




隐私计算是“隐私保护计算”(Privacy-PreservingComputation)的中文简称,没有统一的标准定义,这里摘取部分组织和文档的定义,基本表达了同样的意思:
1、中国隐私计算产业发展报告(2020-2021):
隐私计算是指在提供隐私保护的前提下实现数据价值挖掘的技术体系,而非单一技术,早期多被定义为隐私保护计算、隐私保护技术等。2016 年发布的《隐私计算研究范畴及发展趋势》正式提出“隐私计算”一词,并将隐私计算定义为“面向隐私信息全生命周期保护的计算理论和方法,是隐私信息的所有权、管理权和使用权分离时隐私度量、隐私泄漏代价、隐私保护与隐私分析复杂性的可计算模型与公理化系统。
2、隐私保护计算技术研究报告:
隐私计算是指在提供隐私保护的前提下,实现数据价值挖掘的技术体系。面对数据计算的参与方或意图窃取信息的攻击者,隐私保护计算技术能够实现数据处于加密状态或非透明(Opaque)状态下的计算,以达到各参与方隐私保护的目的。隐私保护计算并不是一种单一的技术,它是一套包含人工智能、密码学、数据科学等众多领域交叉融合的跨学科技术体系。隐私保护计算能够保证满足数据隐私安全的基础上,实现数据“价值”和“知识”的流动与共享, 真正做到“数据可用不可见。”
3、大数据联合国全球工作组:
隐私计算是一类技术方案,在处理和分析计算数据的过程中能保持数据不透明、不泄露、无法被计算方法以及其他非授权方获取。
4、腾讯隐私计算白皮书2021:
隐私计算(Privacy Computing)是一种由两个或多个参与方联合计算的技术和系统,参与方在不泄露各自数据的前提下通过协作对他们的数据进行联合机器学习和联合分析。隐私计算的参与方既可以是同一机构的不同部门,也可以是不同的机构。
由上可知,在隐私计算框架下,参与方的数据不出本地,在保护数据安全的同时实现多源数据跨域合作,可以破解数据保护与融合应用难题。
隐私保护计算架构可抽象为下图,在隐私保护计算参考架构中,主要有数据方、计算方和结果方三类角色,数据方是指为执行隐私保护计算过程提供数据的组织或个人;计算方是指为执行隐私保护计算过程提供算力的组织或个人;结果放是指接收隐私保护计算结果的组织或个人。
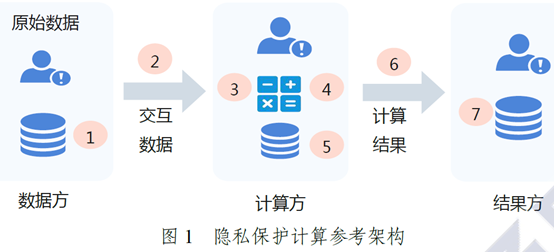
隐私保护计算的目标是在完成计算任务的基础上,实现数据计算过程和数据计算结果的隐私保护。数据计算过程的隐私保护指参与方在整个计算过程中难以得到除计算结果以外的额外信息,数据计算结果的隐私保护指参与方难以基于计算结果逆推原始输入数据和隐私信息。
从技术机制来看,隐私计算主要分为三大技术路线,即安全多方计算(密码学)、联邦学习及机密计算,有的会把侧重算法也单列一类,比如差分隐私等隐私相关的技术.
可以看到,隐私计算是个技术体系,不能混淆了安全多方计算、联邦学习、隐私计算概念间的关系,比如安全多方计算只是隐私计算的一个子集,联邦学习与安全多方计算也不是同一回事,虽然彼此也有联系。
隐私计算使企业在数据合规要求前提下,能够充分调动数据资源拥有方、使用方、运营方、监管方各方主体积极性,实现数据资源海量汇聚、交易和流通,从而盘活第三方机构数据资源价值,促进数据要素的市场化配置,在《国家数据安全法》颁布的当下,隐私计算更凸显价值。
隐私计算其实是一堆“数据可用不可见”技术集合,包括多方安全计算、联邦学习、机密计算、差分隐私及数据脱敏等等,这些技术既有联系又有区别,既有优势也有劣势。
