




在过去的一两年时间中,我们为大家推出了几个手把手系列的教程。在2022年的春天,我们将为您继续提供新的手把手系列教程,让我们从OCI Vision服务开始。在不久前,Oracle推出了运行的OCI上的机器视觉服务,里面包含图像分类、对象检测、文本检测、文档分析等服务。在此之前,如果我们想做相关的分析,我们需要用很长的时间来配置环境,在配置过程中要考虑多种组件的兼容性问题,这是一个痛苦且漫长的过程。在几年前,业界就推出将AI作为一种云端服务提供给开发者和数据科学家,让大家将更多的精力放在数据探索和创新上,而不是为底层的基础架构和环境设置而烦心。目前主流的云提供商,都使用了一种“人工智能即服务(AI as a Service)”的理念,于是去年我完成了一本《AI as a Service》的书,并将在今年出版,在书中提到了很多利用人工智慧的云原生服务,利用这些服务可以大大降低数据科学和图像分析的门槛,让没有相关基础的人,也能够很快利用这些先进的技术完成相关的探索与分析。在本系列的文章中,我将通过3个例子,为您介绍AI即服务中的机器视觉技术,您可以使用Oracle OCI Always Free作为您的实验环境,当然AI即服务在其他云提供商也有供应,您可以根据自己的情况选择环境,但别担心,不同云服务商提供的AI服务在操作上都很简单。

在今天的内容中,我们将为您介绍通过OCI控制台来访问Vision服务,并且为您介绍我们将使用到的数据及其格式。将通过演示数据集为您展示Vison服务的能力,同时为您展示如何将数据上传到Oracle对象存储中,以供日后训练自定义模型时使用。今天的实验目标如下:
了解分析图像的数据要求和数据格式。
将示例数据集上传到 OCI对象存储中。
熟悉 OCI 控制台,并了解Vision服务的主要功能。
现在我们将开始我们的实验。
1、环境设定
