




Oracle RAC 详解
一、集群技术简介
集群是一组相互独立的、通过高速网络互联的计算机,这些计算机(节点)通过单一系统的模式加以管理,并且向外提供统一的服务。从客户的角度看来,集群就像一台独立的服务器。根据集群的功能特点可以大概将其分为以下3类。
(一)高可用集群
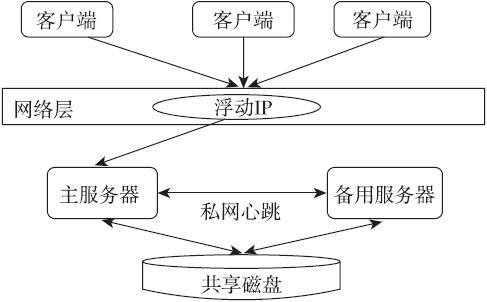
高可用集群(High Availability Cluster)简称HA cluster。高可用的含义是最大限度地提供可用的服务。从集群的名字上可以看出,此类集群实现的功能是保障用户的应用程序持久、不间断地提供服务。而高可用集群还可分为cold failover和hot failover。cold failover就是我们经常提到的主/备模式,集群通常存在两个节点,其中一个作为主节点向外提供服务,备用节点随时准备在主节点出现问题时向外提供服务。主/备节点都同时访问相同的共享磁盘。当然,cold failover的主/备节点彼此也进行心跳操作来维护集群的一致性;cold failover同样也提供浮动IP功能来保证对应用程序的透明性。大家可以通过下图了解典型的cold failover系统的基本架构。
hot failover一般是指集群的每个节点都处于活动状态,每个节点都能够分担应用程序负载,当某一个节点出现问题之后,其他节点可以分担问题节点的负载,而这些变化对应用程序来说全部都是透明的。读者可以通过下图了解典型的hot failover系统的基本架构。
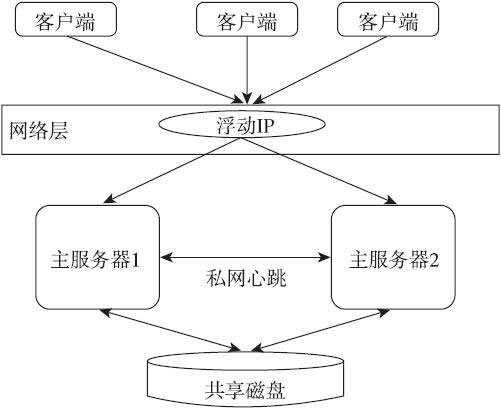
Oracle RAC就是非常典型的hot failover集群。
(二)负载均衡集群
负载均衡集群也是由两台或者两台以上的服务器组成的,分为前端负载调度和后端服务两个部分。负载调度部分负责把客户端的请求按照不同的策略分配给后端服务节点,而后端服务节点是真正提供应用程序服务的部分。与HA cluster不同的是,在负载均衡集群中,所有的后端服务节点都处于活动动态,它们都对外提供服务,分摊系统的工作负载。Oracle RAC也是很典型的负载应用集群。
(三)高性能计算集群
这类集群能够提供单个计算机所不能提供的强大计算能力,能进行大规模的数值计算和数据处理,并且倾向于追求综合性能。从某种程度来讲,可以认为高性能计算机集群类似于一台虚拟的超级计算机,它能够进行庞大而且高速的计算工作,而这些工作是单一计算机所无法完成的。高性能计算机集群通常采用的方式就是并行技术。Oracle RAC也提供了非常优秀的并行计算能力。
如果从数据共享的角度对集群分类的话,还可以将其分成share-nothing和share-everything两种结构。
(四)share-nothing结构
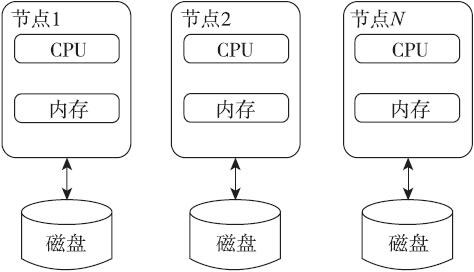
在这种结构下,集群中的每一个节点在物理上都是独立的,而且它们访问的磁盘也是相互独立的,而工作负载会分布到集群的不同节点上。这种结构的好处在于集群的结构很简单,节点和节点之间的交互和依赖很少,而且避免了动态锁管理(Dynamic Lock Management,DLM)、多节点并发控制所带来的性能瓶颈。但是,share-nothing也有很大的缺点:由于节点和节点间相互比较独立,所以在进行集群规划和工作负载划分的时候需要非常小心。由于彼此访问的磁盘也是互相独立的,所以当某一个节点出现问题时,可能会引起某些数据无法被访问的情况,即使磁盘之间可以对数据进行镜像处理,成本也会非常大,这会严重影响系统的性能和可用性,而且此类集群的可测量性、可扩展性非常差。下图描述了比较典型的share-nothing集群的基本架构。
(五)share-everything结构
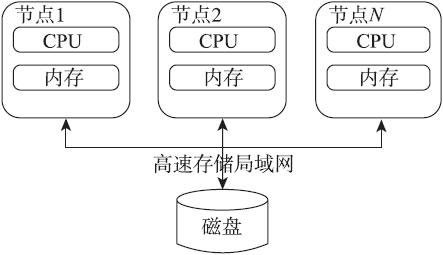
这种架构的集群和share-nothing结构的正相反,这类集群中的所有节点都会访问共享的磁盘,所以很多时候可以把这种架构称为“共享磁盘架构”,这种架构的最大特点就是:通过高速的存储局域网将多个节点连接在一起,实现对共享磁盘的并发读、写操作。share-everything集群架构成功地避免了share-nothing集群的缺点。这种集群架构能够实现非常好的高可用性、负载均衡、可测量性和扩展性。但是,share-everything也有一些问题:由于所有节点会向相同的磁盘进行并发读、写操作,所以需要一套控制机制(通常称之为DLM)来对读、写进行一定程度的串行化(也就是需要加锁),从而解决并发读、写操作下的冲突并保证数据的一致性。Oracle集群技术就采用了share-everything结构。下图是比较典型的share-everything集群的基本架构。
二、Oracle 11g R2 RAC 简介
11gR1这个版本,它有点儿像Oracle为了保证每5年左右推出一个大版本而导致的早产儿,因为绝大部分的集群核心功能没有任何改变,除了屈指可数的一些新特性。而且这些新特性,也并不算成熟。所以,很多Oracle业内人士认为11gR1应该称为10gR3。而且11gR1版本的集群管理软件仍然被命名为CRS。
11gR2这个版本才是真正的11g版本,被命名为GI(Grid Infrastructure),它基本保留了原有集群的核心功能,但是将集群做得更加精细,结构更加标准,功能更加强大。它的集群管理软件层面发生了巨大的改变,。
从11gR2版本开始,集群管理软件的组件变得更多,而且所有的组件都以资源的形式存在,统一由代理进程进行管理。
但是,如果根据集群组件功能来进行划分的话,仍然可以将11gR2版本的集群管理软件分成:集群初始化组件、集群存储管理组件和应用程序组件。集群初始化组件负责完成对集群的初始化工作,主要包括:启动ohasd守护进程,bootstrap本地节点,启动ocssd,构建集群并维护集群一致性。
集群存储管理组件负责管理集群的共享存储——ASM磁盘组,主要包括:启动ASM实例,挂载ASM磁盘组,管理ASM实例和磁盘组。
需要说明的是,在11gR2版本中,OCR和VF也可以保存在ASM磁盘组中。因此,ASM成为了管理和集群相关的所有共享存储的组件。
应用程序组件负责管理集群当中的应用程序资源,主要包括:启动CRSD守护进程,通过OCR中的信息启动并管理集群中的所有应用程序资源,实现应用程序资源的高可用性。
读者可以通过下图了解11gR2集群管理软件的各个组件的基本结构。
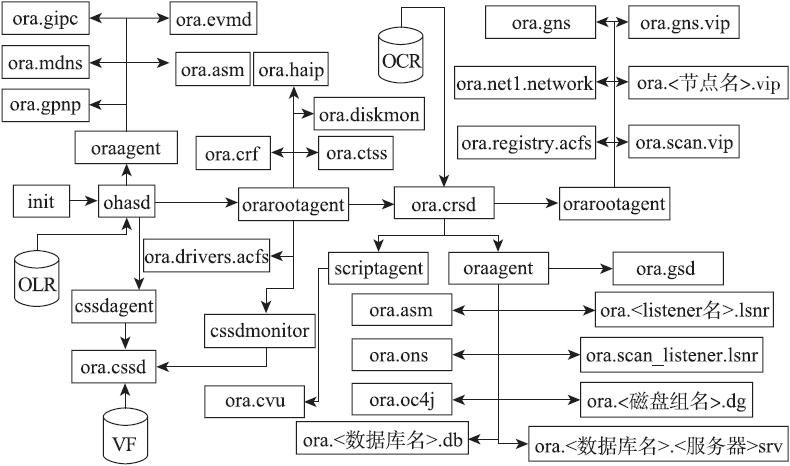
从上面的图片中可以看到,在11gR2这个版本中,ohasd变成了一切的源头,所有的组件都以资源的形式存在,而每个资源都由对应的代理进程进行管理。当然,ohasd除外。在上图的资源当中,集群初始化组件包括的资源有:ora.gipc、ora.gpnp、ora.mdns、ora.ctss、ora.asm、ora.cssd、ora.cssdmonitor等。集群存储管理组件包括的资源有:ora.asm、ora.<磁盘组名>.dg等。应用程序组件包括的资源有:ora.crsd、ora.LISTENER.lsnr、ora.net1.network、ora.<节点名>.vip、ora.scan.vip、ora.gns、ora.gns.vip、ora.ons、ora.scan_listener.lsnr、ora.<数据库明>.db、ora.<数据库名>.<服务名>srv等。
11gR2版本在集群的网络层面,无论是公网还是私网都推出了优秀的新特性,例如:集群公网资源统一管理集群的公网,SCAN的引入使客户端应用连接数据库的过程变得更加简单,HAIP使集群的私网变得更加高效和可靠。
对于数据库层面,11g版本也推出了一些优秀的新特性,例如:Read mostly,这个新特性的出现使内存融合技术在操作以读操作为主的数据库对象时变得更加高效。HM(Hang Manager)这个特性的出现使得RAC数据库能够自动地发现数据库中出现的等待链条、死锁或者夯住的进程,并且能够提前解决掉这些可能导致数据库性能问题的隐患,同时也为诊断数据库性能问题提供更多的参考信息。LMHB进程是11gR2版本中新出现的后台进程,用于监控和内存融合相关的所有后台进程,当这些进程当中的一个或多个出现性能问题时,LMHB通过终止阻塞进程或者终止实例的方式来避免出现数据库挂起的问题。
三、11g R2 集群新增组件
(一)OHAS
OHAS是11gR2版本新推出的一个重要的组件,随着这个组件的产生,Oracle集群管理软件的很多方面都发生了改变。这些改变主要体现在集群启动方式和资源管理方式方面。
1. 10g 版本
首先,回顾一下10g版本的集群管理软件(CRS)。从集群的启动角度来讲,10g版本的集群是通过/etc/inittable文件中的以下三行代码来启动的。
h1:35:respawn:/etc/init.d/init.evmd run >/dev/null 2>&1 </dev/null h2:35:respawn:/etc/init.d/init.cssd fatal >/dev/null 2>&1 </dev/null h3:35:respawn:/etc/init.d/init.crsd run >/dev/null 2>&1 </dev/null
其中,
□init.cssd负责启动ocssd.bin守护进程和其他CSS层面的守护进程,从而完成对集群的构建工作。
□Init.crsd负责启动crsd.bin守护进程并调用相应的racg模块来启动相应的资源,从而完成集群应用程序资源的启动。
□Init.evmd负责启动evmd.bin守护进程,从而实现集群节点的事件发布。
虽然以上3个脚本是被同时调用的,但是守护进程之间是有依存关系的。
首先,需要启动cssd.bin并确保其能够正常工作,之后才能够启动crsd.bin并确保其正常工作,最后启动evmd.bin并确保其正常工作。
