




FedGL: Federated Graph Learning Framework with Global Self-Supervision
https://arxiv.org/pdf/2105.03170.pdf
CHUAN CHEN and WEIBO HU, Sun Yat-sen University, China
ZIYUE XU, Xi’an Jiaotong University, China
ZIBIN ZHENG, Sun Yat-sen University, China
图数据在现实世界中无处不在。图学习 (GL) 试图挖掘和分析图数据,以便发现有价值的信息。现有的 GL 方法是为集中式场景设计的。然而,在实际场景中,图数据通常分布在不同的组织中,即孤立数据岛的诅咒。为了解决这个问题,我们将联邦学习融入到 GL 中,并提出了一个通用的联邦图学习框架 FedGL,该框架能够获得高质量的全局图模型,同时通过在联邦训练期间发现全局自监督信息来保护数据隐私。具体而言,我们propose将预测结果和节点嵌入上传到服务器以发现全局伪标签和全局伪图,并将它们分发到每个客户端,分别训练,从而提高每个local model的质量。此外,全局自监督使每个client的信息能够以隐私保护的方式流动和共享,从而缓解异构性并利用不同客户端之间图数据的互补性。最后,实验结果表明 FedGL 在四个广泛使用的图形数据集上显着优于基线。
在现实世界中,图数据无处不在,例如社交网络、金融交易网络和生物网络。图学习(GL)旨在通过使用各种图模型,包括图正则化、图嵌入 、图神经网络 等,从图数据中挖掘出有价值的信息。GL 推动了各种应用,例如社区检测、个性化推荐 和欺诈检测。现有的 GL 方法是为集中式学习场景而设计的,即集中式图数据存储和集中式模型训练。然而,在大多数行业中,图数据以孤岛的形式存在,即分布在不同的组织或机构中。考虑到金融行业的一个实际问题,每家银行都拥有客户信息、交易网络和违约历史。银行有一些共同的客户。银行希望合作对其客户进行全面的信用评估并确定共同的行业黑名单。一个直观的想法是将图数据收集在一起并合并成一个大图,然后将其提供给现有的 GL 方法。然而,几乎不可能收集到来自全国各地的机构的数据由于隐私安全 和行业竞争。因此,如何在不损害数据隐私的情况下,协同分布在不同组织的图数据来训练高质量的图模型是一个开放而关键的问题。
联邦学习是一种新兴技术,它基于分布在多个设备上的数据集训练机器学习模型,同时防止数据泄漏。关键思想是将数据留在设备(或客户端)上,并通过将客户端产生的本地更新(例如梯度或模型参数)上传和聚合到中央服务器来训练共享的全局模型。从第一个也是最著名的联邦学习算法 FedAvg开始,人们提出了许多改进工作来解决联邦学习的各种问题,包括降低通信成本,克服系统异构性,克服统计异质性,进一步保护数据隐私。直观地说,将联邦学习框架纳入 GL 是满足上述需求的有前途的解决方案。然而,现有的联邦学习相关研究和应用主要集中在处理结构化数据,如图像和文本数据,很少有工作集中在图数据上。有一些未发表的作品 [48, 59] 试图为图数据开发一个联合框架。[59] 假设客户端具有相同的节点、不同的特征和边,并且只有一个客户端有标签。[48] 假设客户端具有相同的节点、特征和边、不同的标签。由于它们做出不同的场景假设,因此很难将它们概括为解决一般联合 GL 问题。此外,在现实世界中,经常观察到客户端具有不同的节点、特征、边和标签,并且有一些重叠的节点。
一般来说,联合 GL 问题有两个严峻的挑战。(1) 异构性:分布在不同客户端的图数据本质上是高度非独立同分布(Non-IID)。在这种情况下,每个客户端使用其图数据训练的本地模型也可能存在较大差异,导致聚合后的全局模型不令人满意。(2)互补性:分布在不同客户端上的图数据通常由于节点重叠而包含互补信息。对于这些重叠的节点,由于无法共享和聚合数据,每个客户端上的图结构并不全面。图 1 异质性和互补性说明
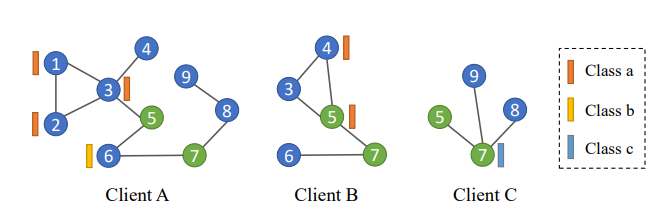

上述两个挑战引出了本文联邦训练期间的两个动机。(1) 如何缓解客户端之间图数据的异构性,让服务端聚合获得高质量的全局图模型?(2) 如何利用每个客户端上的图结构相互补充,从而帮助每个客户端学习更好的局部图模型?
在本文中,作者提出了一个通用的联邦图学习框架 FedGL,它能够通过发现和利用全局自监督信息来有效处理异质性和互补性来学习高质量的图模型。总体框架如图 2 所示。
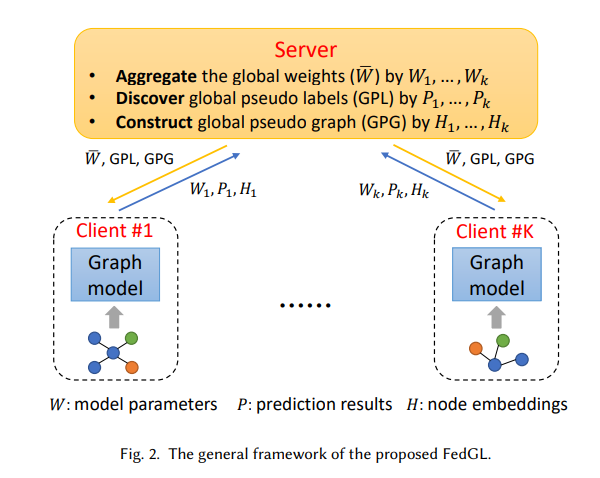
有𝐾 客户端和一台服务器。每个客户端使用其图数据在本地训练一个图模型(本地模型)。现有的联邦学习方法将梯度或模型参数上传到服务器,服务器将它们聚合以获得全局模型并将其分发给下一次迭代。对于提出的 FedGL,额外将每个客户端的预测结果和节点嵌入上传到服务器,用于发现全局自监督信息,包括全局伪标签和全局伪图,从而减轻异构性并利用互补性。具体来说,先融合预测结果,然后以高置信度选择未标记节点的结果来发现全局伪标签。服务器将发现的伪标签分发给每个客户端,训练标签,从而提高每个本地模型的质量。
全局伪标签发现的过程使每个客户端的信息能够以隐私保护的方式流动和集成,从而减轻异构性。此外,建议通过首先融合来自每个客户端的节点嵌入然后重建整个相邻矩阵来构建全局伪图。服务器将构建的全局伪图分发给每个客户端,以补充图结构,从而进一步改进每个局部模型并产生高质量的全局模型。全局伪图发现的过程使得每个客户端的图结构能够以隐私保护的方式被收集和共享,充分利用互补性。
具体内容,请参考:https://arxiv.org/pdf/2105.03170.pdf