在使用OCI Vision服务之前,我们首先要在云端对您的账户做一些基本的设置,这是一个非常简单的步骤,您可以点击几下鼠标即可完成,因为我们在OCI当中提供了Vision的模板。
首先请使用管理员身份登录OCI,通过左上角的导航按钮,来到资源管理,如下所示。
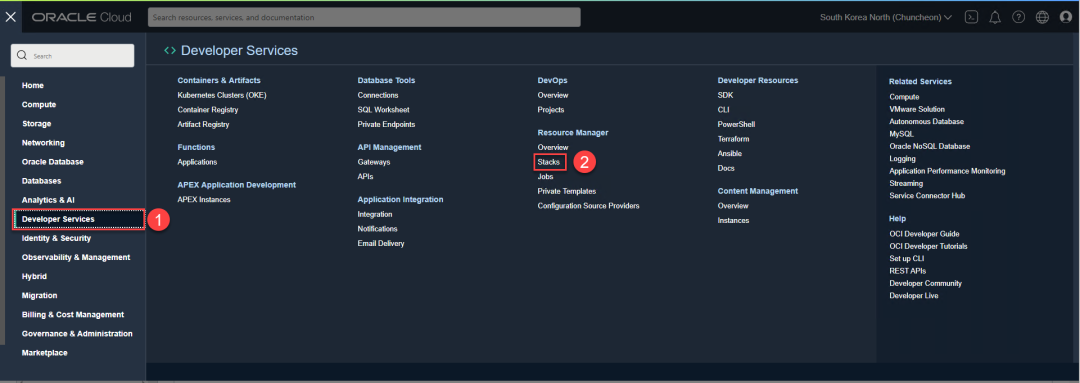
然后点击Create Stack来创建stack。
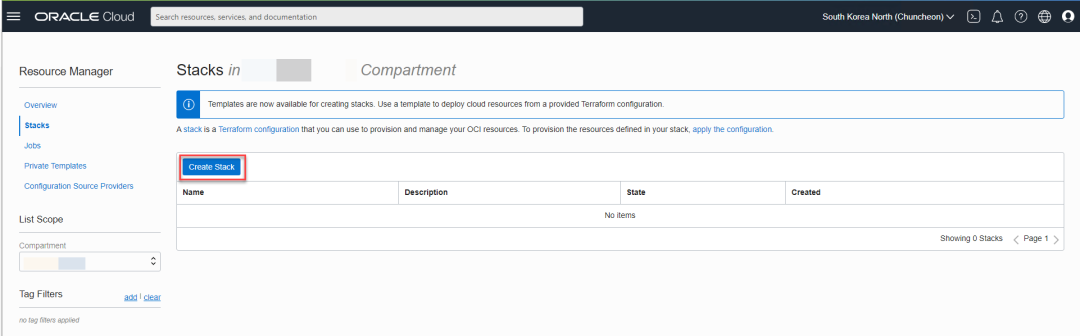
然后按照下图所示,选择模板,然后选择Vision模板。
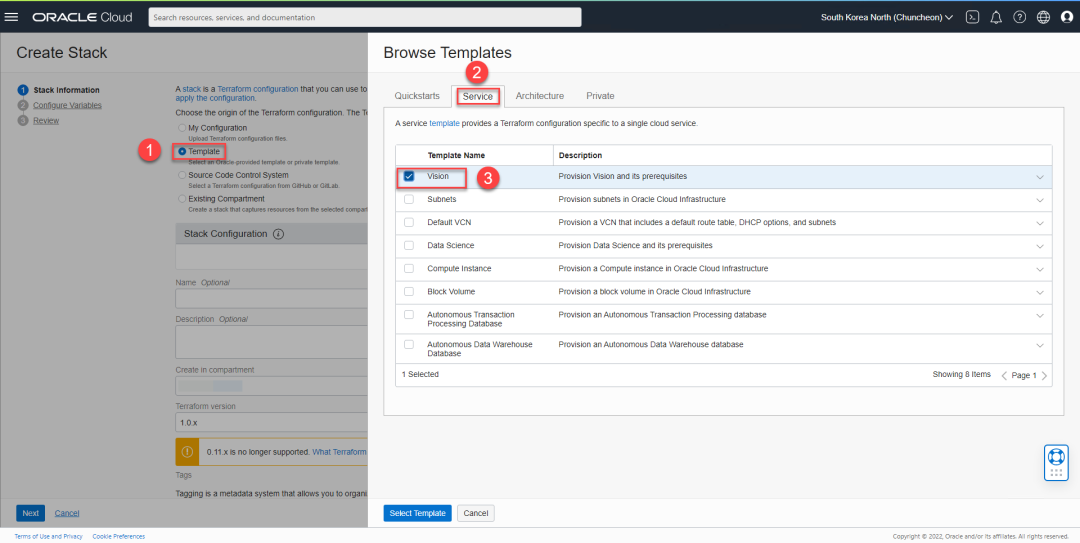
在选择完模板之后,给出Stack名称,并点击下一步。
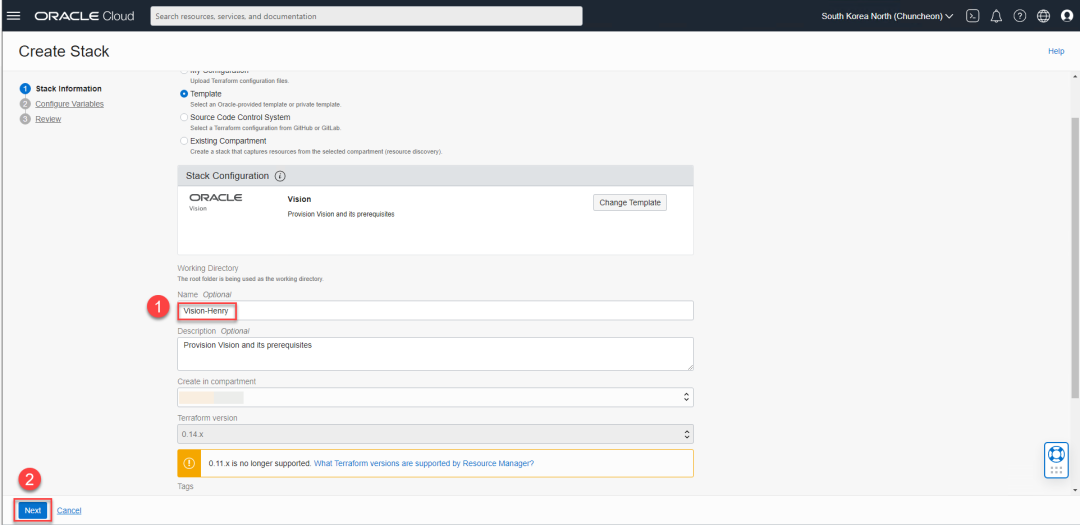
在下面的界面中,您将设定访问权限及策略,您可以保持IAM Group and Policy Configuration使用默认配置即可,如果您需要训练自己的模型,并且通过批处理的方式运行,请按照下图中红框所示,将这两个项目选中,然后点击下一步。