接下来,看一下每个脚本的内容。当然,作者只会以脚本的一部分为例,说明它们的主要功能。
(1)init.cssd脚本
……
ORA_CRS_HOME=/u01/app/crs
ORACLE_USER=oracle
ORACLE_HOME=$ORA_CRS_HOME
export ORACLE_HOME
export ORA_CRS_HOME
export ORACLE_USER
……
# Default Location for commands on most platforms
PS='/bin/ps'
# ps -e is expected to search for all processes on the box and provide
# terse binary name output so that column count does not truncate binary
# names and confuse grep.
PSE='/bin/ps -e'
PSEF='/bin/ps -ef'
HEAD='/bin/head'
GREP='/bin/grep'
KILL='/bin/kill'
KILLTERM='/bin/kill -TERM'
KILLDIE='/bin/kill -9'
KILLCHECK="/bin/kill -0 $$"
SLEEP='/bin/sleep'
NULL='/dev/null'
……
可以能看到,首先定义了集群使用的一些环境变量和需要使用的操作系统命令。
…… PLATFORM=`$UNAME` MAXFILE=65536 case $PLATFORM in Linux) …… LD_LIBRARY_PATH=$ORA_CRS_HOME/lib export LD_LIBRARY_PATH FAST_REBOOT="/sbin/reboot -n -f & $SLEEP 1 ; $ECHO b > /proc/sysrq-trigger" HEAD='/usr/bin/head' …… HP-UX) MACH_HARDWARE=`/bin/uname -m` …… LD_LIBRARY_PATH=$ORA_CRS_HOME/lib:$NMAPIDIR_64:/usr/lib:$LD_LIBRARY_PATH export LD_LIBRARY_PATH # Presence of this file indicates that vendor clusterware is installed SKGXNLIB=${NMAPIDIR_64}/libnmapi2.${SO_EXT} if [ -f $SKGXNLIB ]; then USING_VC=1 Fi …… SunOS) MACH_HARDWARE=`/bin/uname -i` ARCH=`/usr/bin/isainfo -b` CLUSTERDIR=/opt/ORCLcluster LD_LIBRARY_PATH=$ORA_CRS_HOME/lib:$CLUSTERDIR/lib:/usr/lib:/usr/ucblib:$LD_LIBRARY_PATH LD_LIBRARY_PATH_64=$ORA_CRS_HOME/lib:$CLUSTERDIR/lib:/usr/lib:/usr/ucblib:$LD_LIBRARY_PATH_64 if [ "${MACH_HARDWARE}${ARCH}" = "i86pc64" ]; then LD_LIBRARY_PATH=$ORA_CRS_HOME/lib:$CLUSTERDIR/lib:/usr/lib/amd64:/usr/ucblib/amd64:$LD_LIBRARY_PATH LD_LIBRARY_PATH_64=$ORA_CRS_HOME/lib:$CLUSTERDIR/lib:/usr/lib/amd64:/usr/ucblib/amd64:$LD_LIBRARY_PATH_64 fi export LD_LIBRARY_PATH export LD_LIBRARY_PATH_64 …… AIX) CLUSTERDIR=/opt/ORCLcluster LIBPATH=$ORA_CRS_HOME/lib:$CLUSTERDIR/lib:$ORA_CRS_HOME/lib32:$CLUSTERDIR/lib32:/usr/lib:$LIBPATH LD_LIBRARY_PATH=$LIBPATH:$LD_LIBRARY_PATH export LIBPATH export LD_LIBRARY_PATH RENICE="/usr/sbin/renice" FAST_REBOOT="/usr/bin/sysdumpstart -p" SLOW_REBOOT="/bin/kill -HUP `$CAT /etc/syslog.pid`; /bin/sync & $SLEEP 2; /usr/sbin/fastboot -n -q" # Presence of this file indicates that vendor clusterware is installed SKGXNLIB=/usr/sbin/cluster/utilities/cldomain if [ -f $SKGXNLIB ]; then USING_VC=1 Fi …… OSF1) LD_LIBRARY_PATH=$ORA_CRS_HOME/lib:/usr/lib export LD_LIBRARY_PATH FAST_REBOOT="/usr/sbin/reboot -n -q" SLOW_REBOOT="/bin/kill -HUP `$CAT /var/run/syslog.pid`; /bin/sync & $SLEEP 2 ; /usr/sbin/reboot -n -q" # No need for OPROCD on Tru64. We don't support a configuration # without Tru64 clusterware,AND,Tru64 clusterware is responsible # for I/O Fencing. DISABLE_OPROCD=true # Presence of this file indicates that vendor clusterware is installed SKGXNLIB=/usr/ccs/lib/libdlm.a if [ -f $SKGXNLIB ]; then USING_VC=1 Fi …… *) /bin/echo "ERROR: Unknown Operating System" exit -1 ;;
为不同的操作系统设置对应的环境变量。
case $1 in
'home')
$ECHO $ORA_CRS_HOME
exit 0;
;;
'user')
$ECHO $ORACLE_USER
exit 0;
;;
'diag')
$ECHO CRS init script diagnostics.
......
'bootid')
......
'disable')
......
'enable')
......
'norun')
......
'start')
CMD=`$BASENAME $0`
# If we are being invoked by the user,perform manual startup.
# If we are being invoked as an RC script,check for autostart.
if [ "$CMD" = "init.cssd" ]; then
$LOGMSG "Oracle Cluster Synchronization Service starting by user request."
$ID/init.cssd manualstart
else
$ID/init.cssd autostart
fi
;;
'manualstart')
# Queue a startup to the CRS scripts invoked by inittab.
BOOTID=`$ID/init.cssd bootid`
$ECHO "$BOOTID" > $RUNFILE
STARTTIME=`$EXPRN $RUNRECHECKTIME + $STARTCHECKSLEEP`
$ECHO "Startup will be queued to init within $STARTTIME seconds."
;;
'autostart')
......
# Runcheck is intended to check the run status for any of the
# run or fatal scripts (evm/crs/css) as initialized by the automatic startup
# or manual startup routines.
# Runcheck is supposed to be a very fast check,and be silent since it
# will get invoked regularly while the system is up.
# Exit codes should match the requirements of startcheck.
'runcheck')
......
# Startcheck is intended to check the runcase $1 in
'home')
$ECHO $ORA_CRS_HOME
exit 0;
;;
'user')
$ECHO $ORACLE_USER
exit 0;
;;
'diag')
$ECHO CRS init script diagnostics.
