




在进行数据分析时,我们经常需要从大量数据中过滤出需要的数据。然而,当我们需要对多个属性进行过滤时,查询效率往往就会大大降低。另外,数据相关性和查询负载分布不均匀的存在也给查询效率带来了不小的影响。如何才能有效地解决上述问题呢?本篇文章将带来由MIT Data Systems Group发表在国际顶级的数据库会议VLDB 2021上的论文:《Tsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads》。

1.问题背景
假设我们有一张员工表,包含年龄和工资两个属性。当我们需要找出所有年龄在40-50、工资在80K-100K之间的所有员工时,我们可以向数据库发出这样的查询:select [aggregation] from table where Age>=40 and Age<50 and Salary >= 80K and Salary<100K。传统的数据库会通过建立索引来加速这个筛选过程,比如通过在年龄属性上建立索引,我们就可以很快找到所有年龄在40-50之间的员工,之后在该范围内找工资符合查询条件的即可,在工资属性上建立索引类似。然而,当需要筛选的属性数比较多时,需要访问的无效数据(即我们不需要的数据)量也会大大增长,这无疑会降低查询的效率。
另一个可行的方案是建立网格索引,该方案将每个属性划分成多个分区,最终形成多个网格。我们只需要访问与查询范围相交的网格就可以得到想要的结果,如图 1,红色部分代表无效访问区域,绿色部分代表查询区域。可以看出,网格索引可以有效地减少对无效数据的访问。
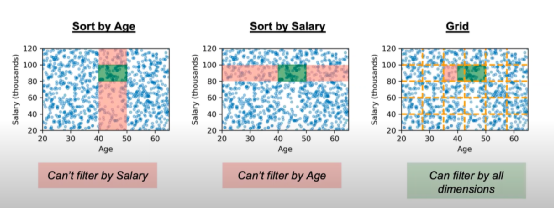
图 1 传统索引与网格索引的对比
那么,我们应该如何建立这样的网格索引呢?传统的数据结构如K-d Tree通过不断选择数据方差最大的属性作为划分属性,并以中位数为分界线将数据划分成两个不相交的区域,直到每个区域中的数据量小于阈值时停止分割。K-d Tree的一个缺点是它只与数据分布挂钩,和查询无关。也就是说,可能一些区域从未被查询,K-d Tree仍会为其维护一个索引结构,这可能会带来更大的内存和时间消耗。
相比之下,现有的多维学习索引——Flood会根据查询的工作负载优化数据布局,并且通过数据的累计分布模型来建立索引以降低查询的时间和空间复杂度。然而,Flood也存在两个巨大的缺陷,首先,Flood的优化主要针对分布均匀的查询负载,当查询的负载分布不均匀时,Flood的效率会大大下降;其次,当不同维度的数据之间存在相关性时(比如乘坐出租车的价格和乘坐距离),Flood可能会创建出数据分布不均匀的网格结构。
因此,本文提出的多维学习索引:Tsunami的目的就是在保持Flood的优势的情况下解决Flood的这两个问题。
2.基本框架