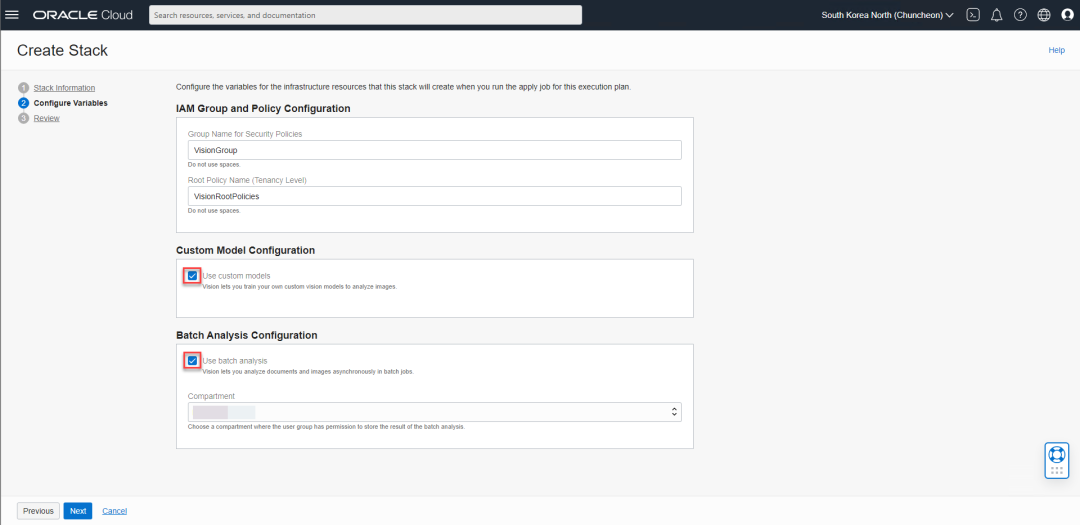
在下面的确认界面,确认无误后,点击Create按钮即可,这个创建过程可能需要几分钟的时间。
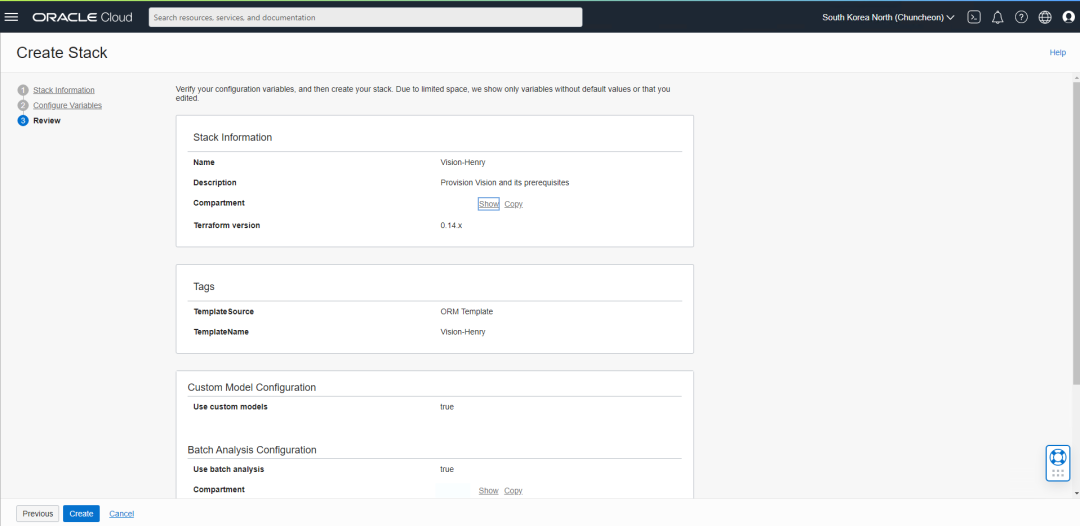
看到下面的界面,就表示您的准备工作已经完成。
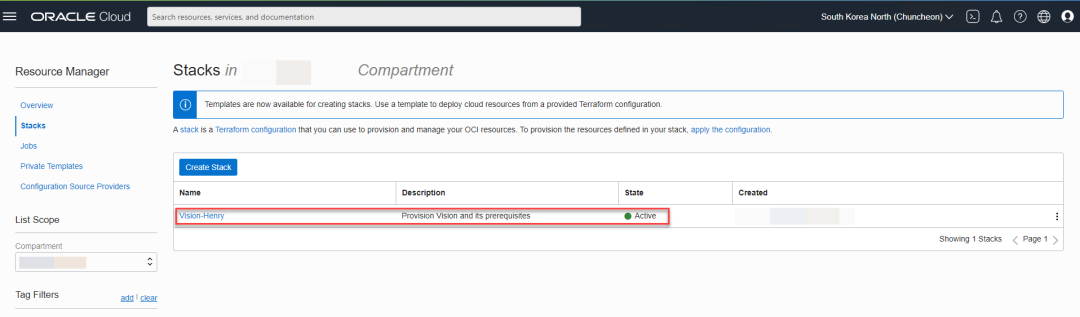
2、了解Vision接受的数据类型
Vision服务支持多种数据格式的图形,可以提供检测对象、为图像分配标签、提取文本等功能。该服务可以对OCI控制台上传的数据,或者存储在Oracle对象存储中的数据进行处理。Vision服务也提供同步和异步API,具体说明如下:
API | 说明 | 支持的图形格式 |
同步API,analyzeImage, analyzeDocument | 分析单个图像 |