......
'bootid')
......
'disable')
......
'enable')
......
'norun')
......
'start')
CMD=`$BASENAME $0`
# If we are being invoked by the user,perform manual startup.
# If we are being invoked as an RC script,check for autostart.
if [ "$CMD" = "init.cssd" ]; then
$LOGMSG "Oracle Cluster Synchronization Service starting by user request."
$ID/init.cssd manualstart
else
$ID/init.cssd autostart
fi
;;
'manualstart')
# Queue a startup to the CRS scripts invoked by inittab.
BOOTID=`$ID/init.cssd bootid`
$ECHO "$BOOTID" > $RUNFILE
STARTTIME=`$EXPRN $RUNRECHECKTIME + $STARTCHECKSLEEP`
$ECHO "Startup will be queued to init within $STARTTIME seconds."
;;
'autostart')
......
# Runcheck is intended to check the run status for any of the
# run or fatal scripts (evm/crs/css) as initialized by the automatic startup
# or manual startup routines.
# Runcheck is supposed to be a very fast check,and be silent since it
# will get invoked regularly while the system is up.
# Exit codes should match the requirements of startcheck.
'runcheck')
......
# Startcheck is intended to check the run
init.cssd根据输入的参数决定需要执行的操作,如果输入启动参数fatal,则表示正常启动cssd守护进程和其他相关的守护进程。
(2)init.crsd
ORA_CRS_HOME=/u01/app/crs ORACLE_HOME=$ORA_CRS_HOME export ORA_CRS_HOME export ORACLE_HOME ORACLE_USER=oracle UMASK=/bin/umask SED=/bin/sed CAT=/bin/cat LOGMSG="/bin/logger -puser.err" ECHO=/bin/echo KILL=/bin/kill ……
定义crsd需要使用的环境变量和操作系统命令。
...... case $PLATFORM in Linux) …… HP-UX) ID=/sbin/init.d ;; SunOS) …… AIX) …… OSF1) …… *) /bin/echo "ERROR: Unknown Operating System" exit -1 ;; esac
根据不同的操作系统平台设置相应的环境变量。
...... case $1 in 'home') ...... 'stop') ...... 'run') # foreground run out of init ...... 'tz') ...... *) ...... esac
根据输入的参数值决定相应的操作。如果输入参数为run,则表示启动crsd.bin守护进程。
(3)init.evmd
ORA_CRS_HOME=/u01/app/crs ORACLE_USER=oracle ORACLE_HOME=$ORA_CRS_HOME export ORACLE_HOME export ORA_CRS_HOME CAT=/bin/cat RMF="/bin/rm -f" LOGMSG="/bin/logger -puser.err" ECHO=/bin/echo KILL=/bin/kill ......
定义evmd需要使用的环境变量和操作系统命令。
case $PLATFORM in Linux) ...... HP-UX) ...... SunOS) ..... AIX) ...... OSF1) ...... *) /bin/echo "ERROR: Unknown Operating System" ...... esac
根据不同的操作系统平台设置相应的环境变量。
...... case $1 in 'home') ...... 'user') ...... 'stop') ...... 'run') # foreground run out of init ...... *) ...... esac
根据输入的参数值决定相应的操作。如果输入参数为start,则启动evmd.bin守护进程。
(4)小结
看了init.cssd、init.crsd和init.evmd三个脚本的内容后,可以发现这三个脚本的基本结构是:首先定义变量和操作系统命令,之后根据不同的操作系统平台设置对应的环境变量,最后根据输入的参数来决定对应的操作。但是这样做也为集群管理软件带来了问题:如果由于某种原因脚本的内容或者权限被修改,很可能导致集群无法被启动,并且很难进行诊断,而且所有的操作都保存在脚本中也会存在安全性的问题,所以,从11.2版本开始,集群的启动方式发生了改变。
2. 11g R2 版本
再来看看11gR2(即11.2版本)版本集群的/etc/inittab文件。
# Run xdm in runlevel 5
x:5:respawn:/etc/X11/prefdm -nodaemon
h1:35:respawn:/etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
只有脚本/etc/init.d/init.ohasd被调用,之前版本的三个脚本已经不存在了。接下来,看一下这个脚本的一些内容。
######### Instantiated Variables #########
ORA_CRS_HOME=/u01/app/11.2.0
export ORA_CRS_HOME
HAS_USER=root
SCRBASE=/etc/oracle/scls_scr
#limits
CRS_LIMIT_CORE=unlimited
CRS_LIMIT_MEMLOCK=unlimited
CRS_LIMIT_OPENFILE=65536
##########################################
……
### CLI tools
BASENAME=/bin/basename
HOSTN=/bin/hostname
SU=/bin/su
CHOWN=/bin/chown
ECHO=/bin/echo
SLEEP=/bin/sleep
EXPRN=/usr/bin/expr
CUT=/usr/bin/cut
CAT=/bin/cat
GREP=/bin/grep
ohasd所需要的环境变量和命令被定义。
### Main ###
case $PLATFORM in
Linux) LOGGER="/usr/bin/logger"
......
HP-UX)
......
AIX)
......
......
OSF1)
......
*) /bin/echo "ERROR: Unknown Operating System"
exit -1
;;
esac
根据不同平台设置对应的环境变量。
case $1 in 'run') ...... esac
看起来,输入的参数只有唯一的值run,它用于启动ohasd.bin守护进程。
3. 小结
根据10g和11gR2版本的集群管理软件的启动脚本之间的不同,能看到从11gR2版本开始,GI启动脚本变成了只有一个,而且脚本的长度也大大地减少,10g版本存在的问题得到了解决。
换句话说,ohasd.bin成为了集群启动的根(root)守护进程。
下面是一个查看ohasd.bin守护进程的ps命令:
[grid@test1 ~]$ ps -elf | grep has 4 S root 2473 1 1 75 0 - 40103 stext Nov07 ? 00:56:54 /u01/app/11.2.0/bin/ohasd.bin reboot 4 S root 2713 1 0 80 0 - 615 pipe_w Nov07 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
(二)资源管理方式
1. 10g 版本
对于10gR2版本的集群,资源管理的工作是由CRS(Cluster Ready Service)组件来实现的,也就是说由crsd守护进程负责管理资源,包括资源的启动、停止、监控等。所谓资源,实际上就是集群管理软件所需要管理的应用程序实体。
首先,需要了解10gR2版本的集群有哪些资源需要被管理。可以通过crs_stat命令来查看资源的列表。
[oracle@test1 ~]$ crs_stat -t Name Type Target State Host ------------------------------------------------------------ ora....SM1.asm application ONLINE ONLINE test1 ora....t1.lsnr application ONLINE ONLINE test1 ora....st1.gsd application ONLINE ONLINE test1 ora....st1.ons application ONLINE ONLINE test1 ora....st1.vip application ONLINE ONLINE test1 ora....SM2.asm application ONLINE ONLINE test2 ora....t2.lsnr application ONLINE ONLINE test2 ora....st2.gsd application ONLINE ONLINE test2 ora....st2.ons application ONLINE ONLINE test2 ora....st2.vip application ONLINE ONLINE test2 ora.testdb.db application ONLINE ONLINE test2 ora....g1.inst application ONLINE ONLINE test1 ora....g2.inst application ONLINE ONLINE test2 ora...._TAF.cs application ONLINE ONLINE test2 ora....0g1.srv application ONLINE ONLINE test1 ora....0g2.srv application ONLINE ONLINE test2
根据上面的输出,可以看到CRSD会管理以下资源:
- VIP资源(ora.<节点名>.vip)。
- ONS资源(ora.<节点名>.ons)。
- GSD资源(ora.<节点名>.gsd)。
- ASM实例资源(ora…ASM<节点编号>.asm)。
- 监听程序资源(ora.<节点名>.<监听程序名>.lsnr)。
- 数据库资源(ora.<数据库名>.db)。
- 数据库实例资源(ora.<数据库名>.<实例名>.inst)。
- 数据库服务资源(ora.<数据库名>.<服务名>.cs和ora.<数据库名>.<服务名>.<实例名>.srv)。
介绍了CRSD需要管理的资源列表之后,来看一下CRSD是如何实现资源管理的。首先介绍一些资源相关的术语。
- 动作(Action):动作定义了CRSD对资源进行启动、停止、检查和清除操作时所需要运行的步骤,它可以是一段shell脚本、一段应用程序、数据库命令等。
- 资源概要文件(profile):概要文件定义了资源的很多属性,以便CRSD能够根据概要文件定义的属性来创建资源。例如:检查间隔、动作脚本等。
- 依赖关系(Dependency):资源之间并不是独立的,有些资源之间是存在互相依赖关系的。例如:数据库实例启动的前提是ASM实例先要被启动,这表示数据库实例资源需要依赖于ASM实例资源,而这种依赖关系是通过资源属性REQUIRED_RESOURCES来实现的。
- 权限:由于不同的资源需要执行的操作也是不同的,这意味着执行操作的用户也会不同(主要是root和Oracle用户),所以,每个资源都会针对不同的用户指定不同的权限。这也是为什么crsd.bin守护进程需要以root用户运行的原因之一。
- OCR(Oracle Cluster Register):OCR实际上是包含了以上所有信息的一个注册表,CRSD通过访问OCR来获得集群资源的列表(当然,还包括其他很重要的信息)以及每个资源的各个属性。
Oracle集群管理软件(CRS)还定义了一些racg模块,不同的racg模块负责管理不同的资源,例如:racgvip负责管理VIP,这些模块负责定义对资源操作的动作。看到这里,读者对CRSD管理资源的方法应该有了比较清晰的认识,基本上可以将这些方法总结为以下的两点:
第一点:CRSD通过OCR定义资源。当crsd.bin守护进程启动时,通过读取OCR中的信息来获得资源定义。而当资源属性发生改变时,crsd.bin守护进程也会修改OCR中的信息。
第二点:CRSD通过调用racg模块来实现对资源的各种动作。
最后,通过一段CRSD的日志文件来简单回顾一下这一节介绍的内容。
Oracle Database 10g CRS Release 10.2.0.5.0 Production Copyright 1996,2004,Oracle.
