




点击上方“IT那活儿”,关注后了解更多内容,不管IT什么活儿,干就完了!!!
文章前言
我们在流式计算数据加工流程中,有个场景是实现一种基于流式数据里面ip转换成对应的归属地信息,这个场景首先想到是如何找一个符合条件的ip映射库,而这个ip映射库需满足如下条件:
1. 性能好:因为实时数据量大,每条数据都需要实时调用,获取ip映射关系,所以性能要好,如果延时较大,会影响后面流程节点处理;
2. 开源,能扩展:开源,能内网部署,并提供扩展功能,支持加新的ip映射关系;
3. 方便调用:支持api调用,且精准率要高。
通过调研,开源ip2region.db数据库符合我们上面实际场景需求,本文档主要介绍在flink流式计算中如何使用了ip2region,通过测试程序了解flink 是如何加载外部文件机制,如需了解ip2region更多详情,可自行到官网地址查阅https://github.com/lionsoul2014/ip2region
功能实现
1. 下载项目
git clone https://github.com/lionsoul2014/ip2region.git
2. 引用maven依赖
程序引用ip2region依赖。
<dependency><groupId>org.lionsoul</groupId><artifactId>ip2region</artifactId><version>1.7.2</version></dependency>
3. demo编写
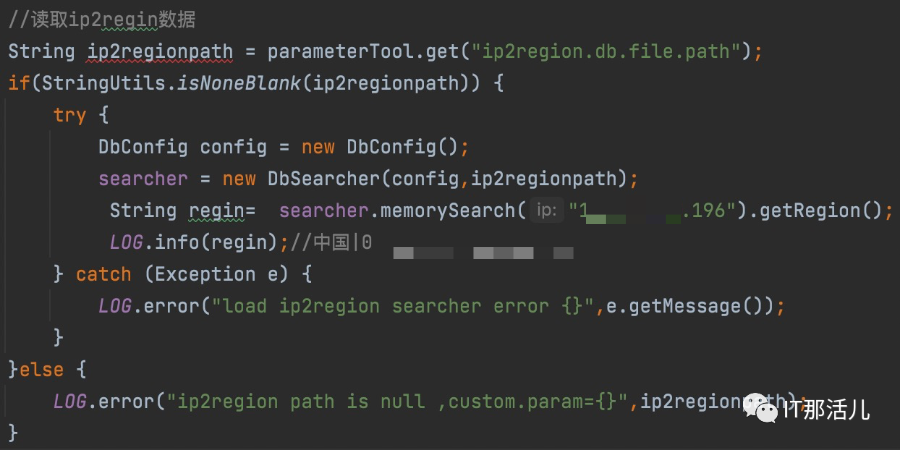
api比较简单就三行代码,采用的是memory查询算法。
打包测试
程序打包成功后,将程序提交到flink on yarn 环境之前,我们要考虑ip2regiog.db存储的位置及加载方式,否则在分布式环境下flink程序是无否读到该数据库:
方式一:ip2region.db库放入hadoop各计算节点:
将ip2region.db数据库文件放入hadoop各计算节点上指定位置上(如:/home/gpadmin/jar_repo/config/ip2region.db),由分配到此计算节点flink任务到指定目录下加载对应的数据库文件,实现ip归属转换。
1)新建basic.config配置文件,加入配置项
ip2region.db.file.path:/home/ip2region.db //指定读取的路径。
2)提交测试程序到yarn
flink run -m yarn-cluster -p 1 -yjm 1024 -ytm 1024 -ynm ipregiontest -c com.shsnc.fk.task.metricnormal.MetricsCollectTask regiondb.jar basic.config
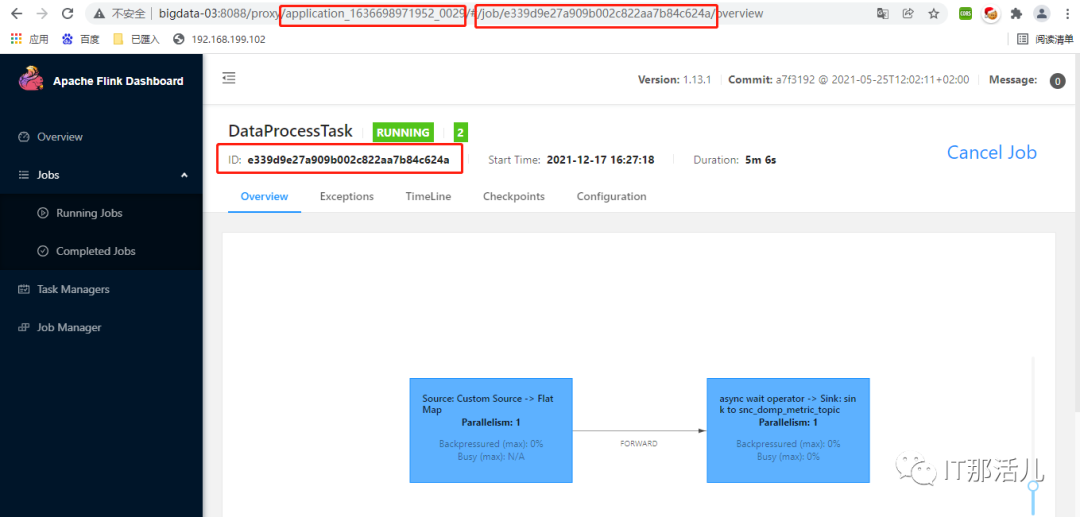
输出计算结果:
2021-12-17 16:27:26,470 INFO com.XXXXX.fk.task.dataprocess.function.DataProcessPreRichMapFunc [] - regin:中国|0|XXX|XXX|XX
3)分析加载流程
我们在flink run 启动命行里面,没有直接指向ip2region.db加载方式,而是在应用程序加载配置项获取对应的数据库文件存储位置,通过观察任务提交到flink on yarn 环境过程中,发现提交任务过程,tm自动会将该数据库文件放入yarn任务缓存目录下(Task ClassPath),任务运行过程中会到缓存目录下找到数据库文件。
ps -ef|grep container_1636698971952_0029_01_000002(容器id)。
ll /proc/进程号。
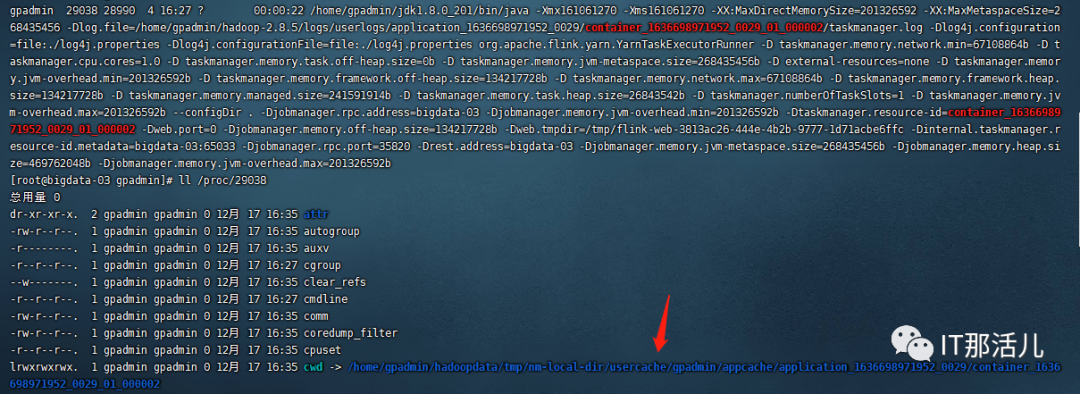

