




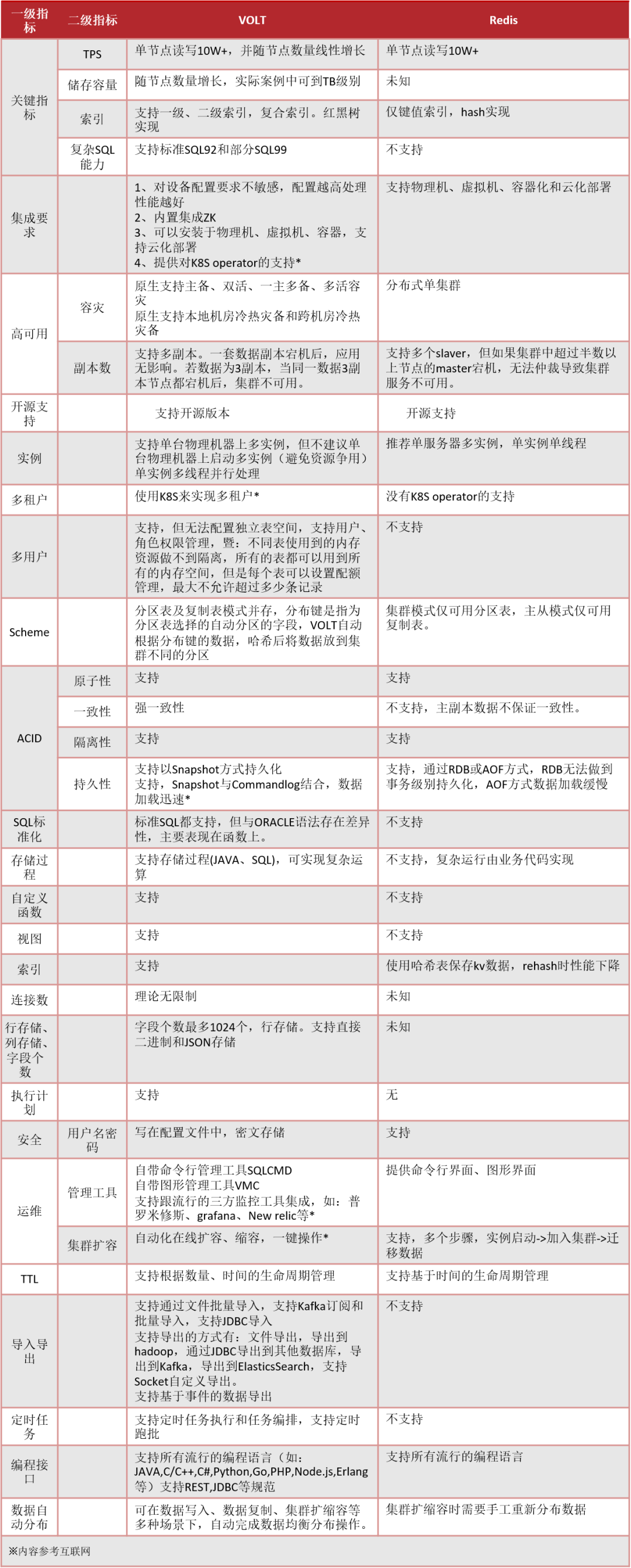
在金融、通信行业的业务场景中,内存数据库的运用越来越深入,不断有新的业务需求、性能要求被提上日程。面对丰富的IMDB产品,如何在 明确业务需求的基础上选择更适合自己的IMDB产品?这里我们选择业界普遍使用的Redis与VoltActiveData(以下简称VOLT)做一个多方位的比较,希望能帮助大家更加了解不同IMDB产品的特性和差异点,能根据自己的业务特征做好技术方案选型。
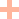
常用方案如通过proxy来寻址分片,集群 扩缩容对业务层不透明。
透明接入任意node,系统内部派发分 片事务。
通过JedisCluster优化 - 管道(pipeline)模式导入,数据量大的情况下会造成内存溢出的情况,超百万数据要分批次执行。
执行连接mysql脚本可直接同步数据至VOLT。