All rights reserved
2014-11-11 13:29:56.433: [default][1521344]0CRS Daemon Starting
2014-11-11 13:29:56.435: [CRSMAIN][1521344]0Checking the OCR device
2014-11-11 13:29:56.638: [CRSMAIN][1521344]0Connecting to the CSS Daemon
2014-11-11 13:29:57.056: [COMMCRS][64297872]clsc_connect: (0x88e8f50) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=OCSSD_LL_test1_))
2014-11-11 13:29:57.057: [CSSCLNT][1521344]clsssInitNative: connect failed,rc 9
2014-11-11 13:29:57.058: [CRSRTI][1521344]0CSS is not ready. Received status 3 from CSS. Waiting for good status ..
2014-11-11 13:29:58.425: [COMMCRS][64297872]clsc_connect: (0x88e8f58) no listener at (ADDRESS=(PROTOCOL=ipc)(KEY=OCSSD_LL_test1_))
CRSD守护进程被启动,之后尝试联系CRSD守护进程,但是由于ocssd.bin还没有完全被启动,所以CRSD守护进程还不能继续向下运行。在ocssd.bin完全启动后,CRSD才能继续启动。
2014-11-11 13:30:10.492: [CLSVER][1521344]0Active Version from OCR:10.2.0.5.0 2014-11-11 13:30:10.493: [CLSVER][1521344]0Active Version and Software Version are same 2014-11-11 13:30:10.493: [CRSMAIN][1521344]0Initializing OCR 2014-11-11 13:30:10.754: [OCRRAW][1521344]proprioo: for disk 0 (/dev/raw/raw1),id match (1),my id set (1669906634,1028247821) total id sets (1),1st set (1669906634,1028247821),2nd set (0,0) my votes (2),total votes (2) 2014-11-11 13:30:10.910: [CRSD][1521344]0ENV Logging level for Module: allcomp 0 2014-11-11 13:30:10.936: [CRSD][1521344]0ENV Logging level for Module: default 0
CRSD守护进程发现了OCR对应的设备(/dev/raw/raw1)。
…… 2014-11-11 13:30:11.028: [CRSMAIN][1521344]0Filename is /u01/app/crs/crs/init/test1.pid 2014-11-11 13:30:11.064: [CRSMAIN][1521344]0Using Authorizer location: /u01/app/crs/crs/auth/ [ clsdmt][2865847184]Listening to (ADDRESS=(PROTOCOL=ipc)(KEY=test1DBG_CRSD))
CRSD守护进程的pid文件被创建,之后对应的套接字地址被创建。
…… 2014-11-11 13:30:12.623: [CRSMAIN][1521344]0CRS Daemon Started.
CRSD守护进程启动完成。
…… 014-11-11 13:30:14.258: [CRSRES][2739968912]0Attempting to start `ora.test1.vip` on member `test1` 2014-11-11 13:30:18.313: [CRSRES][2739968912]0Start of `ora.test1.vip` on member `test1` succeeded. 2014-11-11 13:30:18.735: [CRSRES][2739968912]0startRunnable: setting CLI values 2014-11-11 13:30:18.775: [CRSRES][2739968912]0Attempting to start `ora.test1.LISTENER_TEST1.lsnr` on member `test1` 2014-11-11 13:30:19.328: [CRSRES][2677029776]0startRunnable: setting CLI values 2014-11-11 13:30:19.374: [CRSRES][2677029776]0Attempting to start `ora.test1.ons` on member `test1` 2014-11-11 13:30:21.038: [ CRSRES][2677029776]0Start of `ora.test1.ons` on member `test1` succeeded. 2014-11-11 13:30:21.247: [ CRSRES][2729479056]0Start of `ora.test1.ASM1.asm` on member `test1` succeeded.
crsd开始启动资源。
2. 11g R2 版本
从版本11gR2版本开始,ohasd变成了集群启动的唯一始点,而所有的其他守护进程和集群管理的资源统统被定义为资源,例如:cssd守护进程就以初始化资源ora.cssd的形式存在,而ohasd守护进程负责管理集群所有的守护进程对应的资源。同时,集群管理软件(GI)不再使用racg模块来管理资源,而是用代理进程(agent)统一实现对所有资源的管理。这种改变使得11gR2版本的集群变得更加标准化、更加安全和便于管理。既然一切都变成了资源,那么和10g版本类似,就需要有一个注册表来保存资源的属性。OCR是用于保存CRSD所管理的资源的注册表,但是在CRSD启动之前集群还有很多初始化资源(例如asm实例)需要启动,所以只有OCR是不够的
Oracle在11gR2版本中推出了另一个集群注册表OLR(Oracle Local Registry)。接下来,详细介绍OLR和代理进程这两个11gR2的新特性。
(1)OLR
顾名思义,OLR是保存在本地的集群注册表,也就是说OLR是保存在每个节点本地的,而且其中的信息大部分是针对每个节点的。OLR的主要作用就是为ohasd守护进程提供集群的配置信息和初始化资源的定义信息。当集群启动时ohasd会从/etc/oracle/olr.loc文件(不同平台,文件位置会不同)中读取OLR的位置,OLR默认保存在<gi_home>/cdata下,文件名为<节点名>.olr。
[grid@test1 cdata]$ cat /etc/oracle/olr.loc olrconfig_loc=/u01/app/11.2.0/cdata/test1.olr crs_home=/u01/app/11.2.0 [grid@test1 cdata]$ ls -l /u01/app/11.2.0/cdata/test1.olr -rw------- 1 root oinstall 272756736 Nov 11 12:37 /u01/app/11.2.0/cdata/test1.olr
接下来,看一下OLR中记录的一些信息。通过命令ocrdump–local产生了一个OLR的转储文件。
[SYSTEM.ORA_CRS_HOME] ORATEXT : /u01/app/11.2.0 SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : root,GROUP_NAME : root}
GI home的信息。
…… [SYSTEM.version.activeversion] ORATEXT : 11.2.0.4.0 SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : root,GROUP_NAME : root}
集群版本信息。
…… [SYSTEM.GPnP] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_NONE,OTHER_PERMISSION : PROCR_NONE,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.GPnP.profiles] BYTESTREAM (16) : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_NONE,OTHER_PERMISSION : PROCR_NONE,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.GPnP.profiles.peer] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_NONE,OTHER_PERMISSION : PROCR_NONE,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.GPnP.profiles.peer.best] BYTESTREAM (16) : 3c3f786d6c2076657273696f6e3d22312e302220656e636f64696e673d225554462d38223f3e3c67 …… SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_NONE,OTHER_PERMISSION : PROCR_NONE,USER_NAME : grid,GROUP_NAME : oinstall}
集群初始化资源gpnp的定义信息。
…… [SYSTEM.network] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.network.haip] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.network.haip.group] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.network.haip.group.cluster_interconnect] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.network.haip.group.cluster_interconnect.interface] UNDEF : SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.network.haip.group.cluster_interconnect.interface.status] ORATEXT : eth1:99 SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall} [SYSTEM.network.haip.group.cluster_interconnect.interface.valid] ORATEXT : 169.254.93.64 SECURITY : {USER_PERMISSION : PROCR_ALL_ACCESS,GROUP_PERMISSION : PROCR_READ,OTHER_PERMISSION : PROCR_READ,USER_NAME : grid,GROUP_NAME : oinstall}
