






1.前言

2.Hype Cycle 2021
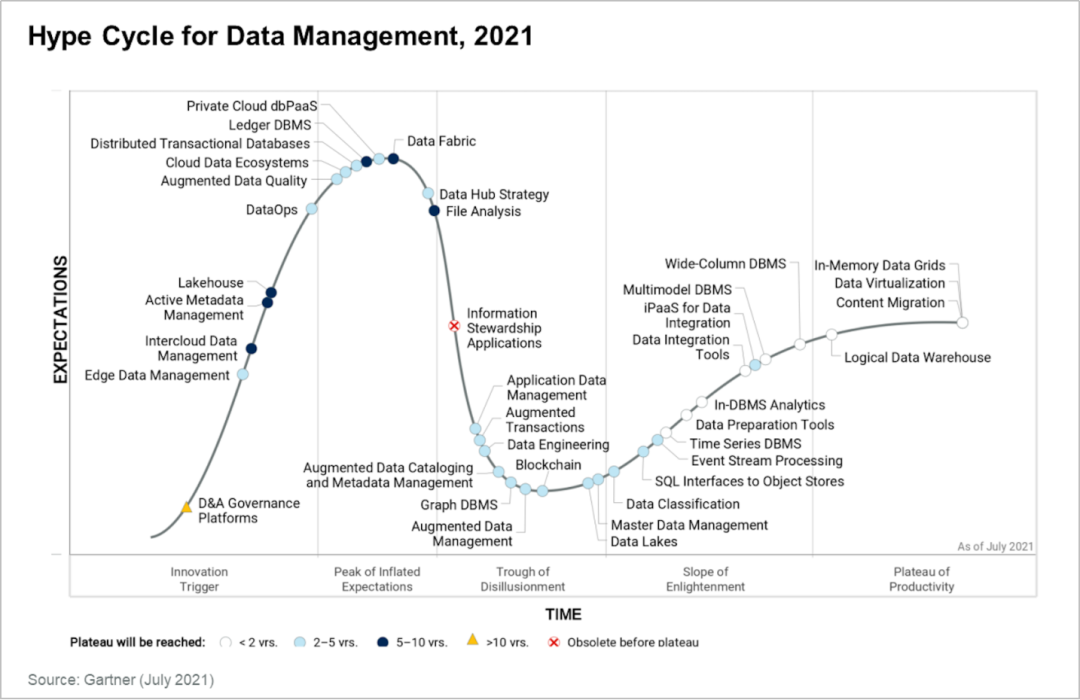
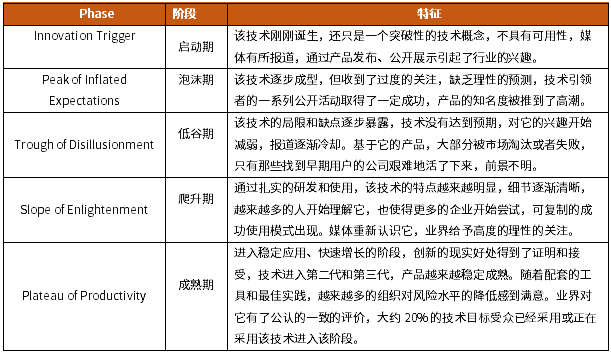