|
异步API /jobs/startImageAnalysisjob /jobs/start | 分析多张图片或者多页的PDF文件 |
|
3、将文件上传到对象存储
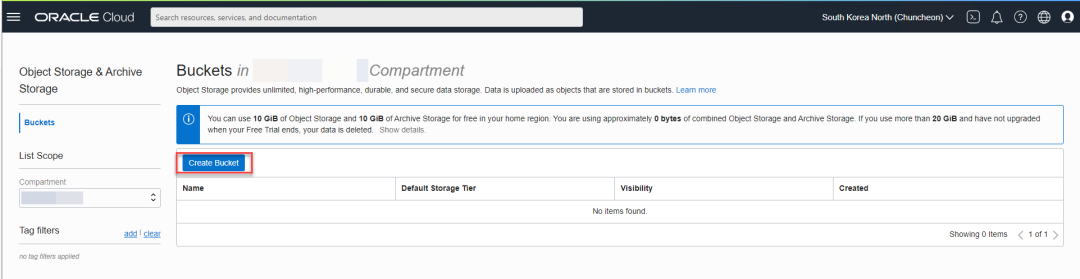
这不是一个必须的步骤,但如果您打算训练自己的模型,或者一次处理大量图像,将文件放入OCI的对象存储是一个很好的选择。创建并使用对象存储的步骤很简单,就像您平时使用“网盘”一样。首先导航到对象存储,如下所示:
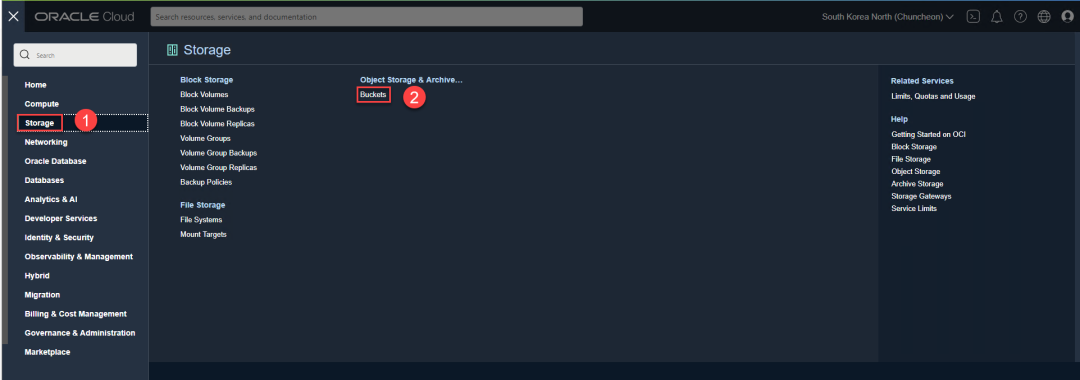
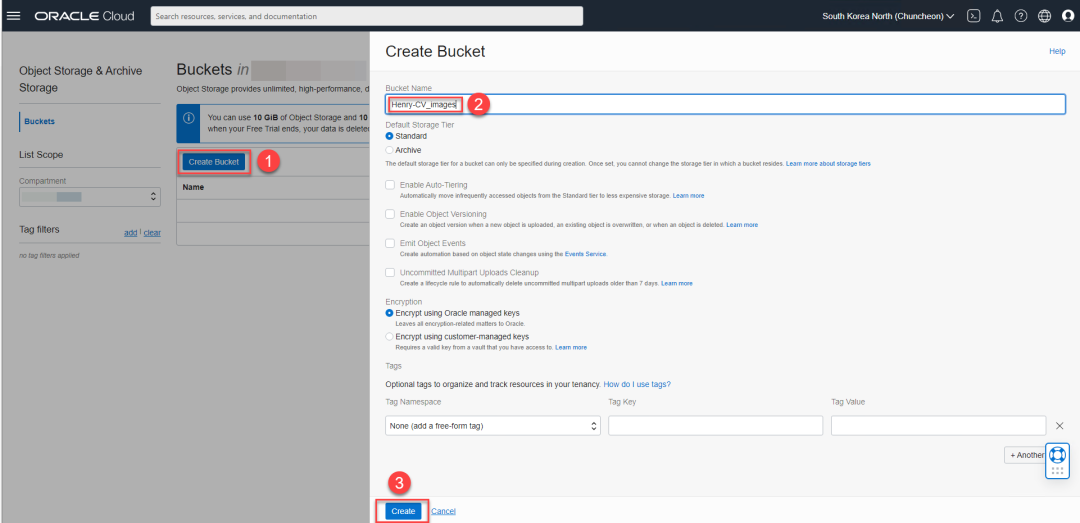
创建bucket
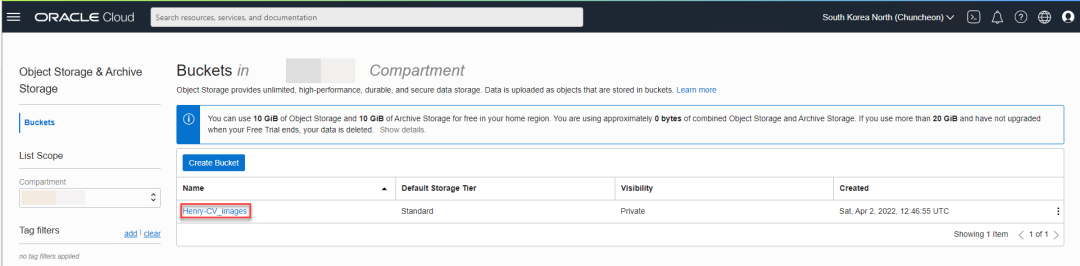
点击下面红框中的链接,上传文件。
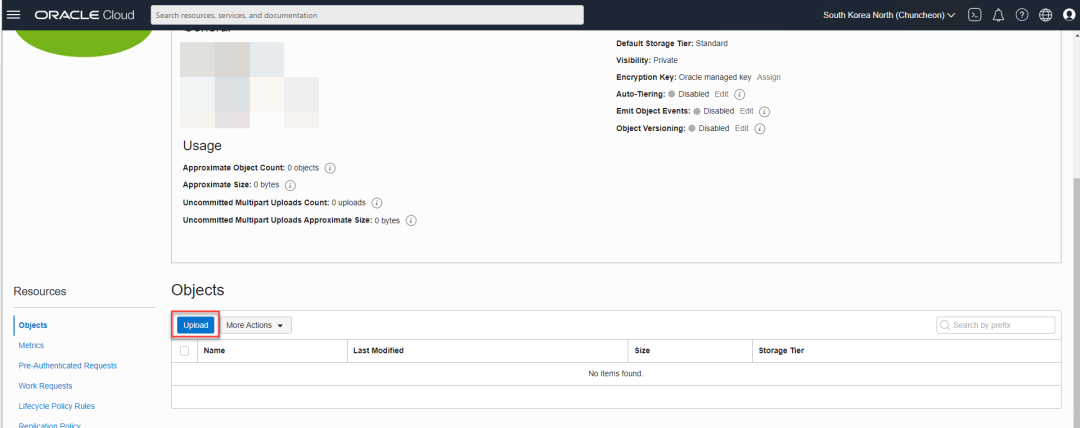