集群初始化资源HAIP的定义。
从上面的OLR转储文件可以看到:OLR的结构仍然沿用了和OCR相同的树形结构,而且其中的信息组织形式和OCR也是相同的。另外,OLR的备份策略和OCR的有所不同,默认情况下GI在初始安装时会在路径<gi_home>/cdata/<节点>下产生一个备份,例如:
-rw-r--r-- 1 grid oinstall 6799360 Sep 19 11:33 backup_20131003_094829.olr
OLR不会被自动备份,如果在集群的一些配置信息发生改变后,需要使用下面的命令手动进行备份:
[root@test1 bin]# ./ocrconfig -local -manualbackup test1 2014/11/16 13:18:31 /u01/11.2.0/grid/cdata/test1/backup_20141116_131831.olr test1 2014/11/11 14:29:28 /u01/11.2.0/grid /cdata/test1/backup_20141111_142928.olr test1 2014/09/19 11:37:52 /u01/11.2.0/grid/cdata/test1/backup_20140919_113752.olr
建议在集群的重要配置信息(例如:集群私网配置)发生改变之后,使用命令ocrconfig-local-manualbackup手动备份OLR。例如:
[root@test1 bin]# ./ocrconfig -local -manualbackup test1 2014/11/11 14:29:28 /u01/11.2.0/grid /cdata/test1/backup_20141111_142928.olr test1 2014/09/19 11:37:52 /u01/11.2.0/grid/cdata/test1/backup_20140919_113752.olr
当OLR丢失之后,可以使用命令“./ocrconfig-local–restore<OLR备份文件>”来恢复,不能从集群的其他节点复制OLR到本地节点,这是因为OLR中保存的一些信息是针对本地节点的。如果需要验证OLR的一致性,可以使用ocrcheck命令,例如:
[root@test1 bin]# ./ocrcheck -local Status of Oracle Local Registry is as follows : Version : 3 Total space (kbytes) : 262120 Used space (kbytes) : 2824 Available space (kbytes) : 259296 ID : 2073657760 Device/File Name : /u01/11.2.0/grid/cdata/test1.olr Device/File integrity check succeeded Local registry integrity check succeeded Logical corruption check succeeded
简单地说,所有适用于OCR的命令同样适用于OLR,但是需要增加-local选项。
(2)代理进程
随着Oracle数据库和集群产品的发展,集群管理软件需要管理越来越多的资源,同时资源的复杂程度也越来越高,原有的10g版本的集群管理方式已经无法完成越来越多、越来越复杂的资源管理任务。因此,Oracle在11gR2版本的集群管理软件中引入了一个全新的资源管理框架(framework)——代理进程,使得资源管理变得更加健壮和高效。
代理进程框架的核心部分——代理进程会以守护进程的形式存在,完成管理资源的任务。代理进程是多线程的进程,而且针对不同的资源会启动不同的代理进程。支持的代理进程包括以下几种。
- oraagent:这个代理进程会以Oracle或者grid用户启动,负责管理的用户为Oracle或grid的资源。
- orarootagent:这个代理进程以root用户启动,负责管理的用户为root的资源。
- cssdagent:这个代理进程负责启动ocssd.bin守护进程,之后负责监控ocssd.bin守护进程。
- cssdmoniot:这个代理进程和cssdagent代理进程基本一样,但是它只负责监控ocssd.bin守护进程。
代理进程可以由ohasd和crsd守护进程启动,其他的集群守护进程不能启动代理进程。其中,ohasd守护进程启动的代理进程负责管理集群的初始化资源和其他守护进程,而CRSD守护进程启动的代理进程负责管理集群的其他资源(在这一点上与10g版本一致的)。
ohasd.bin守护进程会启动4个代理进程,它们分别是oraagent_grid(如果集群管理软件和数据库软件都是使用Oracle用户安装的,那么这个代理进程的名称就是oraagent_oracle)、orarootagent_root、cssdagent_root、cssdmonitor。每个代理进程负责管理的资源可以参照下表。
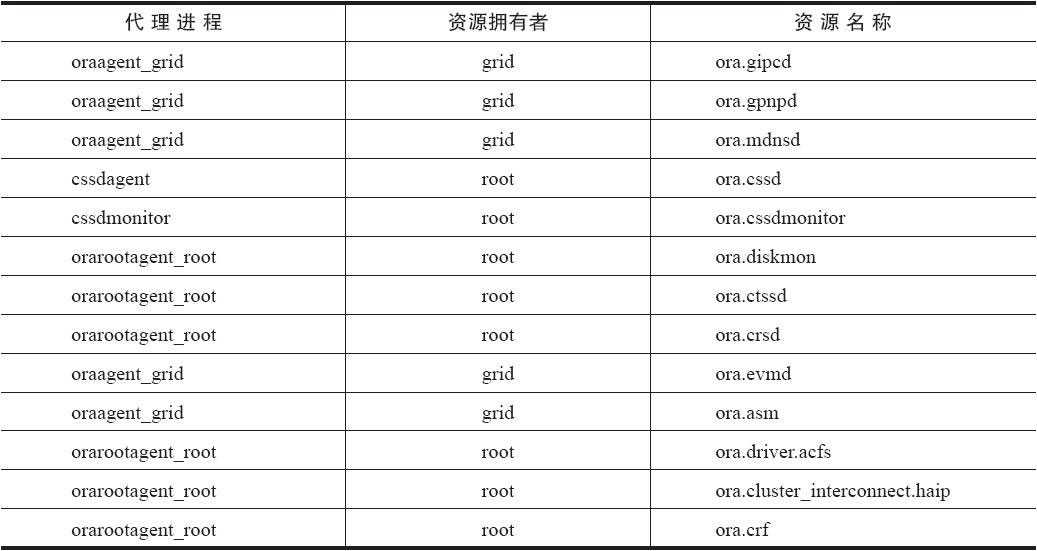
在以上的资源中:
- ora.gipcd、ora.gpnpd和ora.mdnsd会以守护进程的形式存在,它们负责完成集群在bootstrap阶段的工作,在第4章将详细介绍。
- ora.ctssd会以守护进程的形式存在,它负责集群的时间管理,在第4章将详细介绍。
- ora.cssd和ora.cssdmonitor会以守护进程的形式存在,其中ocssd.bin守护进程负责集群的构建,并维护集群的一致性,而cssdmonitor负责监控ocssd.bin守护进程的状态,在第5章将详细介绍。
- ora.crsd会以crsd.bin守护进程的形式存在,这个守护进程负责管理集群的其他资源,在第5章将详细介绍。
- ora.evmd负责管理集群事件的发布,会以evmd.bin守护进程的形式存在。
- ora.asm这个资源负责管理ASM实例,或者说它负责在集群启动时启动ASM实例。关于更多ASM的内容,在第9章将详细介绍。
- ora.cluster_interconnect.haip这个资源负责管理集群的HAIP(High Availability IP)资源,在本章稍后部分将详细介绍HAIP的内容。
- ora.crf负责管理11gR2版本集群管理软件的新特性CHM(Cluster Health Monitor),在本章稍后部分将详细介绍CHM的内容。
根据以上的描述,可以看到集群在ohasd层面的启动过程是:首先,/etc/inittab中的init.ohasd脚本被调用,之后该脚本启动ohasd.bin守护进程;然后ohasd.bin启动对应的代理进程,每个代理进程负责启动自己管理的集群初始化资源,即对应资源的初始化进程被启动。接下来介绍一下ohasd层面都有哪些重要的初始化资源。
3. ohasd管理的资源
在此对ohasd所管理的集群初始化资源进行介绍,其中,包括HAIP和CHM。
(1)HAIP
对于Oracle集群,私网通信是非常重要的,因为节点和节点之间的通信绝大部分都是要通过私网来实现的。私网通信基本上可以分为两种:第一种是集群层面之间的通信;第二种是数据库实例之间的通信。第一种通信(例如:节点间的网络心跳)的主要特点是持续存在、实时性要求高,但是数据量比较小,所以通过TCP/IP协议传递就可以了。而第二种通信,也就是读者所熟知的内存融合造成的实例之间的数据传输的特点是数据量很大,而且速度要求非常高,TCP/IP协议此时已经不能满足Oracle的要求了,所以需要使用UDP或者RDS,同时Oracle也一直建议用户对集群的私网进行高可用性和负载均衡的配置。对于10g和11gR1版本的集群,Oracle并不提供私网的高可用性和负载均衡特性,而是建议用户在操作系统层面配置,例如:Linux bonding、AIX etherchannel等。而从11.2.0.2版本开始,Oracle提供了私网的高可用性和负载均衡特性——HAIP。
首先,用户需要在安装GI的过程中为集群的私网指定多块网卡。
HAIP顾名思义就是一个(或多个)IP地址。Oracle会自动在集群的每一块私网网卡上绑定一个169.254.*.*网段的IP地址,这个IP地址被称为HAIP,数据库实例(ASM实例也同样适用)之间在进行通信时,会通过这个Oracle绑定的IP地址来完成。当某一块私网网卡出现问题时,对应网卡上绑定的IP地址可以漂移到其他的私网网卡上,这就实现了私网的高可用性。从另一个角度来讲,如果集群包含了多块私网,也就意味着会有多个HAIP被绑定在每一块私网网卡上,每一块网卡都同时承担实例之间的通信,从而实现了私网通信的负载均衡。因此,能看到HAIP的功能要比很多操作系统层面的网卡绑定更加强大,而且管理起来更加简单,因为用户只需要在安装时选择私网网卡就可以了,Oracle在启动集群时会自动把HAIP绑定到网卡上。此外,HAIP的负载均衡是以网卡为单位的,不需要额外的OS软件和交换机支持。
Oracle也支持在集群已经创建之后,添加新的私网网卡。下面是一个Linux平台上的ifconfig命令输出:
#ifconfig -a
eth1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:66
inet addr:192.168.254.11 Bcast:192.168.254.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe4b:b766/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
......
eth1:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:66
inet addr:169.254.31.199 Bcast:169.254.127.255 Mask:255.255.128.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:193 Base address:0x1800
eth2 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70
inet addr:192.168.234.11 Bcast:192.168.254.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe4b:b770/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
......