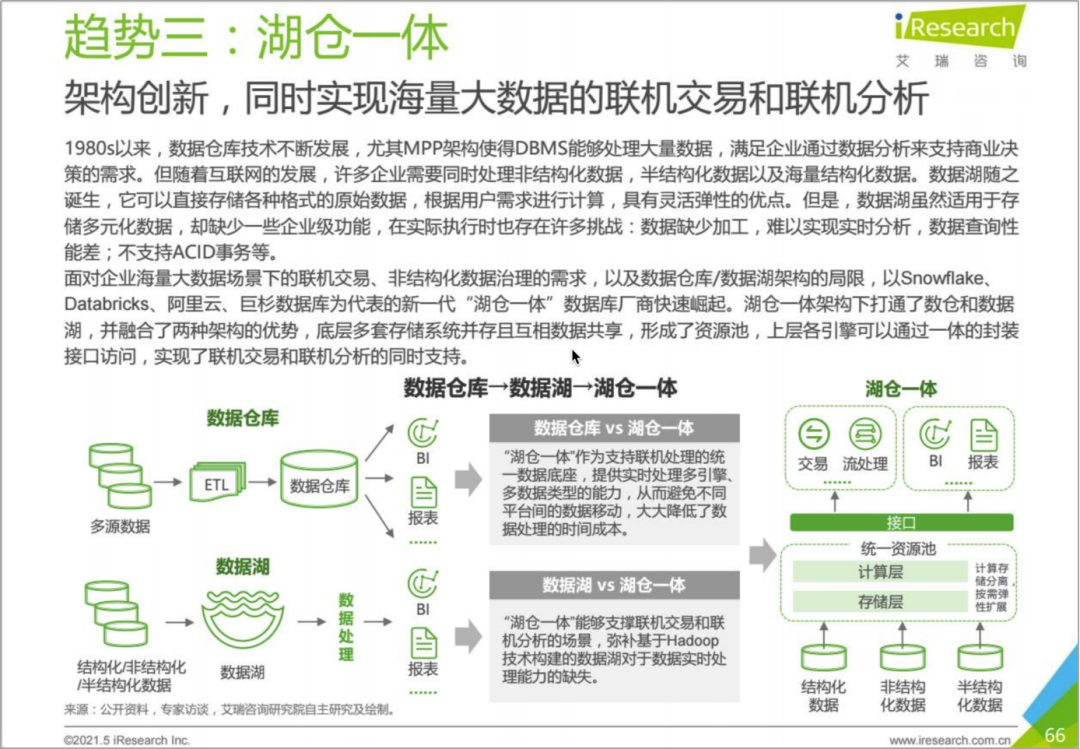
3.Gartner对于「湖仓一体」的分析
「湖仓一体」将数据湖的语义灵活性与数据仓库的生产优化和交付相结合。它是一个融合的基础设施环境,支持从原始数据到精炼数据的整个过程,并最终提供优化后的数据以供消费。
数据和分析领域的头部企业,致力于数据湖的构建并从中获得价值。但是,目前数据湖与数据仓库独立部署、同时存在的形态,无疑增加了数据和分析领域的复杂性。「湖仓一体」旨在实现两种架构的统一,最大限度地降低了数据迁移的需求和AI/ML建模的复杂性,来实现效率的提升,提供了一个更简化的数据处理环境。
「湖仓一体」,将使业务从简化的交付流程、数据的快速访问中受益,同时满足了用户对于性能和易用性的更高要求。通过构建整合的数据管理平台,服务于各种各样的职能角色,包括专业的数据科学家、数据工程师和业务分析师等,甚至包括通过数据看板来使用数据的临时用户。「湖仓一体」本质上为数据科学的创新提供了定义明确、可落地的发展途径。
数据科学项目,往往难以在生产环境中落地投产。「湖仓一体」实现了研究探索和生产交付的统一,从而缓解了这些问题。
企业一直希望能够快速、平滑地访问数据,但往往受限于数据仓库中数据处理的复杂流程以及交付的延期,而「湖仓一体」正是解决这个问题的“银弹”。
数据湖和数据仓库,原本是应对不同业务场景而产生的技术,并做了针对的特性优化。而现在,很多时候还要考虑对灵活性(兼容性)的兼顾。如果这样的话,独特性必然要做出牺牲,而且仍需要通过技术手段去弥补二者的差异。企业正在寻求这样的平衡点,而「湖仓一体」的出现,使这种界限变得模糊。
很多云数据仓库,及绝大多数的云数据湖提供商,选择云对象存储作为其存储方案,形成了灵活多样的访问接口。为了消除这种分散、重复建设的现状,技术的统一将成为必然。
在支持数据科学、预测建模和机器学习等方面,目前大多数云数据仓库,都没有对强大的DBMS分析功能进行很好的集成。「湖仓一体」方法提供了这些功能。
「湖仓一体」解决方案的成熟度仍在发展中。许多解决方案还不能全方位支持事务一致性或较为完善的工作负载管理功能,而这些能力是数据管理和数据分析业务所需要的。
目前大多数「湖仓一体」解决方案,在面临最复杂的数仓业务负载时,仍可能有一定差距。
用户对于复杂数据架构的设计、部署和维护能力也不成熟。这虽然不是技术问题,但同样是一个显著的挑战。
「湖仓一体」的很多配套能力还有待优化提升,包括数据质量管理、安全性、数据治理和性能等方面。
4.「湖仓一体」在国内外的技术探索

