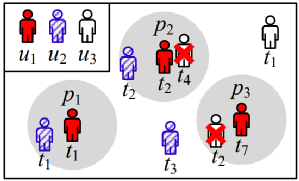
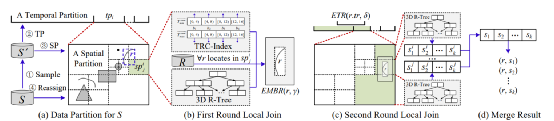
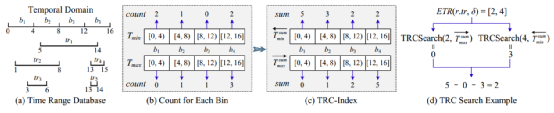
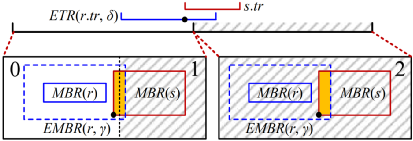
在两轮局部连接操作之后,我们在每个ST分区中获得了r的局部kNN结果。为获取全局结果,我们需要对局部结果进行合并操作。在合并过程中,需要利用shuffle操作,将相同r的局部结果重新分区到一个新分区后组合成全局结果。一个对象会被分配到多个ST分区,所以在不同的结果中可能存在重复的组合。为了减少网络传输的资源消耗,本文采取先删除重复项再进行重新分区。如图5所示,假设出现如下组合(r, s)出现在时空分区0,1,2中,我们将r的ETR和s相交部分的开始时间称为时间参考点(temporal reference point, TRP),将r对应的EMBR和s所在的MBR相交的左下角点称为空间参考点(spatial reference point, SRP)。我们只保留同时包含TRP和SRP的时空分区内的结果(即图5中保留时空分区0)。图5:删除重复项
5.实验评估
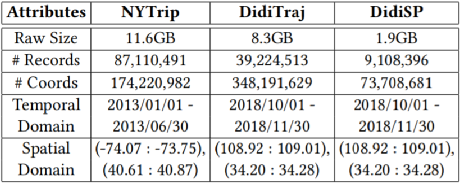
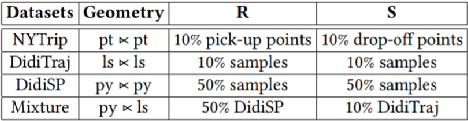
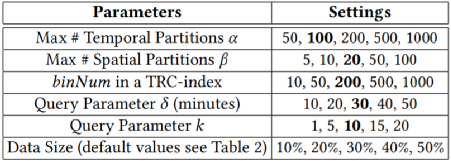
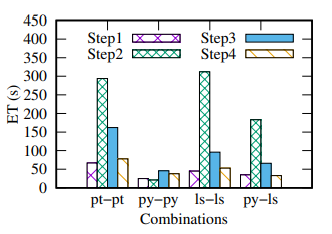
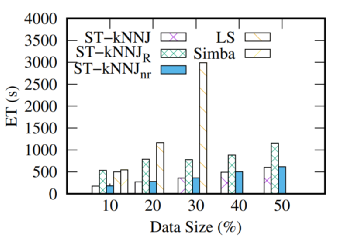
我们使用三个真实的数据集来验证ST-kNN Join的效果,数据的统计如下表1所示。表1:静态数据集表2显示了用来测试参数的几何组合,旨在找出引入参数的影响。表2:用于参数测试的几何数据集表3为实验中测试的参数,默认值用黑体表示。表3:参数设置我们采取控制变量的方法,对表3中每一个参数进行测试。主要记录不同数据的执行时间(Execution Time, ET)、R和S的复制扩增(Copy Amplification, CA)和命中率(Hit Rate, HR)三个方面。结果如下图表示。我们可以明显看出在划分时空分区的时候需要选择合适的α,β参数,参数过小使得分区内的执行时间长,而参数过大使得时空分区过小从而降低命中率。binNum的增加可以提高TRC-index的精确度,而且TRC-index是轻量级索引,本身对资源消耗可以忽略不计。图6:关于参数α的影响图7:关于参数β的影响图8:关于参数binnum的影响图9:关于参数𝛿的影响图10:关于参数k的影响我们还对每一种几何数据每一步的运行时间进行了记录,如下图。明显看出多数情况下,第一轮本地连接的执行时间较长,因为这个阶段我们要进行索引的构建。此外,py-py组合在第一轮本地连接时的执行时间远小于其他数据类型。可能是因为滴滴的时空数据集分布稀疏,亦或者因为其数据量较小。图11:各种数据集每一阶段的效率我们对比了各种框架下的效率。ST-kNNJ是本文提出的最终框架。我们重写了Simba和LocationSpark两种框架的代码,使其支持进行ST-kNN Join的计算。将这两种框架和本文的框架(ST-kNNJ)以及采用R树的ST-kNNJR和不进行合并优化的ST-kNNJnr进行比较,结果如下图所示。可明显看出相比其他框架,ST-kNNJ有着不错的效果。图12:各种框架效率系统Demo链接:http://stknnjoin.urban-computing.com/关注公众号,回复"ST-kNNJ",下载PPT和论文 重大时空团队(CUST,Chongqing University Spatio-Temporal group)吸收企业和高校的优势,深入探索时空数据接入、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!目前尚有两个研究生名额,欢迎计算机、GIS等相关专业的学生报考!