eth2:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70
inet addr:169.254.185.222 Bcast:169.254.255.255 Mask:255.255.128.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:169 Base address:0x1880
网卡eth1上的HAIP地址169.254.31.199被绑定;网卡eth2上的HAIP地址169.254.185.222被绑定。到目前为止,Oracle集群最多支持4块私网网卡。网卡数量和HAIP数量的关系如下:
- 1块私网网卡,1个HAIP地址。
- 2块私网网卡,2个HAIP地址。
- 3块私网网卡,4个HAIP地址。
- 4块私网网卡,4个HAIP地址。
接下来,通过以下的测试来说明HAIP是如何工作的。
步骤1:检查HAIP资源状态和私网设置。
$ crsctl stat res -t -init
NAME
TARGET STATE SERVER STATE_DETAILS Cluster Resources
---------------------------------------------------------------
ora.cluster_interconnect.haip
ONLINE ONLINE test2 1
HAIP资源状态正常。
[grid@test2~]$ oifcfg getif eth0 192.168.56.0 global public eth1 192.168.254.0 global cluster_interconnect eth2 192.168.234.0 global cluster_interconnect
集群存在两个私网网卡。
步骤2:检查HAIP是否已经绑定到对应的网卡上。
#ifconfig -a
eth1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:66
inet addr:192.168.254.11 Bcast:192.168.254.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe4b:b766/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
......
eth1:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:66
inet addr:169.254.31.199 Bcast:169.254.127.255 Mask:255.255.128.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:193 Base address:0x1800
eth2 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70
inet addr:192.168.234.11 Bcast:192.168.254.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe4b:b770/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
......
eth2:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70
inet addr:169.254.185.222 Bcast:169.254.255.255 Mask:255.255.128.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:169 Base address:0x1880
从上面程序可以看到,网卡eth1上的HAIP地址169.254.31.199被绑定;网卡eth2上的HAIP地址169.254.185.222被绑定。
步骤3:将网卡eth1停掉,再看一下HAIP的情况。
eth2 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70 inet addr:192.168.234.11 Bcast:192.168.254.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe4b:b770/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 ...... eth2:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70 inet addr:169.254.185.222 Bcast:169.254.255.255 Mask:255.255.128.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 Interrupt:169 Base address:0x1880 eth2:2 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70 inet addr:169.254.31.199 Bcast:169.254.127.255 Mask:255.255.128.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 Interrupt:169 Base address:0x1880
HAIP地址169.254.31.199被绑定到了私网网卡eth2上。
步骤4:恢复网卡eth1,再看一下HAIP的情况。
eth1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:66 inet addr:192.168.254.11 Bcast:192.168.254.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe4b:b766/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 ...... eth1:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:66 inet addr:169.254.31.199 Bcast:169.254.127.255 Mask:255.255.128.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 Interrupt:193 Base address:0x1800 eth2 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70 inet addr:192.168.234.11 Bcast:192.168.254.255 Mask:255.255.255.0 inet6 addr: fe80::20c:29ff:fe4b:b770/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 ...... eth2:1 Link encap:Ethernet HWaddr 00:0C:29:4B:B7:70 inet addr:169.254.185.222 Bcast:169.254.255.255 Mask:255.255.128.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 Interrupt:169 Base address:0x1880
HAIP地址169.254.31.199被重新绑定到了私网网卡eth1上,这说明,集群管理软件在私网网卡出现问题后仍然会继续监控这块网卡,以便在网卡恢复正常后能够将HAIP重新恢复到原有的网卡上,从而保证HAIP能够恢复负载均衡。
需要说明的是,数据库和ASM实例是在启动时读取HAIP地址的,以下是一小段数据库alert.log,基于此,可以看到数据库通过UDP协议在IP地址169.254.31.199和169.254.185.222上实现实例数据传输。
Cluster communication is configured to use the following interface(s) for this instance 169.254.31.199 169.254.185.222 cluster interconnect IPC version:Oracle UDP/IP (generic) IPC Vendor 1 proto 2
而在整个过程中,HAIP地址一直存在,只不过所绑定的网卡发生了漂移,所以数据库实例和ASM实例一直保持正常运行,不会有任何实例终止的问题出现,从而实现了实例间通信的高可用性和负载均衡特性。
(2)CHM
CHM(Cluster Health Monitor)是Oracle提供的一款工具,用来自动收集操作系统资源(CPU、内存、SWAP、进程、I/O以及网络等)的统计信息。从11.2.0.2版本开始,CHM会以初始化资源ora.crf的形式存在于集群的每一个节点上。例如:
[grid@test1 ~]$ crsctl stat res -t -init --------------------------------------------------------------------------- NAME TARGET STATE SERVER STATE_DETAILS --------------------------------------------------------------------------- Cluster Resources …… ora.crf 1 ONLINE ONLINE test1 ……
相对于OSWatcher,CHM直接调用OS的API,系统开销更小;CHM每秒收集一次数据(在11.2.0.3版本中,改为了5s一次),具有更强的实时性。而OSWatcher的优点是搜集的信息更加全面(例如:使用traceroute命令检测私网间的连通性),而且所生成的数据的保留时间可以设置得很长,但是数据的实时性没有CHM强,产生的信息可能占用很大的磁盘空间。因此这两个工具并不能互相替代,而是互补的,如果可以的话,最好两个工具都使用。
CHM搜集的系统资源数据对于诊断集群系统的节点重启、hang、实例驱逐(Eviction)、性能问题等是非常有帮助的。另外,用户可以使用CHM来及早发现一些系统负载异常、内存异常等问题,从而避免产生更严重的问题。另外,CHM还可作为单独的工具安装在Linux和Windows平台上,本书主要介绍RAC系统的CHM,而不会包含如何独立安装CHM的步骤。
CHM主要由以下的组件构成。
组件1:CHM档案库(Repository):它是一个Berkeley数据库,作为保存从各个节点搜集到的操作系统统计信息的档案库。默认情况下,它会存在于<gi_home>/crf/db/<节点名>下,默认占用1 GB的磁盘空间,对于绝大多数的系统,每个节点每天搜集的统计信息大约会占用500MB左右的空间。这里要强调的是CHM最大允许的信息保留天数为3天,这样做的目的就是为了减少CHM档案库所占用的磁盘空间。
组件2:系统监控服务(System Monitor Service):它会以osysmond.bin守护进程的方式在所有节点运行,osysmond.bin负责定期搜集本地节点的操作系统统计信息,并将搜集到的统计信息发送给主节点上的集群日志服务。
组件3:集群日志服务(Cluster Logger Service):这个服务会以守护进程ologgerd的形式运行在集群的CHM主节点(Master Node)和副节点(Replication Node)上。主节点的ologgerd负责接收从所有节点的osysmond.bin发送过来的操作系统统计信息,并记录到主节点的CHM档案库中;副节点的ologgerd负责接收从主节点的集群日志服务发送过来的操作系统统计信息,并记录到副节点的CHM档案库中,从而实现CHM档案库的高可用性。
读者可以通过下图了解CHM的工作方式。

CHM工作步骤如下。
步骤1:各个节点的osysmond通过集群私网向主节点的ologgerd发送本地节点操作系统统计信息。
步骤2:主节点的ologgerd向本节点的CHM档案库中写入收到的统计信息,同时发送给副节点ologgerd。
步骤3:副节点的ologgerd向本节点的CHM档案库中写入收到的统计信息。
如果CHM的主节点出现了问题,副节点会接管CHM并成为新的主节点,之后新的主节点会从集群的其他正常节点中再选出新的副节点。需要说明的是osysmond和ologgerd守护进程都会以实时(RT)优先级运行,以确保CHM能够准时地搜集操作系统的性能信息。
[grid@test1 admin]$ ps -elf | grep osysmond 4 S root 3025 1 1 -40 - - 19316 stext Nov13 ? 00:34:21 /u01/app/11.2.0/bin/osysmond.bin 0 R grid 24901 17341 0 78 0 - 980 - 06:42 pts/1 00:00:00 grep osysmond [grid@test1 admin]$ ps -elf | grep ologgerd 4 Sroot 20335 1 0 -40 - - 34515 stext Nov13 ? 00:18:50 /u01/app/11.2.0/bin/ologgerd -m test2 -r -d /u01/app/11.2.0/crf/db/test1
Oracle提供了oclumon和CHM/OS Graphical User Interface(CHMOSG)两款工具来访问CHM的数据。其中CHM/OS Graphical User Interface(CHMOSG)是图形界面工作,可以从OTN下载,由于篇幅有限,本书不会介绍CHMOSG。oclumon是命令行工具,本书会介绍一些简单的oclumon命令,帮助大家熟悉这个工具。
① 命令1:查看主节点和副节点
[grid@test1 admin]$ oclumon manage -get MASTER REPLICA Master = test2 Replica = test1 Done
② 命令2:看当前的统计信息的保存时间段
[grid@test1 admin]$ oclumon manage -get repsize CHM Repository Size = 67923 Done
③ 命令3:搜集一段时间内的各个节点的统计信息
