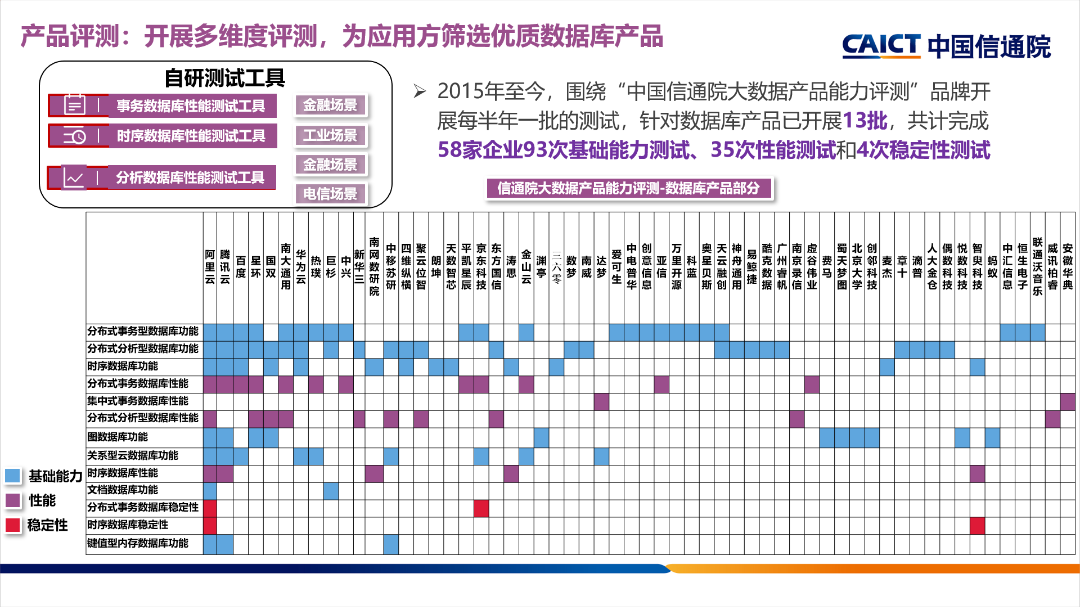
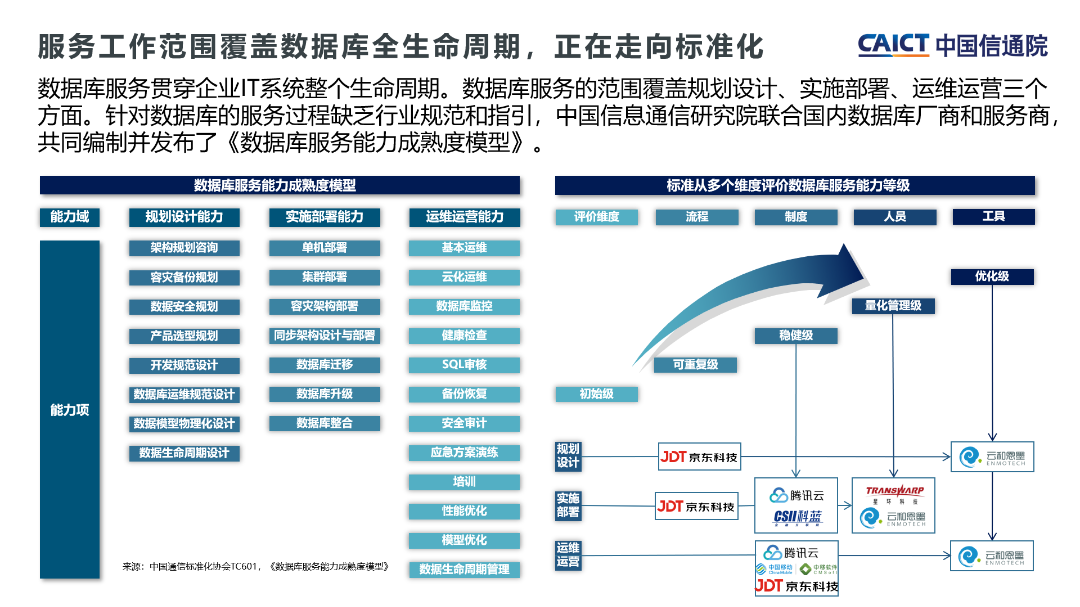
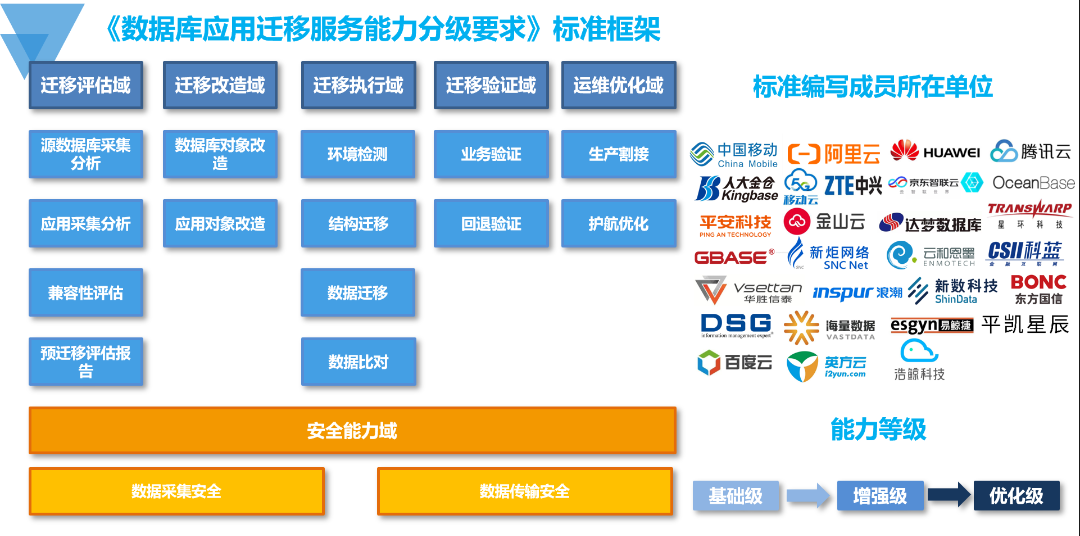
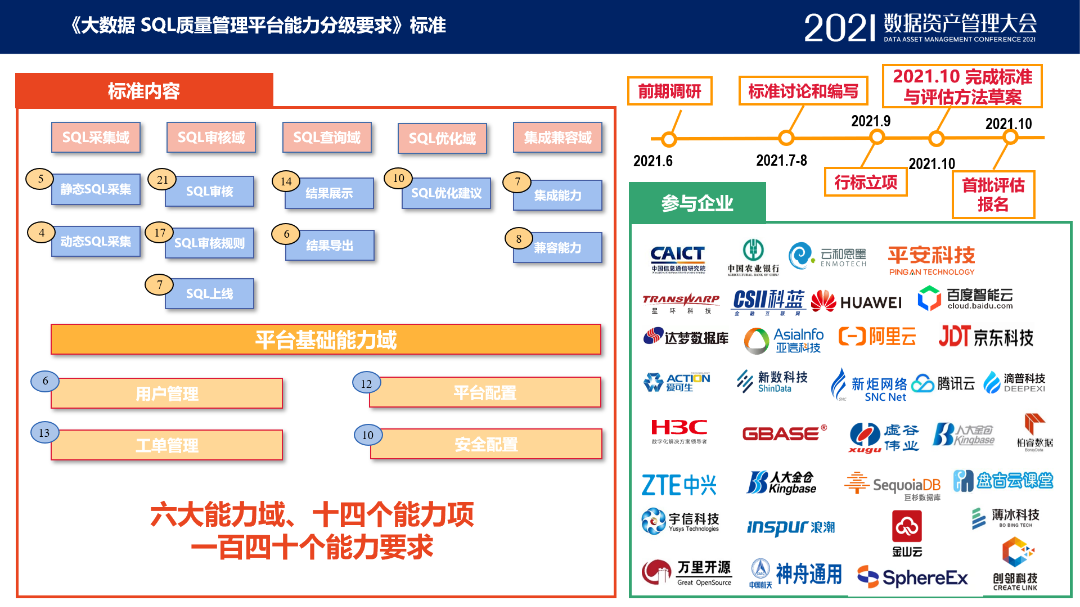
2021年7月至11月,中国信息通信研究院(以下简称“中国信通院”)对第十三批大数据产品能力-分布式分析型数据库共计8款产品进行了评测。阿里云实时数仓Hologres(原阿里云交互式分析)在报表任务、交互式查询、压力测试等方面通过了中国信通院分布式分析型数据库性能评测(大规模),并以8192个节点刷新了通过该评测现有参评的规模记录。
在本次评测中,Hologres是目前通过中国信通院分布式分析型数据库大规模性能评测中规模最大的MPP数据库产品。通过该评测,证明了阿里云实时数仓Hologres能够作为数据仓库和大数据平台的基础设施,可以满足用户建设大规模数据仓库和数据平台的需求,具备支撑关键行业核心业务数据平台的能力。
大数据实时数仓体系“纷繁芜杂”