Tsunami由两个独立的数据结构组成,分别是网格树与增强网格。网格树用于将d维的数据空间划分成若干数量的不重叠区域,在每个区域内,都会存在一个叫做增强网格的结构,该结构包含多个单元,每个单元用于索引对应物理区域内的数据。网格树用以解决Flood中查询负载分布不均匀带来的问题,增强网格用于解决Flood中数据相关性带来的问题。如图 2所示,Tsunami通过网格树将数据划分成R1、R2、R3三个区域,并在每个区域内使用独立的增强网格。训练时采用完整的数据集和抽样的查询集。
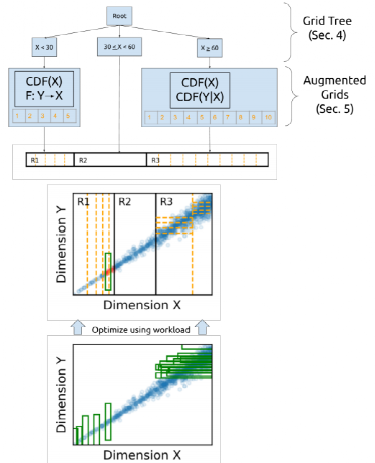
图 2 Tsunami的结构
3.网格树
查询负载分布不均匀称之为查询倾斜,如图 3所示,在2019年之前,查询范围往往在Year上跨度较大,而在Sales上跨度较小,在2019年之后情况又与之前相反,这种现象就是查询倾斜,即查询的特征在不同的数据空间范围内不尽相同。
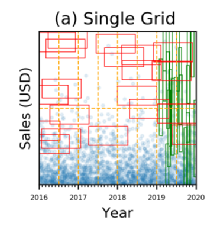
图 3 查询倾斜
网格树的目的就是尽量减少查询倾斜,为此我们需要量化查询倾斜。论文中将每个维度上的查询范围的概率密度函数与该维度上的均匀分布函数之间的EMD距离作为查询倾斜的值。概率分布函数为连续的函数,但在实践中,采用离散的方式来估计概率分布函数。如图 4所示,EMD距离可以看作是两个概率密度函数之间的蓝色部分的面积。
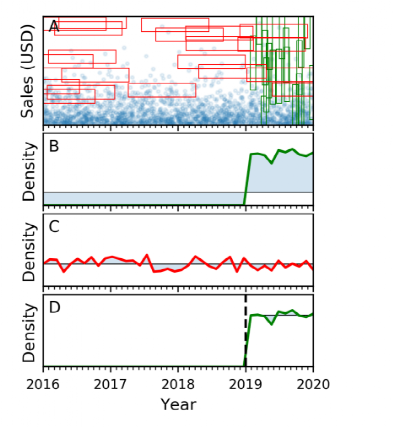
图 4 EMD距离
Tsunami通过将划分数据空间来减少查询倾斜,如图 3所示,如果我们以2019年为界将数据空间划分成两部分,我们可以得到如图 5的结果:
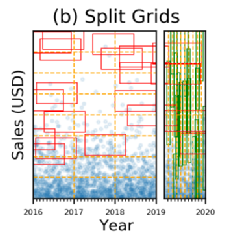
图 5 数据空间划分
可以发现,在划分后的每个数据空间内,查询特征都十分相似。分割前后的EMD距离比较可以参考图 4的B、D子图,可以发现这样划分能有效地减少查询倾斜。网格树就是用来决策如何进行数据空间划分的一个数据结构,接下来介绍Tsunami是如何建立网格树的。
通过图 5我们观察到将不同类型的查询分开可能有助于减少查询倾斜,基于该发现,在Tsunami中,查询会首先被分成不同类别,然后每个维度的查询倾斜值就可以表示成该维度内所有类型的查询倾斜值之和。Tsunami首先根据查询区域在每个维度上的覆盖范围占该维度的百分比将查询转换成向量,然后通过DBSCAN算法进行聚类,过程如图 6所示:

图 6 查询聚类
在查询分类完毕之后,Tsunami使用贪心的方式建立网格树。与K-d树类似,它每次选择一个维度进行划分,不过每次将一个节点划分成K个子节点而不仅是2个。当节点的查询倾斜小于某个阈值或节点内的数据量较少时停止划分。在每一次划分中,Tsunami为每一个维度计算当它采用最优划分值划分时得到的查询倾斜减少量,并选择减少量最大的维度进行划分。接下来介绍Tsunami如何为节点找到最优的划分值。
Tsunami采用了一个称为Skew Tree的平衡二叉树来解决这个问题。该树的每个节点代表一段区间的查询倾斜值,除叶节点外,每个节点都有两个子节点。如图 6,根节点代表区间[0, 1000)的查询倾斜值,它的两个叶节点分别代表[0, 500)和[500, 1000)范围内的倾斜值,两个子节点代表的区域是父节点代表的区域通过中点划分而来。在该树上进行动态规划即可得到最优划分值,具体步骤为:从叶节点向上记录每个节点代表的范围所能得到的最小倾斜值,之后从根节点向下找到最小值对应的节点即可。图 7中选择的节点为绿色的节点。根据这些节点就可以确定划分值,图 7中的划分值就是250、375和500。
