





结果表明,即使不调参或不使用复杂的GNN架构,与最新方法相比,GraphCL框架也可以生成具有相似或更好的通用性,可传递性和鲁棒性的图表示。
Paper: https://arxiv.org/abs/2010.13902
Appendix: https://yyou1996.github.io/files/neurips2020_graphcl_supplement.pdf
本文贡献
由于数据增强是进行对比学习的前提,但在图数据中却未得到充分研究,因此首先设计四种类型的图数据增强,每种类型都强加了一定的prior,并进行了参数化;
利用不同的增强手段获得相关view,提出了一种用于GNN预训练的新颖的图对比学习框架(GraphCL),以便可以针对各种图结构数据学习不依赖于特定扰动的表示形式;
证明了GraphCL实际上执行了互信息最大化,并且在GraphCL和最近提出的对比学习方法之间建立了联系;
证明了GraphCL可以重写为一个通用框架,从而统一了一系列基于图结构数据的对比学习方法;
评估模型在各种类型的数据集上不同扩充方案的性能,揭示模型性能的基本原理,并为采用特定数据集的框架设计提供指导;
GraphCL在半监督学习,无监督表示学习和迁移学习的设置中达到了最先进的性能,此外还增强了抵抗常见对抗攻击的鲁棒性。
图的数据增强

Node dropping:随机从图中去除掉部分比例的节点来扰动G图的完整性,每个节点的失活概率服从i.i.d的均匀分布;
边扰动:随机增加或删除一定比例的边来扰动G 的连通性,每个边的增加或者删除的概率亦服从i.i.d的均匀分布;
属性屏蔽:随机去除部分节点的属性信息,迫使模型使用上下文信息来重新构建被屏蔽的顶点属性。
子图划分:使用随机游走的方式从G 中提取子图的方法。

图对比学习GraphCL
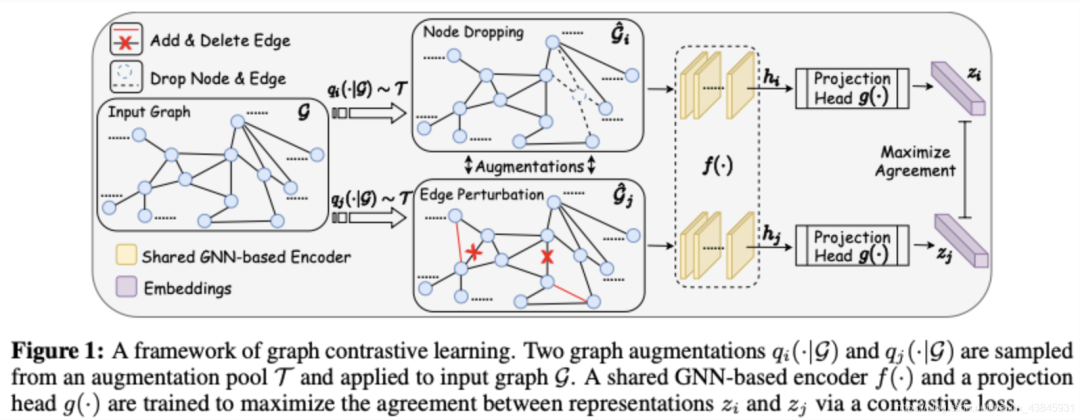
图数据增强 基于GNN的编码器:GNN范式,先聚合邻居再readout成图的embedding; 投影:使用双层MLP表示; Contrastive loss:,使得与负样本对相比正样本对之间的一致性最大化(这里是指的两种数据增强方式之间的一致性)损失函数加入了temperature parameter,最终损失是在小批量中所有正对之间的和表示。
算法流程图如下:

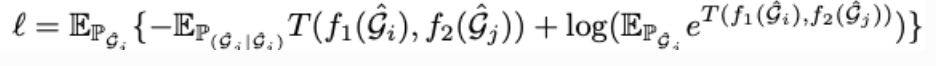
图对比学习中数据增强扮演的角色
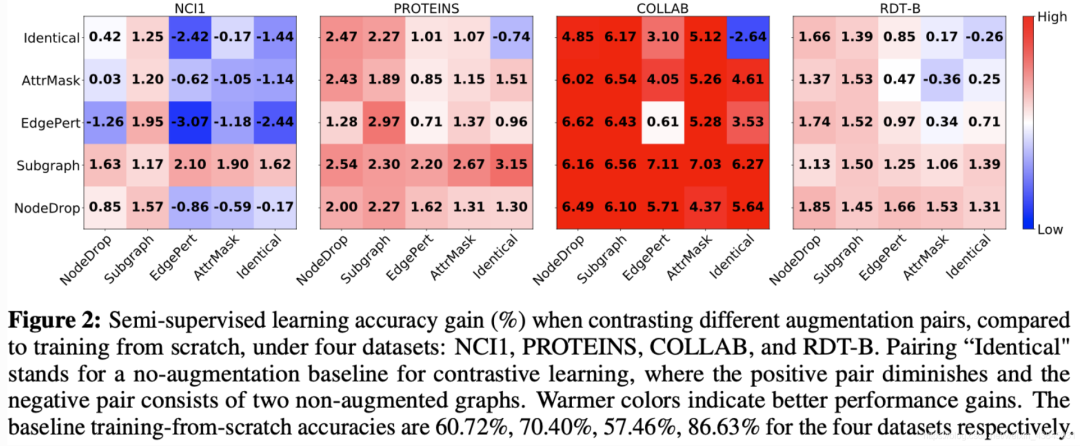
数据扩充对图对比学习至关重要。当应用适当的扩充时,会灌输数据分布上的相应先验,从而通过最大化图及其扩充之间的一致性来使模型学习对所需扰动不变的表示。
组合不同的扩充方式会带来更多的性能收益。与图中对角线的增益相比,最优的增益往往在应用不同的数据扩充方式进行对比学习时获得。这点在视觉对比学习任务中也有类似的结论,组合不同的扩充方式会避免学习到的特征过于拟合low-level的"shortcut",从而使得特征更加的具有通用性。此外,训练不同的特征之间的对比学习模型会使得收敛速度下降。
有效图扩充的类型、范围和模式
直接上实验和结论:
(1)边缘扰动有益于社交网络,但会伤害一些生化分子图。这取决于边的重要程度(图4左2)。
(2) 应用属性masking可在更密集的图中实现更好的性能(图4右2)。
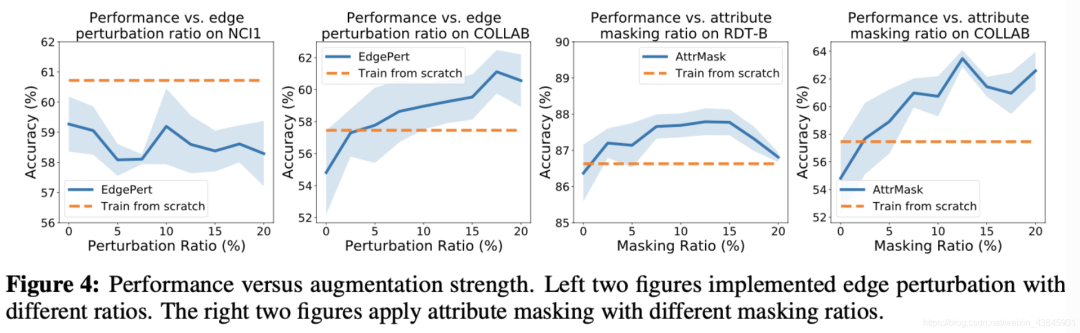
(3)节点删除和子图通常对图数据集有益。节点删除在丢失某些顶点不会更改语义信息的先验条件下直观的迎合了我们的认知。子图刻意增强局部(即子图)和全局信息的一致性有助于表示学习。
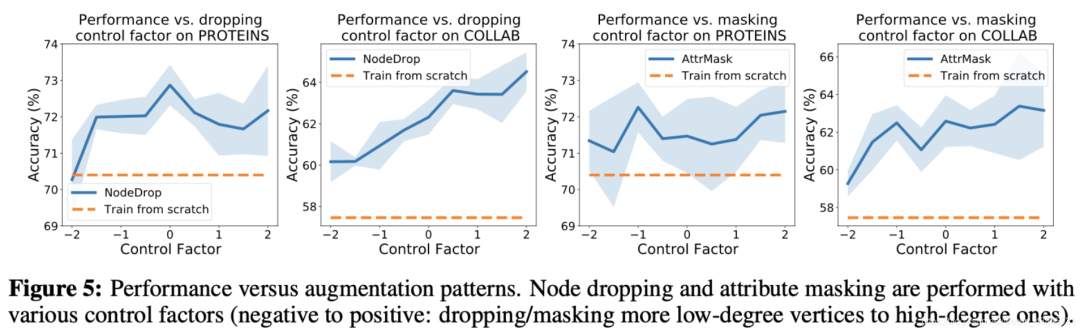
(4)过于简单的对比任务无济于事
在本文中,作者探索针对GNN预训练的对比学习。首先,提出了几种图数据扩充方法,并介绍某些特定的数据分布先验的基础上进行了讨论。随着新的扩充,作者为GNN预训练提出了一种新颖的图对比学习框架(GraphCL),以促进不变表示学习以及严格的理论分析。作者系统地评估和分析了提出的框架中数据扩充的影响,揭示了其原理并指导了扩充的选择。实验结果验证了提出的框架在通用性和鲁棒性方面的最新性能.