为了稍后进行实验,您可以上传一些图片在bucket当中,或者上传单页的PDF文件。
4、在OCI Console当中使用Vision服务
您可以通过导航菜单,来到Vision服务。
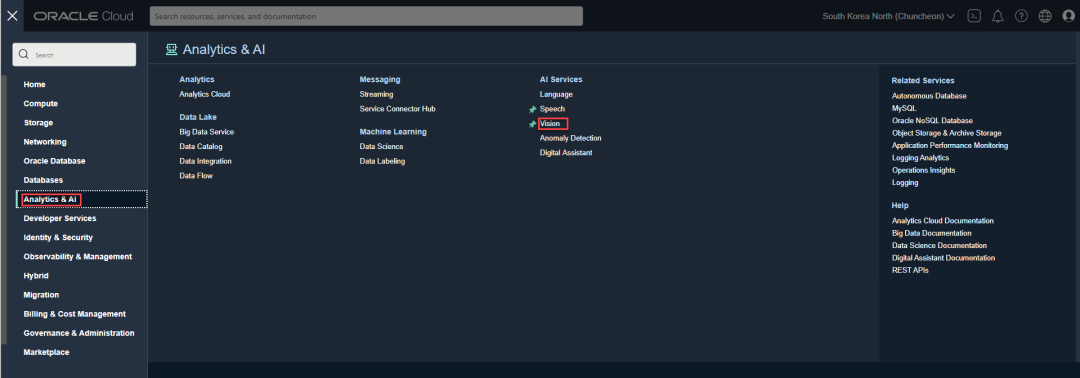
目前在Vision当中提供图像分类、对象检测和文档AI三个默认服务,您也可以创建自己的项目,并训练自己的模型,从而扩展Vision的功能。
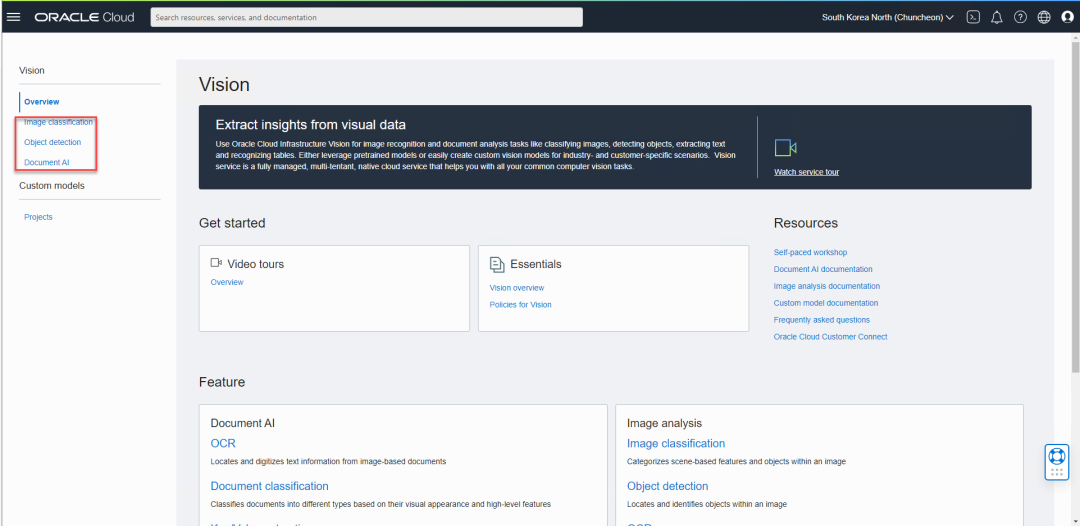
我们首先看看图像分类,在界面中,您可以从本地上传图片,或者使用刚才您放在OCI对象存储中的图片,如果是使用对象存储中的图片,请给出图像的完整地址。在下面的示例中,我们从本地上传一张图片,看看效果。通过观察右侧结果框,Vision已经成功识别出图中的主要物体,比如学校的吉祥物雕像以及我的手。