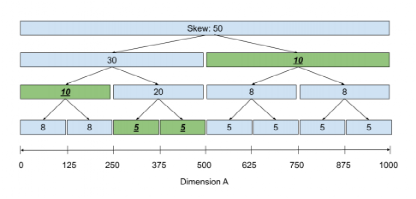
图 7 Skew Tree
4.增强网格
解决了查询倾斜带来的问题后,接下来本文将介绍Tsunami如何解决数据相关性带来的问题。
通俗来说,如果两个变量X和Y,X增大时Y单调地增大或减小,X减小时同理,那么我们称它们是相关的。比如出租车收取的费用往往和行驶的里程数相关。在存在数据相关性时,Flood的划分方案会导致各个网格之间的数据量差距较大,如图 8,左上角和右下角的网格里没有任何数据,而右上的网格内数据量较大。
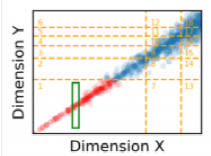
图 8 数据相关性带来的问题
一个简单的解决方案是增加分区数量,然而,仅增加分区数量会带来时间和空间上的花销增大。这里,Tsunami采用了一种新的划分策略来优化基本的网格结构,优化后的结构就是增强网格。在增强网格中,每个维度会通过以下3种划分方案分成多个分区:1) 不依赖于其它维度进行划分;2) 用其它维度代替该维度;3) 依赖于其它维度进行划分。针对所有维度的划分方案的一个实例记为Skeleton S,比如X依赖Y来划分,而Y独立于其它维度进行划分。对于每一个维度,Tsunami会为其确定分区,组成向量P。增强网格由S和P组成。
接下来具体介绍方案2)和3)。在2)中,假设有两个维度X和Y,我们要用X代替Y,即减少一个维度。当需要筛选Y维的数据时,Tsunami将其通过映射函数映射成在X维上的筛选。比如要选择年龄在40-50之间,且工资在80K-100K之间的员工,而工资在80K-100K之间的员工年龄一定位于30-45之间,那么我们只需要筛选年龄在40-45之间的员工,然后判断他的工资是否满足条件即可。根据经验,真实数据集上的相关性往往是线性相关,所以这样的映射函数可以通过简单的线性回归模型训练,然后确定好上界和下界的最大误差即可,其它类型的相关也可推而广之。图 9是该方式的一个例子,绿色区域为查询区域,实线为训练好的模型,两个虚线分别是模型加上上界的最大误差和减去下界的最大误差得到,最终的查询范围由虚线和原来的查询区域决定。
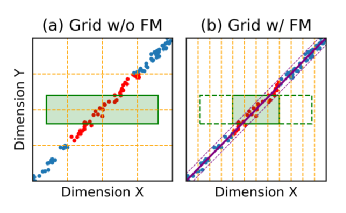
图 9 用维度X代替维度Y
在3)中(即Y依赖于其他维度X划分),Tsunami先均匀划分维度X,然后通过条件累积分布函数condition CDF(Y|X)来均匀划分Y维。如图 10所示,对于划分好的每个X分区,Y的范围不会超出白色范围,故在白色范围内均匀划分Y维度的数据即可,灰色区域由于不存在数据点可以不用建立网格结构。
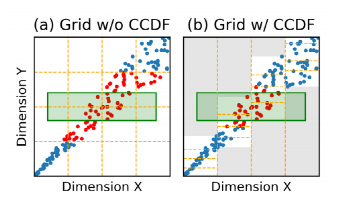