随着互联网的发展和企业数字化转型进程的加速,数据的时效性变得越来越重要,如何利用数据更好赋能业务成为企业数字化转型的关键。而随着数据量出现指数型的增长,单机的数据库已经不能满足业务的需求。特别是在分析领域,一个查询就可能需要处理很大一部分甚至全量数据,海量数据带来的压力变得尤为迫切。
大数据技术便随之应运而生并不断演进。
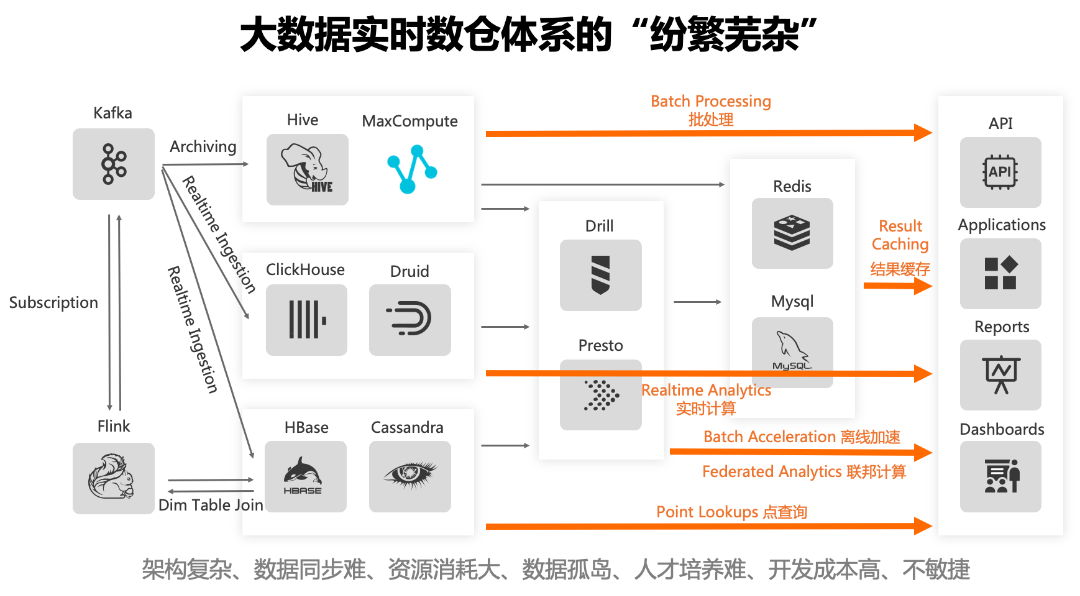
传统上,为了解决业务的不同需求和多元化的应用场景,离线数仓、流式计算、数据服务层共同组成了大数据处理的标准架构:Lambda架构。Lambda架构已被多数公司所采纳,它虽然解决了一些业务或者技术问题,但随着数据量的增加,应用复杂度的提升,其问题也逐渐凸显,主要有:
· 由多种引擎和系统组合而成,架构比较复杂,开发和维护成本高,学习成本高;
· 数据在不同的系统中存储多份,空间浪费,资源浪费;
· 实时和离线的处理流程是割裂的,无法很好的融合,数据一致性问题难以解决;
· 从使用上来说,不同的系统开发语言不一致,使用起来并不容易,学习成本非常高;