默认情况下会给出5个置信度最高的标签,通过观察,我们发现这5个标签的置信度都在90%以上。这是因为OCI中的模型在发布之前,做过大量的训练,所以我们在这里看到的效果要比我们自己搭建模型的效果好很多,毕竟对于初始模型,我们无法花费大量的时间和算力,用海量的数据去训练我们的模型。
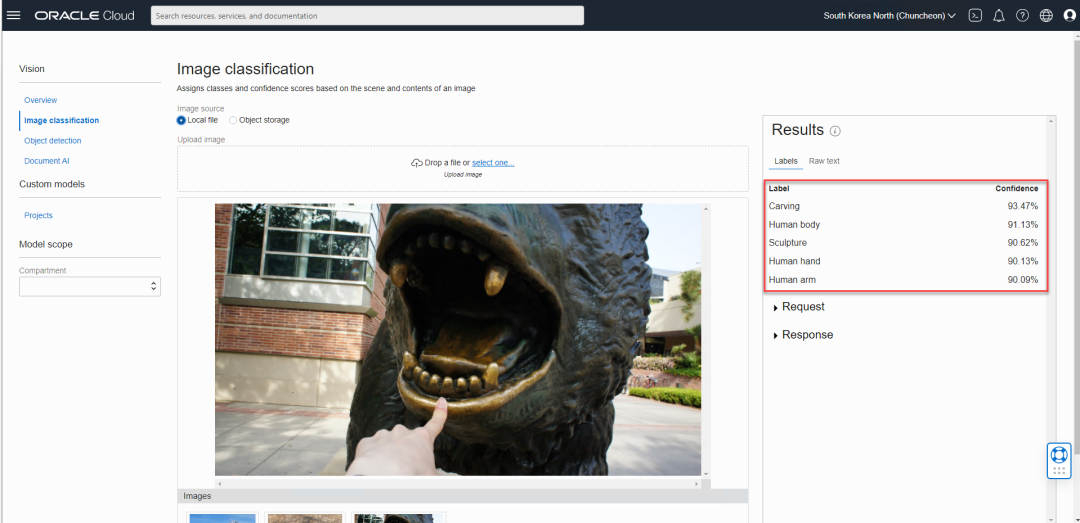
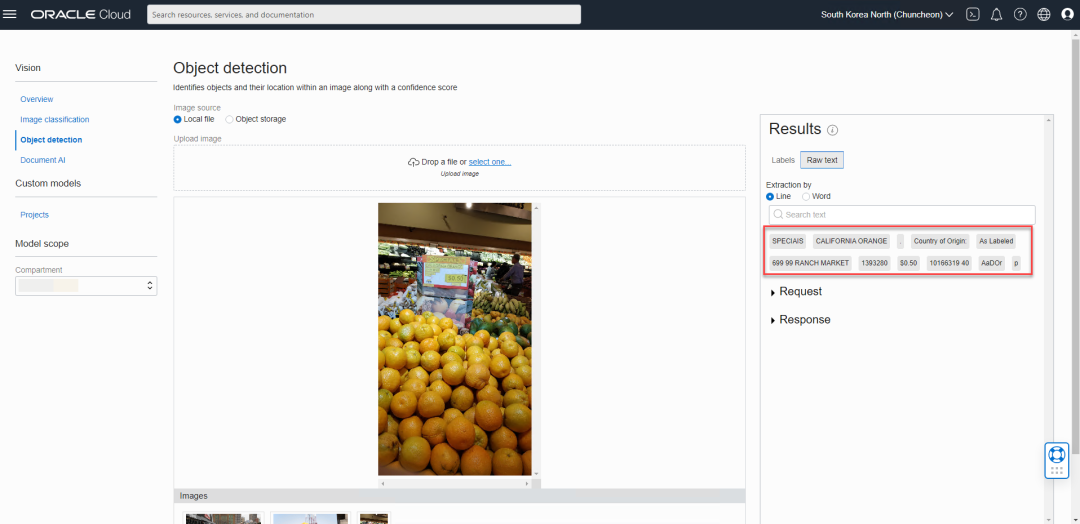
接下来我们看看对象检测功能,我们上传一张超商中的随手拍,图中主要是橙子,以及价签。但系统也检测出图中的人形,通过右侧的结果框可以看到,人形的置信度很高,但是橙子的置信度稍低,为86%左右,因为柑橘类水果有非常多的品种,而且它们的外表都很相似。如果您对这个识别结果不满意,您可以收集与橙子相关的图片,并对它们进行标记,然后训练您自己的专门识别橙子的模型。
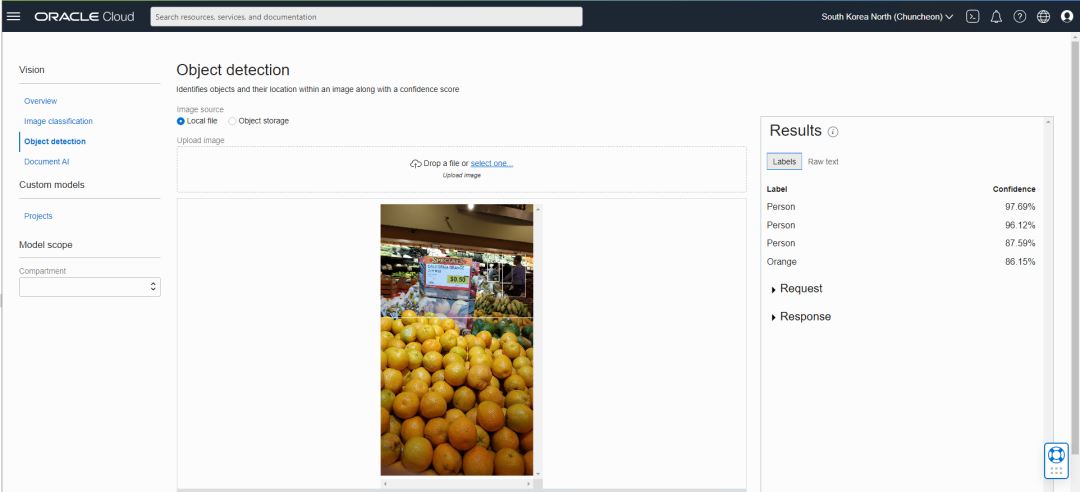