图 10 Condition CDF划分
由于S的搜索空间为指数级,不能简单地遍历得到最优划分方案。于是Tsunami采用自适应梯度下降得到最优解。优化的目标是使得处理查询的时间最小,这里使用简单的线性模型计算该时间:

在知道S和P后就可以很容易计算这个式子。自适应梯度下降的步骤如下:1) 采用启发式算法,得到初始的划分方案S0和各个维度的分区数量组成的向量P0;2) 固定S0,对P0进行梯度下降,得到更优解P1;3) 固定P1,对S0进行搜索,这里的搜索只会简单地改变1个维度,如表 1,得到更优的S1,;4) 重复2)、3)步骤直到查询时间最小。
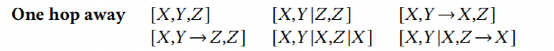
表 1
5.实验评估
实验使用带有Intel Core i9-9900K 3.6GHz CPU和64G内存的计算机在Ubuntu下进行验证,使用C++和Python语言实现Tsunami。数据集的具体参数如表 2:
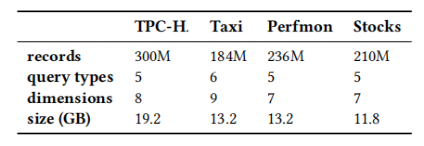
表 2 数据集
实验首先对比了Tsunami和Flood建立的索引所占用的内存,结果如表 3,可以看出Tsunami建立的索引是轻量级的。
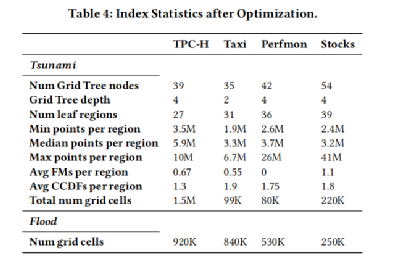
表 3 索引大小对比
接着实验评估了Tsunami和其它的索引方案在分别处理四类数据集的时间开销和空间开销,结果如图 11所示,可以看出Tsunami查询快且内存友好。
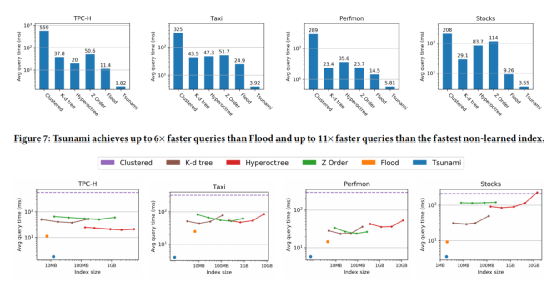
图 11 与其它索引方案对比
接着实验评估了Tsunami和Flood在查询负载变化时重新调整索引需要的时间,结果如图 12所示,可以看出Tsunami能够很快地响应查询负载的变化。
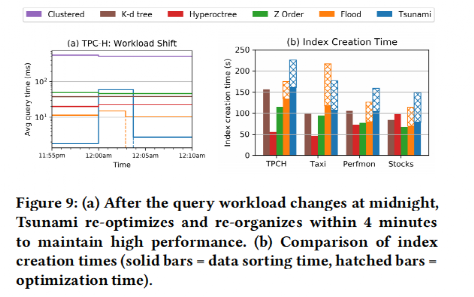
图 12 查询负载改变
接着实验评估了Tsunami和其它索引在维度、是否存在数据相关性、数据量和数据选择性变化时的查询效率,结果如图 13和图 14所示。可以看出在Tsunami很好地解决了数据相关性带来的问题(Flood在存在数据相关性时表现不稳定),且在多种约束下表现良好。
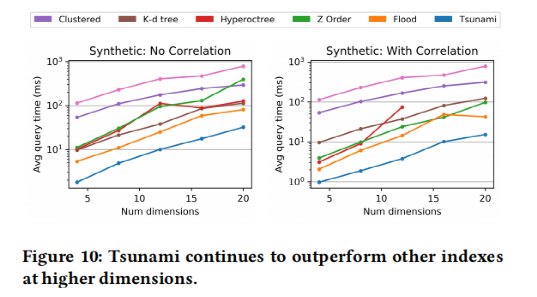
图 13
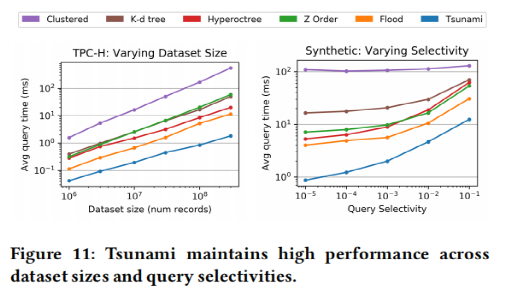
图 14
最后,实验评估了Tsunami中提出的每一种算法对于整个系统的影响,结果如图15所示,可以看出论文中提出的算法均有利于提高查询效率。
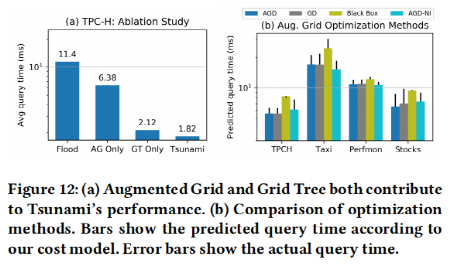
图 15
重大时空团队(CUST,Chongqing University Spatio-Temporal Lab)发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!目前尚有两个研究生名额,欢迎计算机、GIS等相关专业的学生报考!
