




前言
有较多朋友比较好奇昆仑分布式数据库集群的概念,针对于此出一篇文章进行说明下,后续也会更新此类的动画,以此去更形象的展示昆仑分布式数据库集群概念。
数据库集群
昆仑分布式数据库集群是由一系列执行不同任务的服务器&进程组构成,单个的数据库服务器称为节点,一系列节点在"无共享"架构中相互协调,形成一个集群,此架构允许数据库通过简单地向集群添加更多节点来缩放。
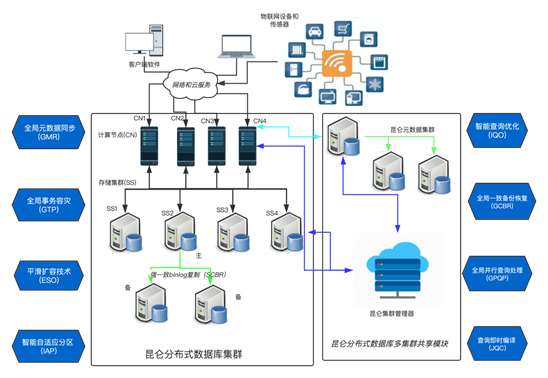

昆仑分布式数据库架构图
计算节点
计算节点使用PostgreSQL客户端协议或MySQL协议接受并验证客户端连接,并通过与集群的存储节点进行交互来执行连接客户端的SQL语句。
计算节点是无状态的,随着工作负载的增长,用户可以添加更多的计算节点,每个计算节点都可以为用户读/写请求提供服务。
计算节点具有全局事务处理能力,对于跨存储节点的数据操作,计算节点通过二阶段提交协议保证数据的一致性和完整性。
昆仑分布式数据库集群的计算节点本地具有所有数据库对象的所有元数据(表、视图、物化视图、序列、存储过程/函数、用户/角色和特权等),但它们不会在本地存储用户数据。
相反,计算节点将其存储在存储节点中。
存储节点
存储节点是用户&业务数据的具体存放的地方。
每个存储节点都会存储所有用户数据的部分子集。
存储节点从计算节点接SQL指令以插入/更新/删除用户数据或返回数据给计算节点。
存储节点通过基于Paxos组通信引擎的复制技术实现一主多副本的数据冗余。
元数据节点
元数据节点存储整个昆仑集群的元数据,包括所有用户的定义数据,节点连接信息,存储节点信息,交易信息等。
集群管理器
集群管理器作为守护进程运行,维持每一个存储集群及其节点的replication状态、集群计算节点与存储节点之间的元数据和状态同步,集群管理程序也负责处理分布式事务特定故障。
数据分片
分片表类型
昆仑数据库集群中有三种类型的表,每种表用于不同的目的。
类型1:分片表
这种表的数据在集群内的数据节点之间水平划分,每个分片表的结构相同,但表里存放的数据不同。分片表对访问者显示的名称是相同的。

如上图所示,每个数据存储中的表对象被称为分片表(Tab1.1,Tab1.2,Tab1.3)
分片键
昆仑分布式数据库集群使用算法分片将行分配给片表。
这意味着分配是确定性的分配的基础字段称为分片键。
数据库管理员在创建分片表时必须指定此键。
分片键必须是主键或者是主键的一部分。
昆仑数据库集群提供四种分片的算法,分别是基于范围分片、基于键值列表分片、基于键值的 hash 结果分片、基于参考表字段的分片。
-
范围分片:每个分片表包含一个或多个字段组合的一部分,并且每个分区表的范围互不重叠。比如可就日期范围分区。
-
列表分片:根据分片键的某个具体值进行分区。
-
Hash分片:根据字段的hash值进行均匀分布。
-
参考分片:数据有关联关系的表可以选择参考分片的算法,这样可以保证一次数据处理需要的几个分片表的数据位于同一个存储节点中,从而可以避免跨存储节点的数据操作。
类型2:普通表
您可以创建普通表并选择不将其分片,这样的表只会存储于某一个数据节点中。
类型3:复制表
某些表数据量比较小,这样的表会存储在每一个存储节点里,可以避免某些场景下的跨节点数据操作。
推荐阅读
KunlunBase架构介绍
KunlunBase技术优势介绍
KunlunBase技术特点介绍
END
昆仑数据库是一个HTAP NewSQL分布式数据库管理系统,可以满足用户对海量关系数据的存储管理和利用的全方位需求。
应用开发者和DBA的使用昆仑数据库的体验与单机MySQL和单机PostgreSQL几乎完全相同,因为首先昆仑数据库支持PostgreSQL和MySQL双协议,支持标准SQL:2011的 DML 语法和功能以及PostgreSQL和MySQL对标准 SQL的扩展。同时,昆仑数据库集群支持水平弹性扩容,数据自动拆分,分布式事务处理和分布式查询处理,健壮的容错容灾能力,完善直观的监测分析告警能力,集群数据备份和恢复等 常用的DBA 数据管理和操作。所有这些功能无需任何应用系统侧的编码工作,也无需DBA人工介入,不停服不影响业务正常运行。
昆仑数据库具备全面的OLAP 数据分析能力,通过了TPC-H和TPC-DS标准测试集,可以实时分析最新的业务数据,帮助用户发掘出数据的价值。昆仑数据库支持公有云和私有云环境的部署,可以与docker,k8s等云基础设施无缝协作,可以轻松搭建云数据库服务。
请访问 http://www.kunlunbase.com/ 获取更多信息并且下载昆仑数据库软件、文档和资料。
KunlunBase项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
