




「不只是为了省钱,或只是减少丢脸时刻,避免影响顾客,更重要的价值是,SRE是确保ML创新速度的关键。」Google ML SRE团队负责人Todd Underwood在去年10月全球SRE年会演讲时,他特别强调,这才是Google早在13年前开始将SRE经验和知识运用到ML系统的关键理由。

Google在2003 年首创了第一个SRE(Site Reliability Engineering,服务可靠性工程)团队,通过系统架构设计、运维流程改善等各种方法,来确保系统运行的更可靠。2014年,Google公开了这套SRE方法论和经验,后来也成了许多企业运维网站和线上服务可靠性的重要参考。
不只是用来确保网站和线上服务的可靠性,13年前,Google已经将SRE成功运用到搜寻服务,储存系统、广告数据储存系统的可靠性运维上,当时开始思考,是不是能将SRE运用到ML系统上,决定先从Google Ads品质团队开始,运用到仰赖大量机器学习演算法的Google的广告推荐机制上。
因为Google关键字广告采点击计费,点击才会计价,靠ML模型来推荐的广告越符合搜寻需求,就会能成功吸引浏览者来点击。
Todd Underwood指出,广告系统越稳定可靠,营收就能越稳定,因此决定开始从这套系统开始导入SRE做法,称为「ML SRE」。Todd Underwood 就是13年前发起了Ads ML SRE团队的关键人物之一,Todd Underwood表示,AI跟ML其实很不一样,AI是从人、应用需求角度来看,但ML则是要让电脑系统可以运用机器学习技术来解决问题,是一种利用数据来训练模型的做法,ML是AI的一个子集。
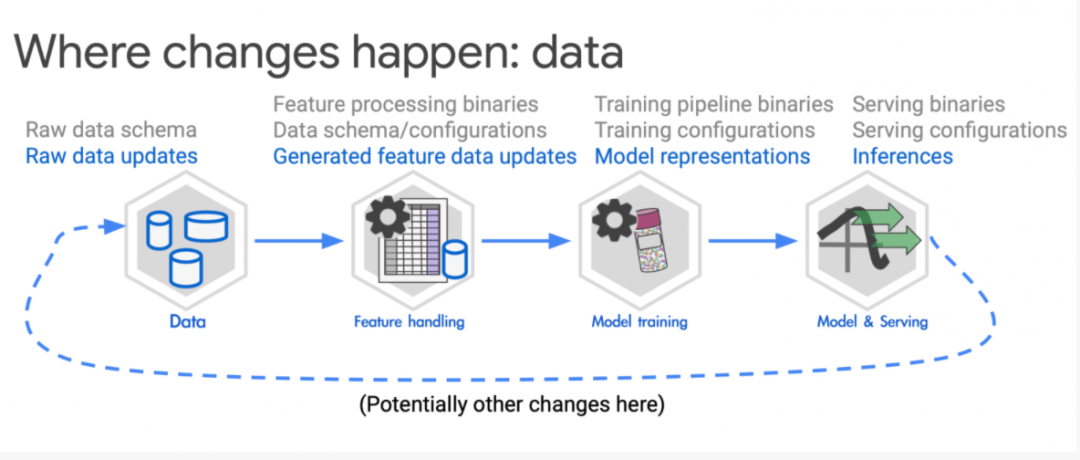
Todd Underwood也公开了Google内部所用ML系统架构,跟大多数企业常见的ML训练流程差异不大。这个ML系统架构包括了5个流程,从数据搜集、数据准备、模型训练、品质管控到提供推论服务,Google打造了一套模型管理工具和流程调度系统,用来追踪模型、特征和数据的后台资料。Google也特别重视数据读取、数据检查、特征数据的分布和变动数据品质的控管。
Google SRE工程师Mary McGlohon正是过去4年来负责运维和开发这套超大规模ML系统的工程师之一。
Mary McGlohon指出,机器学习系统过于复杂和庞大,必须要打造工具来分析,才能探索问题,对ML SRE来说,就不用知道每一件事的业务逻辑,也可以做事。
因此,Google也自行发展了不少ML SRE工具,从更大的尺度来观察系统,找出各种可能出错的状态,并依据过去的错误设计更好的实施方式。
虽然,Google没有公开这些ML SRE工具,但Mary McGlohon归纳出四个Google用来提高ML可靠性的SRE战略,这正是他们过去十多年确保ML系统可靠性的关键秘诀。
这四个策略,包括了,第一,要让失效问题看得见,才能知道为何出错。其次,也需要尽可能验证各种异动,才能避免异动带来的错误,并且要厘清对数据完整性的要求,最后则是得妥善管理工作流程的等待任务。
Mary McGlohon指出,若误以为ML是魔术,这是一个迷思,对在乎系统稳定的工程师来说,今天的偷懒, 可能会带来明天的技术债,先分析ML系统的特征,才能知道系统出错时会有哪些风险,让我们知道可以如何管理风险。
ML系统的特别之处,第一是大量数据的相依性。因为机器学习演算法非常强大,可以有效辨识信号和杂信,这就导致不需要筛选或过滤数据,也能提升预测能力。