这种方式测试程序可以找到ip2region.db数据库文件,并且能计算出所需要ip归属,缺点是每台hadoop计算节点上都要将ip2region.db数据库文件放入指定位置,否则会提示读不到数据库文件现象,如果集群环境节点较多使用起来并不方便。
方式二:一次性加载方式
通过检查flink run命令参数,发现-yt 参数方式很好解决我们当前面临的问题,先看一下参数的使用说明:
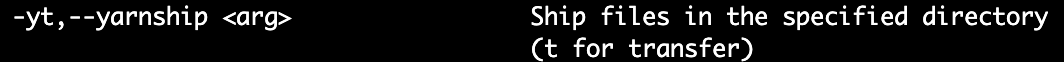
参数方式方式是 -yt 目录名,该参数意思是在指定目录中传输文件,处理流程如下:
-yt 目录名--hdfs(存储)--tm(下载)-tm(classpath)。
1)提交任务
flink run -m yarn-cluster -p 1 -yjm 1024 -ytm 1024 -yt /home/gpadmin/jar_repo/config -ynm ipregiontest -c com.XXXXX.fk.task.metricnormal.MetricsCollectTask regiondb.jar basic.config
注意这里指定是目录,而不是指定的是具体加载的文件。
2)hdfs查找存储位置
hdfs dfs -find hdfs://master:port/ -iname “ip2region.db”
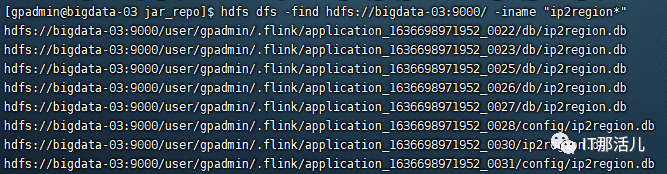
可以看出flink 任务在提交过程中,会将ip2region.db自动存储在hdfs上flink对应的任务目录下,同时把-yt 提向的目录(config )也存储了。
3)自动下载
检查每个haoop计算节点,tm会自动到hdfs上下载ip2region.db存放到缓存目录下(Task ClassPath),所以任务运行过程就要读到ip2region.db数据库文件,通过api很方便获取ip归属。

文章小结
方案二相比方案一优势明显,只需提交任务的时候指定外部文件在存储的目录,提交的过程,会自动分发到各个计算节占的任务所在的classpath中,很好解决了外部文件加载的问题。

本文作者:暨景书
本文来源:IT那活儿(上海新炬王翦团队)