在国外,Snowflake、Databricks等数据库公司,作为「湖仓一体」理念的先行者,凭借其前沿的技术特性和丰富的技术生态,获得了迅猛发展,已经成为了「湖仓」领域的技术引领者。国内方面,巨杉SequoiaDB作为原生的分布式数据库,凭借多年的产品打磨和行业深耕,已经有了较为成熟的「湖仓一体」落地案例。
此外,随着越来越多企业客户的IT架构从本地数据中心转向云端,云原生正在成为新一代数据架构的主流标准,大数据领域也将加速“一体化”新方向的演进。各大云厂商陆续提出自己的「湖仓一体」技术方案,同样受到了业界的普遍关注,我们也因此看到了更多的技术探索案例。
4.1 Snowflake
Snowflake,是完全构建在云上的企业级「湖仓一体」解决方案。它基于云环境进行了根本性地重新设计,处理引擎和其他大部分组件均为自主研发。Snowflake从2012 年开始投入研发,到 2015年6月完成了初步商用。目前,Snowflake 已经被越来越多的组织采用,每天承载PB级的数据存储及超过上千万次的查询。
Snowflake本是「云数仓」提供商,主要面向结构化及半结构化的数据分析。伴随着Lakehouse概念的诞生,Snowflake逐步增强其数据湖相关能力,例如第三方数据源接入、IoT/流处理等多种工作负载,以及已经实现的跨云部署等。2021年6月,Snowflake更正以Private Perview的方式对部分客户提供Unstructured Data非结构化数据的存储及处理能力的技术预览,以解锁全新的数据价值。

4.2 Databricks
Databricks早期,是将Azure的云存储挂载为DBFS(Databricks File System),借助Spark的计算实现基本的表存储和SQL简单处理。而到了现在已经提供了基于SQL/Python/R/Scala的成熟BI工具,并在AI和ML的扩展支持方面做了大量的投入。
Databricks现已经支持AWS、Azure、Google三家公有云,且部署在全球超过50个Region。相比于Snowflake,Databricks的发展路径,更接近于从数据湖逐步走向「湖仓一体」。Delta Lake 及 Delta Engine是Databricks的两大重要组成部分。
Delta Lake作为可靠的开源存储层,与 Apache Spark API完全兼容,提供ACID事务,且支持可缩放元数据处理、版本管理、Schema管理、审计等一系列数据管理功能等,可轻松实现流处理和批数据的统一。此外,可以根据实际工作负载对Delta Lake进行灵活地配置。
Delta Engine作为高性能的数据处理引擎,提供了对Apache Spark的良好兼容性。Delta Engine在数据查询方面的全面优化,可加快数据湖的操作效率,并支持丰富的工作负载类型,从大规模ETL处理到交互式查询均可胜任。Databricks典型部署架构如下:

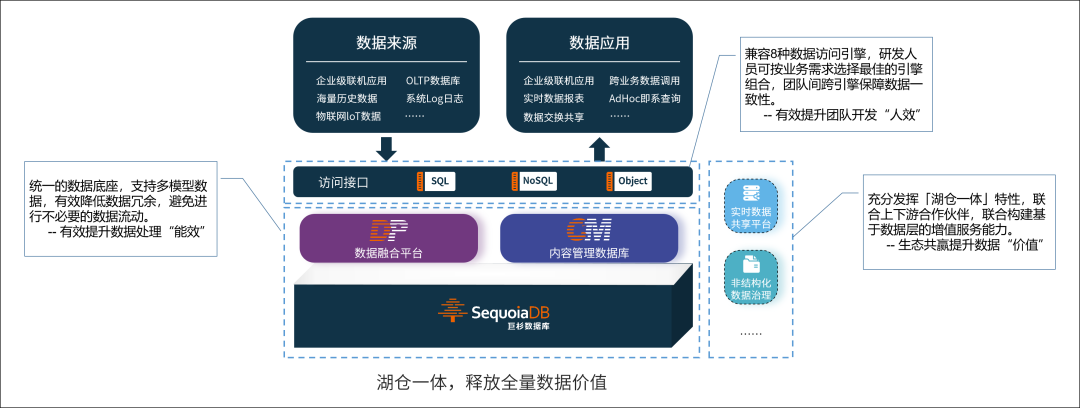
4.3 巨杉SequoiaDB,湖仓一体数据平台
基于100%自研的分布式数据库内核,巨杉数据库SequoiaDB提供了「湖仓一体」数据平台。目前在银行、保险、证券等各行业,已经拥有丰富的最佳实践及案例,帮助客户构建起数据平台最佳底座。

5.结语
伴随着20年的大数据发展史,我们看到了数据湖与数据仓库的不断发展和创新,业界也认识到以湖仓一体化为核心的技术架构,对企业大数据的价值发挥带来了更为重要的现实意义。
数据湖和数据仓库,原本是大数据技术条件下构建分布式系统的两种数据架构设计取向。而融合后的「湖仓一体」,为业界和用户展现了一种「湖」与「仓」互相补充、协同工作的架构。

参考阅读
 相关阅读
相关阅读最佳实践7| SequoiaDB巨杉数据库跨引擎事务
无状态计算实例,实现Multi-Master横向扩展
引擎级多模|SequoiaDB让研发和DBA和谐共处

 点击阅读原文,了解《Hype Cycle for Data Management, 2021》
点击阅读原文,了解《Hype Cycle for Data Management, 2021》