[grid@test1 admin]$ oclumon dumpnodeview -allnodes -v -s "2014-11-15 06:15:00" -e "2014-11-15 07:15:00" > /tmp/chm.log
更多的关于oclumon工具的信息,请使用命令oclumon–h获得。下面是一小段CHM搜集的统计信息输出。
----------------------------------------
Node: test2 Clock: '11-15-14 06.15.00' SerialNo:37718
----------------------------------------
SYSTEM:
#pcpus: 1 #vcpus: 1 cpuht: N chipname: Intel(R) cpu: 48.80 cpuq: 11 physmemfree: 95344 physmemtotal: 1518712 mcache: 524552 swapfree: 3735008 swaptotal: 4192956 ior: 30 iow: 173 ios: 18 swpin: 0 swpout: 0 pgin: 30 pgout: 173 netr: 8.973 netw: 9.731 procs: 207 rtprocs: 10 #fds: 13632 #sysfdlimit: 6815744 #disks: 3 #nics: 3 nicErrors: 0
系统的基本信息包括CPU数量、内存使用情况、磁盘基本信息。
TOP CONSUMERS: topcpu: 'crsd.bin(3643) 2.59' topprivmem: 'ologgerd(3188) 90008' topshm: 'ora_mmon_ora11g(4599) 100996' topfd: 'crsd.bin(3643) 155' topthread: 'crsd.bin(3643) 46'
使用资源最多的进程包括消耗CPU最多的进程、消耗内存最多的进程、使用文件描述符(FD)最多的进程、线程最多的进程。
PROCESSES: name: 'crsd.bin' pid: 3643 #procfdlimit: 65536 cpuusage: 2.59 privmem: 25296 shm: 18204 #fd: 155 #threads: 46 priority: 15 nice: 0 name: 'ohasd.bin' pid: 2468 #procfdlimit: 65536 cpuusage: 1.59 privmem: 22760 shm: 12344 #fd: 134 #threads: 32 priority: 15 nice: 0
进程信息包括进程使用的内存状况、CPU使用情况、打开的文件描述符数量、包含的线程数量、优先级。
DEVICES: sda ior: 0.799 iow: 163.798 ios: 12 qlen: 0 wait: 0 type: SWAP sda2 ior: 0.000 iow: 0.000 ios: 0 qlen: 0 wait: 0 type: SWAP sda1 ior: 0.799 iow: 163.798 ios: 12 qlen: 0 wait: 0 type: SYS sdc ior: 29.763 iow: 8.390 ios: 5 qlen: 0 wait: 2 type: SYS sdc1 ior: 29.763 iow: 8.390 ios: 5 qlen: 0 wait: 2 type: SYS
磁盘的I/O性能信息包含I/O的读写次数、队列长度、等待次数。
NICS: lo netrr: 3.074 netwr: 3.074 neteff: 6.148 nicerrors: 0 pktsin: 2 pktsout: 2 errsin: 0 errsout: 0 indiscarded: 0 outdiscarded: 0 inunicast: 2 innonunicast: 0 type: PUBLIC eth0 netrr: 0.350 netwr: 0.000 neteff: 0.350 nicerrors: 0 pktsin: 5 pktsout: 0 errsin: 0 errsout: 0 indiscarded: 0 outdiscarded: 0 inunicast: 5 innonunicast: 0 type: PUBLIC eth1 netrr: 5.548 netwr: 6.656 neteff: 12.204 nicerrors: 0 pktsin: 14 pktsout: 14 errsin: 0 errsout: 0 indiscarded: 0 outdiscarded: 0 inunicast: 14 innonunicast: 0 type: PRIVATE latency: <1
网卡的统计信息包含网卡的发送和接收性能信息、错误数量等,而且集群的公网和私网信息都被包含在内。
FILESYSTEMS: mount: / type: rootfs total: 36554508 used: 23007512 available: 11660164 used%: 66 ifree%: 96 [ORACLE_HOME ****]
ORACLE_HOME所在文件系统的空间使用状况。
PROTOCOL ERRORS: IPHdrErr: 0 IPAddrErr: 94543 IPUnkProto: 0 IPReasFail: 0 IPFragFail: 0 TCPFailedConn: 132 TCPEstRst: 5877 TCPRetraSeg: 13 UDPUnkPort: 136 UDPRcvErr: 0
不同的网络协议由于不同原因造成的错误的统计信息。
----------------------------------------
Node: test1 Clock: '11-15-14 06.15.01' SerialNo:37719
----------------------------------------
SYSTEM:
#pcpus: 1 #vcpus: 1 cpuht: N chipname: Intel(R) cpu: 40.60 cpuq: 19 physmemfree: 49672 physmemtotal: 1518712 mcache: 463864 swapfree: 3914220 swaptotal: 4192956 ior: 30 iow: 60 ios: 7 swpin: 0 swpout: 0 pgin: 30 pgout: 60 netr: 10.313 netw: 7.901 procs: 206 rtprocs: 10 #fds: 13248 #sysfdlimit: 6815744 #disks: 3 #nics: 3 nicErrors: 0
TOP CONSUMERS:
topcpu: 'crsd.bin(3750) 2.19' topprivmem: 'java(3097) 129096' topshm: 'ora_smon_ora11g(5491) 101948' topfd: 'crsd.bin(3750) 138' topthread: 'crsd.bin(3750) 43'
.
PROCESSES:
name: 'crsd.bin' pid: 3750 #procfdlimit: 65536 cpuusage: 2.19 privmem: 9016 shm: 18156 #fd: 138 #threads: 43 priority: 15 nice: 0
name: 'ora_lmon_ora11g' pid: 5467 #procfdlimit: 65536 cpuusage: 1.59 privmem: 6816 shm: 21992 #fd: 27 #threads: 1 priority: 15 nice: 0
……
DEVICES:
sda ior: 0.799 iow: 53.523 ios: 2 qlen: 0 wait: 1 type: SWAP
……
NICS:
lo netrr: 2.062 netwr: 2.062 neteff: 4.123 nicerrors: 0 pktsin: 2 pktsout: 2 errsin: 0 errsout: 0 indiscarded: 0 outdiscarded: 0 inunicast: 2 innonunicast: 0 type: PUBLIC
……
FILESYSTEMS:
mount: / type: rootfs total: 36554508 used: 32076164 available: 2591512 used%: 92;';3;Time=11-15-14 06.15.01,used Too High' ifree%: 96 [ORACLE_HOME ora11g1]
……
PROTOCOL ERRORS:
IPHdrErr: 0 IPAddrErr: 94555 IPUnkProto: 0 IPReasFail: 0 IPFragFail: 0 TCPFailedConn: 6479 TCPEstRst: 5948 TCPRetraSeg: 17 UDPUnkPort: 116 UDPRcvErr: 0
集群中其他节点的相同信息被输出。
从CHM搜集的统计信息的输出项目名称中基本能够看到对应的操作系统命令,所以上文只是简单介绍了每一类统计信息对应的含义,读者可以参考Linux或Windows平台上对应命令的帮助来了解更多信息。
四、11g R2 集群新增的集群守护进程
(一)MDNS
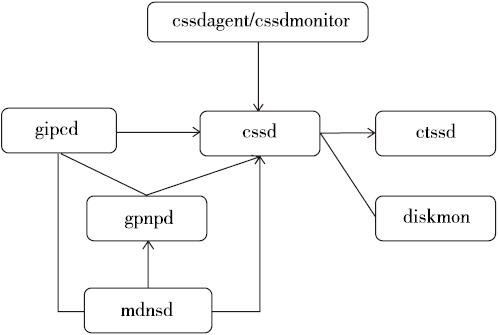
mdns的功能和普通的DNS很类似,即提供主机名到IP地址的解析服务。而对于DNS的功能,本书不会做过多的介绍,因为有太多的资料已经对此提供了详细的解释,但是,作者还是希望简单地列出mdns的一些基本特性:
特性1:mdns主要为小型私有网络(不存在DNS)提供名称解析服务。
特性2:mdns使用多播(Multicast)发布信息。
特性3:mdns使用UDP协议进行数据传输。
特性4:mdns对应的主机名会以.local结尾。
而Oracle GI下的mdns也实现了类似的功能。mdns主要负责为集群中其他的守护进程,主要是gpnpd和ohasd进程提供资源发现服务(Resource Discovery,简称RD),帮助集群中的其他守护进程发现远程节点。读者可以通过下图来了解mdnsd和gpnpd、ohasd之间的关系。
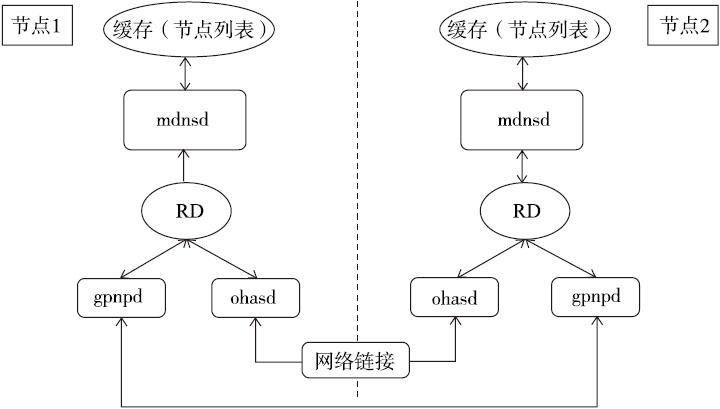
接下来,通过一段相关的进程日志中的信息来详细了解在集群启动时mdnsd是如何工作的。
1. mdnsd.log
2014-09-19 11:34:32.248: [default][3039942976]mdnsd START pid=26374 [clsdmt][3033496464]Listening to (ADDRESS=(PROTOCOL=ipc)(KEY=test1DBG_MDNSD)) 2014-09-19 11:34:32.252: [clsdmt][3033496464]PID for the Process [26374],connkey 9
mdnsd进程被启动,而且对应的socket地址被创建。
2014-09-19 11:34:32.253: [clsdmt][3033496464]Creating PID [26374] file for home /u01/app/11.2.0.4/grid host test1 bin mdns to /u01/app/11.2.0.4/grid/mdns/init/ 2014-09-19 11:34:32.253: [clsdmt][3033496464]Writing PID [26374] to the file [/u01/app/11.2.0.4/grid/mdns/init/test1.pid]
mdnsd进程的pid文件被创建。
2014-09-19 11:34:33.347: [MDNS][3039942976] mdnsd found interface name=lo AF=2 2014-09-19 11:34:33.347: [MDNS][3039942976] mdnsd found interface name=eth0 AF=2 2014-09-19 11:34:33.347: [MDNS][3039942976] mdnsd found interface name=eth1 AF=2
本地节点的网卡信息被发现。
2014-09-19 11:34:33.348: [MDNS][3039942976] Oracle mDNSResponder ver. mDNSResponder-1076 (Aug 2 2013 05:25:17) ,init_rv=0 2014-09-19 11:34:33.349: [MDNS][3039942976] Unable to parse DNS server list. Unicast DNS-SD unavailable 2014-09-19 11:34:33.603: [MDNS][3039942976] Local Hostname test1.local already in use; will try test1-2.local instead
本地节点信息被发现,mdnsd启动结束。
从以上的日志输出能看到,mdnsd在进行资源发现时同时使用了公网和私网,这是正常的行为。
2. gpnpd.log
2014-09-19 11:34:33.565: [default][3040057040]gpnpd START pid=26388 Oracle Grid Plug-and-Play Daemon 2014-09-19 11:34:33.566: [GPNP][3040057040]clsgpnp_Init: [at clsgpnp0.c:585] '/u01/app/11.2.0.4/grid' in effect as GPnP home base. 2014-09-19 11:34:33.566: [GPNP][3040057040]clsgpnp_Init: [at clsgpnp0.c:619] GPnP pid=26388,GPNP comp tracelevel=1,depcomp tracelevel=0,tlsrc:ORA_DAEMON_LOGGING_LEVELS,apitl:0,complog:1,tstenv:0,devenv:0,envopt:0,flags=3 …… 2014-10-23 09:31:10.387: [default][3039647440]GPNPD started on node test1.