在结果框中,还有RAW text,显示图像中的纯文本,我们可以看到它已经成功地识别出橙子的价格是每磅50美分以及超商的名称。
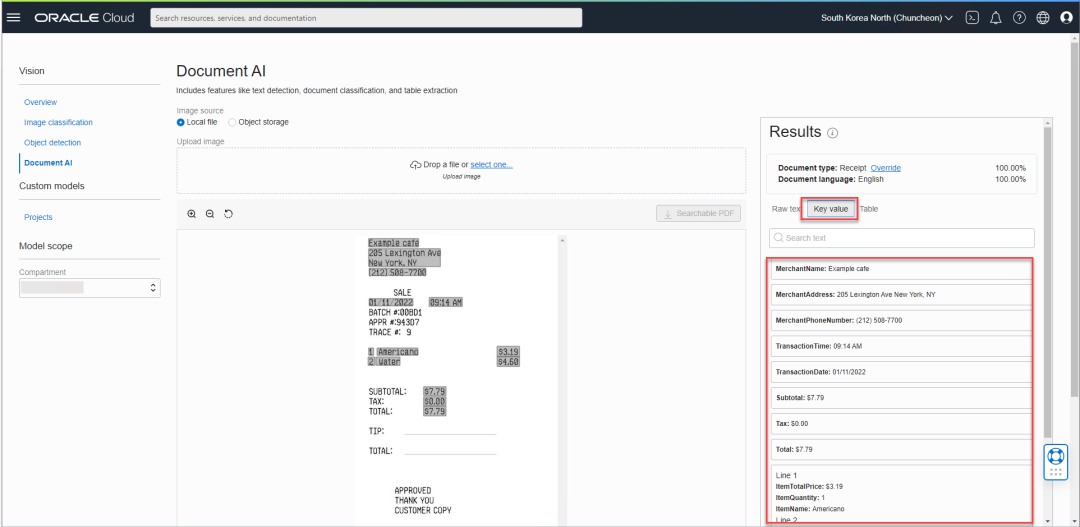
最后,让我们看看文档AI功能,它可以对图像中的文档进行自动的分析与归类,比如下面的收据,Vision可以成功分析出,该图像的文档类型是收据,文档中的语言是英语,然后在下面的key value部分,自动分解图像中的信息,比如商户名称、商户地址、联络电话等信息。
今天的内容就到这里了,我们为您介绍了通过OCI控制台了解Vision的主要功能,而在实际工作中,我们更多的是将Vision通过API与Data Science Service结合使用,这样才能最大限度地发挥出Vision的真正能力。下一次,我们将为您介绍如何创建自己的模型,以及如何将Vision与Data Science结合在一起,进行综合数据分析。
编辑:殷海英