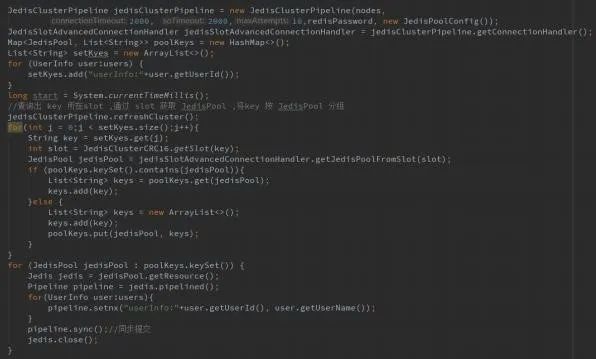
通过异步队列方式将数据同步至MySQL:
Step1 在VOLT中创建流:

Step2 在存储过程中调用流:

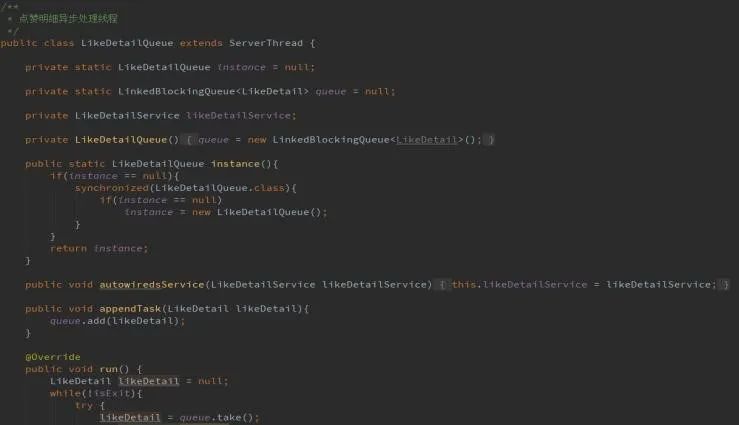
Redis只支持单节点事务,集群模式下需要redis+lua脚本配合使用,lua一般采c/c++来编写。
VOLT 是一个完全符合 ACID 的关系型数据库,它使应用程序开发人员不必在自己的应用 程序中开发代码来执行事务和管理回滚。

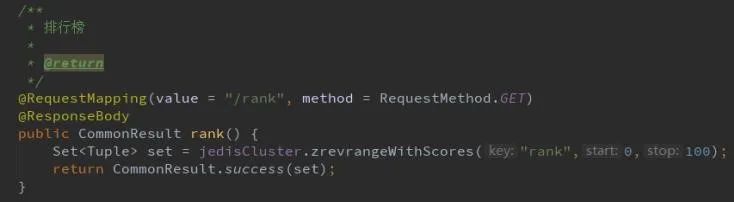
Redis属于NoSql系列的数据库,它的存储结构是Key-Value,它并不像关系数据库那样提供 任何的SQL,像排序、聚合函数、 sql语句无法通过sql查询实现。
例:实现排序
只能通过有序集合(sorted set)组合score+时间的方法组合实现

VOLT使用标准SQL,包括CREATE INDEX,CREATETABLE,CREATEVIEW,SELECT,INSERT,UPDATE,DELETE操作等。学习成本和代码迁移成本很低,代码复用程度高,已经使用SQL 实现的应用,可以相对容易的迁移到VOLT。
同时VOLT还支持用户自定义函数,通过 Java编写并导入数据库, 用户自定义函数能在SQL语句中使用。
例:实现排序

在项目中编写代码实现功能,版本迭代需要重新部署服务器。
VOLT通过编写存储过程实现,无需重启应用服务器,重新编译存储过程即可,保证程序的稳定性。

程序中只需调用存储过程:

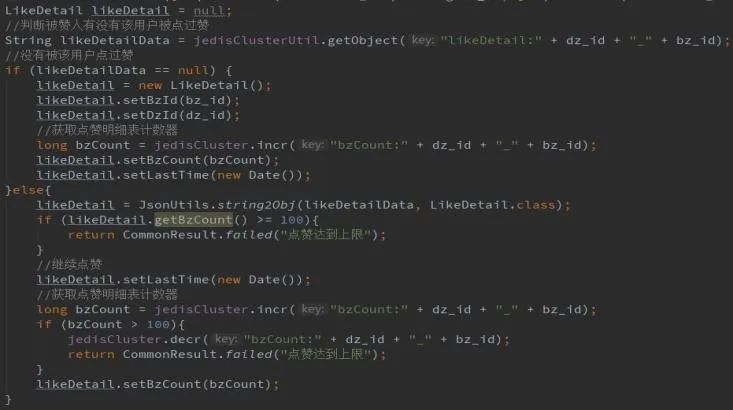
业务层需要实现机制来保证缓存和数据库的一致。这意味着:
1、开发者需要实现写缓存、写DB这两套接口
2、需要实现缓存miss处理机制
3、需要实现双写,保证数据库和缓存的一致性
4、键值的timeout设置维护
VOLT本身就是RDBMS,或者VOLT可以通过简单配置完成到源数据库的同步。
(可参见上文“VOLT同步数据到Mysql”)
需要业务层加入实现机制才能保证不读到脏、过期数据。
比如“选择性读主”方案的实现流程为:
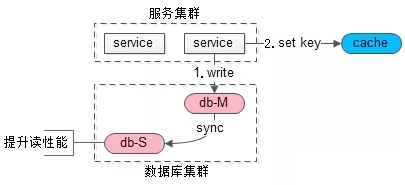
DB内部机制保证,对业务层透明。
开箱即用,不需要运维人员选择主从读取方式。
对象具有多属性的场景
单对象多属性的业务场景非常基本。使用 redis存储多属性的情况下,需要业务层 开发两层转换(如使用Hash存储,需要 首先按照对象key查询得到dict,然后按 属性名查询到value)
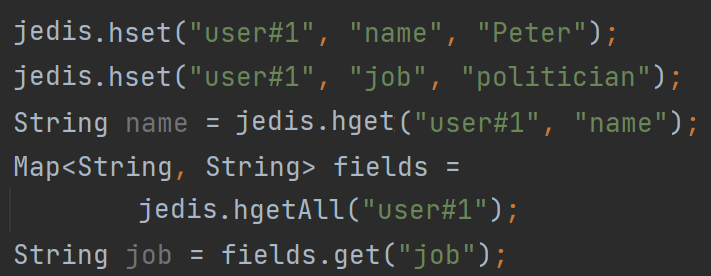
在一行内解决多属性的读写。
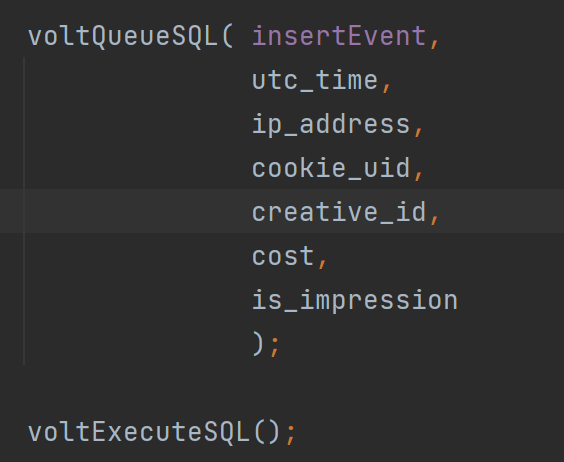
多类型的对象属性关联查询的场景
键值自增自减原子操作
如果您希望集成VoltActiveData到您的技术栈中,
请与我们联系!
VoltActiveData中国网站:👇
https://www.voltdb-china.cn/
欢迎扫码添加小助手
进入到我们的官方微信交流群

扫描二维码
加入VoltActiveData交流群
注明公司 实时探讨