gpnpd进程被启动。
2014-09-19 11:34:35.432: [GPNP][3040057040]clsgpnpdRCB: [at clsgpnpd.c:3933] GPnPD endpoint url "mdns:gpnp._tcp://test1:41422/agent=gpnpd,cname=test-cluster,host=test1,pid=26388/gpnpd h:test1 c:test-cluster" successfully advertised with RD
gpnpd使用mdnsd提供的节点信息向网络发布自己的信息,同时也开始搜索其他节点的信息。
2014-09-19 11:34:40.589: [GPNP][3024083856]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2104] put-profile call to url "tcp://test3:35726" disco "mdns:service:gpnp._tcp.local.://test3:35726/agent=gpnpd,cname=test-cluster,guid=6de9b87c2edadf6fbf4bb1fcf61e2fa0,host=test3,pid=2703/gpnpd h:test3 c:test-cluster u:6de9b87c2edadf6fbf4bb1fcf61" [f=0 claimed- host:test1 cname:test-cluster seq:9 auth:CN=GPnP_peer] 2014-09-19 11:34:40.589: [GPNP][3024083856]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2104] put-profile call to url "tcp://test3:35726" disco "mdns:service:gpnp._tcp.local.://test3:35726/agent=gpnpd,cname=test-cluster,guid=6de9b87c2edadf6fbf4bb1fcf61e2fa0,host=test3,pid=2703/gpnpd h:test3 c:test-cluster u:6de9b87c2edadf6fbf4bb1fcf61" [f=0 claimed- host:test1 cname:test-cluster seq:9 auth:CN=GPnP_peer] 2014-09-19 11:34:40.609: [GPNP][3024083856]clsgpnpm_doconnect: [at clsgpnpm.c:1169] GIPC gipcretFail (1) gipcConnect(tcp-tcp://test3:35726) 2014-09-19 11:34:40.609: [GPNP][3024083856]clsgpnpm_doconnect: [at clsgpnpm.c:1170] Result: (48) CLSGPNP_COMM_ERR. Failed to connect to call url "tcp://test3:35726" …… 2014-09-19 11:34:41.126: [GPNP][3024083856]clsgpnpdPutProfileCallLe: [at clsgpnpd.c:2324] Result: (1) CLSGPNP_ERR. Error pushing profile to "mdns:service:gpnp._tcp.local.://test3:35726/agent=gpnpd,cname=test-cluster,guid=6de9b87c2edadf6fbf4bb1fcf61e2fa0,host=test3,pid=2703/gpnpd h:test3 c:test-cluster u:6de9b87c2edadf6fbf4bb1fcf61",push continuing
gpnpd发现了远程节点发布的信息,并尝试将本地的gpnp profile推送到远程节点上。但是,由于两个节点不属于同一个集群,所以失败了。
2014-09-19 11:34:41.128: [GPNP][3024083856]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2104] put-profile call to url "tcp://test2:65324" disco "mdns:service:gpnp._tcp.local.://test2:65324/agent=gpnpd,cname=test-cluster,host=test2,pid=8723/gpnpd h:test2 c:test-cluster" [f=0 claimed- host:test1 cname:test-cluster seq:9 auth:CN=GPnP_peer] 2014-09-19 11:34:41.264: [GPNP][3024083856]clsgpnp_profileCallUrlInt: [at clsgpnp.c:2234] Result: (25) CLSGPNP_DUPLICATE. Successful put-profile CALL to remote "tcp://test2:65324" disco "mdns:service:gpnp._tcp.local.://test2:65324/agent=gpnpd,cname=test-cluster,host=test2,pid=8723/gpnpd h:test2 c:test-cluster"
gpnpd发现了其他远程节点发送的信息,并尝试将本地的gpnp profile推送到该节点上,因为两个节点属于相同的集群,推送成功。
3. ohasd.log
2014-09-19 11:33:51.435: [default][3037427408] OHASD Daemon Starting. Command string :reboot 2014-09-19 11:33:51.436: [default][3037427408] Initializing OLR
ohasd进程启动。
2014-09-19 11:34:59.449: [CRSCCL][2997873552]Registering: mdns:service:CLSFRAME._tcp://test1:8888/host=,mName=test1,clUid=7d414c4a930cdfc4ff23e150c9acd5e0,mId=925,mIncn=1411097696,mData=1:OHASD:test1/CLSFRAME_925_1411097696 c:7d414c4a930cdfc4ff23e150c9acd5e0 2014-09-19 11:35:00.425: [CRSCCL][2997873552]clsCclRegRdCb: state=REGISTER typestr= . Url=mdns:service:CLSFRAME._tcp://test1:8888/host=,mName=test1,clUid=7d414c4a930cdfc4ff23e150c9acd5e0,mId=925,mIncn=1411097696,mData=1:OHASD:test1,mConnectAddr=test1:CLSFRAME_RD_0/CLSFRAME_925_1411097696 c:7d414c4a930cdfc4ff23e150c9acd5e0
ohasd通过mdnsd发布本节点的信息。
2014-09-19 11:47:31.118: [CRSCCL][2997873552]FS: mdns:service:CLSFRAME._tcp.local.:////CLSFRAME_566_1411098410 c:7d414c4a930cdfc4ff23e150c9acd5e0,0xa3dcfb0,event(0xa3dcfcc)=found 2014-09-19 11:47:31.132: [CRSCCL][2997873552]FS: mdns:service:CLSFRAME._tcp.local.:////CLSFRAME_566_1411098410 c:7d414c4a930cdfc4ff23e150c9acd5e0,0xa3d6050,event(0xa3d606c)=found …… 2014-09-19 11:47:31.144: [CRSCCL][2997873552]ASE: mdns:service:CLSFRAME._tcp.local.://test2:8888/host=,mName=test2,clUid=7d414c4a930cdfc4ff23e150c9acd5e0,mId=566,mIncn=1411098410,mData=1:OHASD:test2,mConnectAddr=test2:CLSFRAME_RD_0/CLSFRAME_566_1411098410 c:7d414c4a930cdfc4ff23e150c9acd5e0,event(0xa3dcfb0)=found 2014-09-19 11:47:31.144: [CRSCCL][2997873552]ASE: MemId 566 found 2014-09-19 11:47:31.145: [CLSFRAME][2997873552] New process connected to us ID:{Absolute|Node:566|Process:1411098410|Type:2} Info:OHASD:test2
ohasd发现了远程节点的信息。
2014-09-19 11:47:31.145: [CRSCCL][2997873552]Dumping member data --------------- 2014-09-19 11:47:31.145: [CRSCCL][2997873552]Member (566,1411098410) on node test2 port=. 2014-09-19 11:47:31.145: [CRSCCL][2997873552]Member (925,1411097696) on node test1 port=. 2014-09-19 11:47:31.145: [CRSCCL][2997873552]Done ------------------
集群节点列表信息被更新。
mdnsd只负责为gpnpd和ohasd提供节点名称解析和资源发现服务,节点之间的数据传输仍然是由具体的守护进程来实现的,而不是由mdnsd来完成。