甚至,不需要知道哪些数据来源更有价值直接全部汇入,这会带来一个后果,累积越久,就会有越多数据相依性(data dependencies)问题,这也是Google ML系统的一大特质。其次,ML系统其实是一套庞大交互作用的流程系统,必须知道如何安排这些流程,才能管理风险。
最后一点,ML是一种超大规模的非典型工作负载,不同的ML批次运算,会有不一样的运算和数据I/O需求,这对数据调度工作带来很大的挑战。
Google也曾从分析了过去15年ML系统上百起宕机事件的检讨报告后归纳,出19种ML系统宕机问题,Mary McGlohon指出,其中只有30%的问题,是来自ML系统内部的问题,例如标记错误,模型配置设定错误,但高达40%的问题是来自分布式系统的内部问题,例如负载均衡出错,数据结构没有最佳化,工作排程安排错误等。
「从这个结果告诉我们,ML系统的运维可以借鉴其分布式系统的运维和最佳实践做法。」Mary McGlohon指出,Google的ML系统是一种分布式系统,数据密集,流程化的系统,我们挑选了分布式系统最佳实践,数据完整性最佳实践,和工作流程最佳化实际来缓解风险。
ML SRE关键策略1:
让失效问题看得见
「要知道如何解决故障之前,得先知道何时会故障,看得见故障是一件重要的事。」Mary McGlohon表示。
Google内部有一套协调调度平台,可以用来设计模型开发流程,可以设定模型配置,并提供仪表板来检查模型效能,可以用来观察模型如何运行。
不过,Mary McGlohony则是建议,SRE团队最好可以建立一些模型品质预警通知,通知模型开发者以及系统运维人员,一但模型品质开始下滑,可以在更多使用者发现之前,让模型开发者可以展开行动,退回前一版,或赶快开始调查原因。
「仪表板是一种降低事故风险的好方法,发生事故时,要确保开发这个模型的核心人员也能观察到系统的信息,他们可以成为解决问题的帮手。」Mary McGlohon说。
ML SRE 关键策略2:
尽可能验证各种异动
但只靠预警机制还不够,更主动的SRE方法是进一步验证各种系统上线的变动,可以从二进位和数据的变动来追踪。
如何最有效追踪系统的变动,Mary McGlohon建议,任何系统都会带有业务逻辑的二进制文件,不管是,特征处理,模型训练,或推论服务等,都会用到二进制文件,因此,可以验证这些二进制文件来确保是否顺利运行,另一个可以追踪变动的地方是系统配置文件的变动。例如数据Schema配置, 不同阶段的各种配置。
追踪二进制文件和配置文件的变动,最好的做法就是建立一个上线前的Staging(准备)阶段和环境,在这个环境中,复制一份正式系统,进行测试,验证效能,来确保异动的影响符合预期,确定没有问题才正式上线。
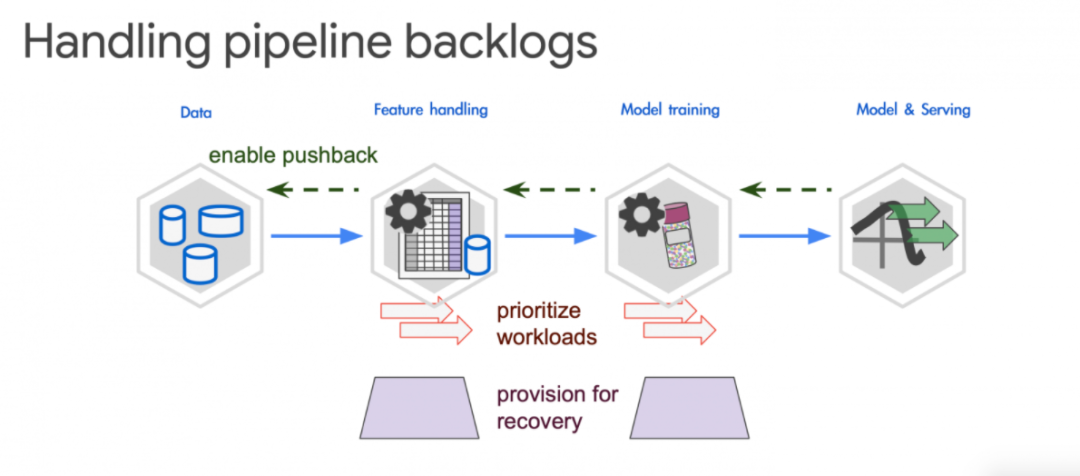
在Staging阶段较容易发现可能导致当机的错误,但不容易发现效率问题的影响,例如I/O用量,CPU用量,一条工作流程跟大量工作流程同时执行的影响不一样,后者可能导致很多等待的任务,而影响了系统运行。
Google还会追踪另外一种变动,就是数据变动,可以从原始数据变动,特征数据更新的变动中,模型表征的变动,推论数据的产生等。「检测数据本身的异动,是一种防止事故的做法。」Mary McGlohon表示。

Kubernetes CKA实战培训,线下三天(北京,上海,深圳)

扫码加我微信,进群和大佬们零距离
