网能够以一种无监督的方式嵌入方向,从而能够更好地表示不同物理或生物问题中的各向异性特征。
图神经网络的优化
Optimization of Graph Neural Networks: Implicit Acceleration by Skip Connections and More Depth
https://arxiv.org/abs/2105.04550
作者:Keyulu Xu, Mozhi Zhang, Stefanie Jegelka, Kenji Kawaguchi
GNN的表示能力和泛化能力得到了广泛的研究。但是,它们的优化其实研究的很少。通过研究GNN的梯度动力学,我们迈出分析GNN训练的第一步。具体来说,首先,我们分析线性化(linearized)的GNN,并证明了:尽管它的训练不具有凸性,但在我们通过真实图验证的温和假设下,可以保证以线性速率收敛到全局最小值。其次,我们研究什么会影响GNN的训练速度。我们的结果表明,通过跳过(skip)连接,更深的深度和/或良好的标签分布,可以隐式地加速GNN的训练。实验结果证实,我们针对线性GNN的理论结果与非线性GNN的训练行为一致。我们的结果在优化方面为具有跳过连接的GNN的成功提供了第一个理论支持,并表明具有跳过连接的深层GNN在实践中将很有希望。
GraphNorm:加快图神经网络训练
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
https://arxiv.org/abs/2009.03294
作者:Tianle Cai, Shengjie Luo, Keyulu Xu, Di He, Tie-Yan Liu, Liwei Wang
众所周知,Normalization有助于深度神经网络的优化。不同的体系结构需要专门的规范化方法。在本文中,我们研究什么归一化对图神经网络(GNN)有效。首先,我们调整并评估其他领域到GNN的现有方法。与BatchNorm和LayerNorm相比,InstanceNorm可以实现更快的收敛。我们通过显示InstanceNorm充当GNN的前提条件来提供解释,但是由于图数据集中的大量批处理噪声,BatchNorm的这种预处理效果较弱。其次,我们证明InstanceNorm中的移位操作会导致GNN的表达性下降,从而影响高度规则的图。我们通过建议GraphNorm以可学习的方式解决此问题。根据经验,与使用其他规范化的GNN相比,具有GraphNorm的GNN收敛更快。GraphNorm还改善了GNN的泛化,在图分类基准上实现了更好的性能。
图神经网络的信息混淆
Information Obfuscation of Graph Neural Networks
https://arxiv.org/abs/2009.13504
code: https://github.com/liaopeiyuan/GAL
尽管图神经网络(GNN)的出现大大改善了许多应用中的节点和图表示学习,但邻域聚合方案向试图提取有关敏感属性的节点级信息的adversaries 暴露了其他漏洞。在本文中,我们研究了在学习图结构化数据时通过信息混淆保护敏感属性的问题。我们提出了一个框架,可以通过对抗训练以总变化量和Wasserstein距离在本地过滤出预定的敏感属性。我们的方法创建了强大的防御机制来抵御推理攻击,而只在任务性能上造成很小的损失。从理论上讲,我们针对最坏情况的adversaries 分析了我们框架的有效性,并在最大程度地提高预测准确性和最小化信息泄漏之间进行了固有的权衡。来自推荐系统,知识图和量子化学的多个数据集的实验表明,该方法可为各种图结构和任务提供强大的防御能力,同时还能为下游任务提供具有竞争力的GNN编码器.