具体到阿里巴巴,早期也是通过Lambda架构搭建实时数仓,但因为业务众多且复杂,导致问题不断涌现。因此,不管是业务上还是技术上,业内都迫切希望能有一种更加优雅的方式去解决这些问题。
一站式实时数仓Hologres
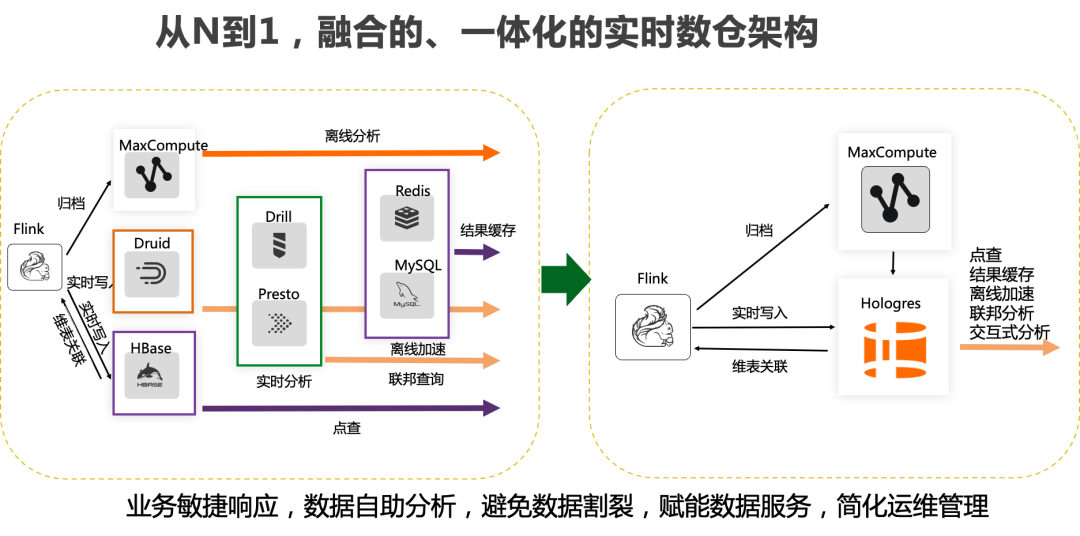
基于上述背景,阿里云从2016年开始探索对Lambda架构的优化,自研出实时数仓Hologres引擎来完成Lambda架构的替换,并不断在阿里多个核心场景沉淀,于2018年云上输出。
Hologres支持海量数据实时写入、实时更新、实时分析,支持标准SQL(兼容PostgreSQL协议),支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc),支持高并发低延迟的在线数据服务(Serving),与MaxCompute、Flink、DataWorks深度融合,提供离在线一体化全栈数仓解决方案。
Hologres的核心理念是通过一套系统一份语义完成实时和离线的处理,从而实现了技术统一、数据规范无冗余、开发简化与成本降低、数据出口统一,帮助业务更加高效快捷的构建一站式实时数仓。
大数据实时数仓场景相比数据库处理的数据量往往是成倍增加(TB级、PB级甚至是EB级)、数据处理的复杂度也相对更高。既要支持超大规模的部署与运维,还要平衡实时数仓的高性能诉求,同时还要保持高可用,对任何系统来说都是巨大的挑战。
实时数仓Hologres在设计架构之初就提前做了优化,采用云原生容器化部署的方式,基于Kubernetes on Fuxi作为资源调度系统,使其在部署上可以达到8192个节点甚至更大的规模,并且对于后续运维及调度的能力也有所保障。得益于资源调度架构设计和运维体系建设,Hologres在阿里巴巴内部核心场景历经多年双11生产考验,提供诸如多副本的高吞吐、资源隔离、读写分离等多种运维保障能力,在高负载高吞吐的同时实现高性能,实现生产级别的高可用,更好支撑业务,为企业的数字化转型提供了良好的支持。
客户案例
阿里巴巴智能客服部(简称CCO)为阿里集团内外的消费者和商家提供一线求助保障,其实时数仓承载着日均万+的人工客服,10亿+的用户求助声量,千万+的智能检索和预测服务。
客户需求/痛点
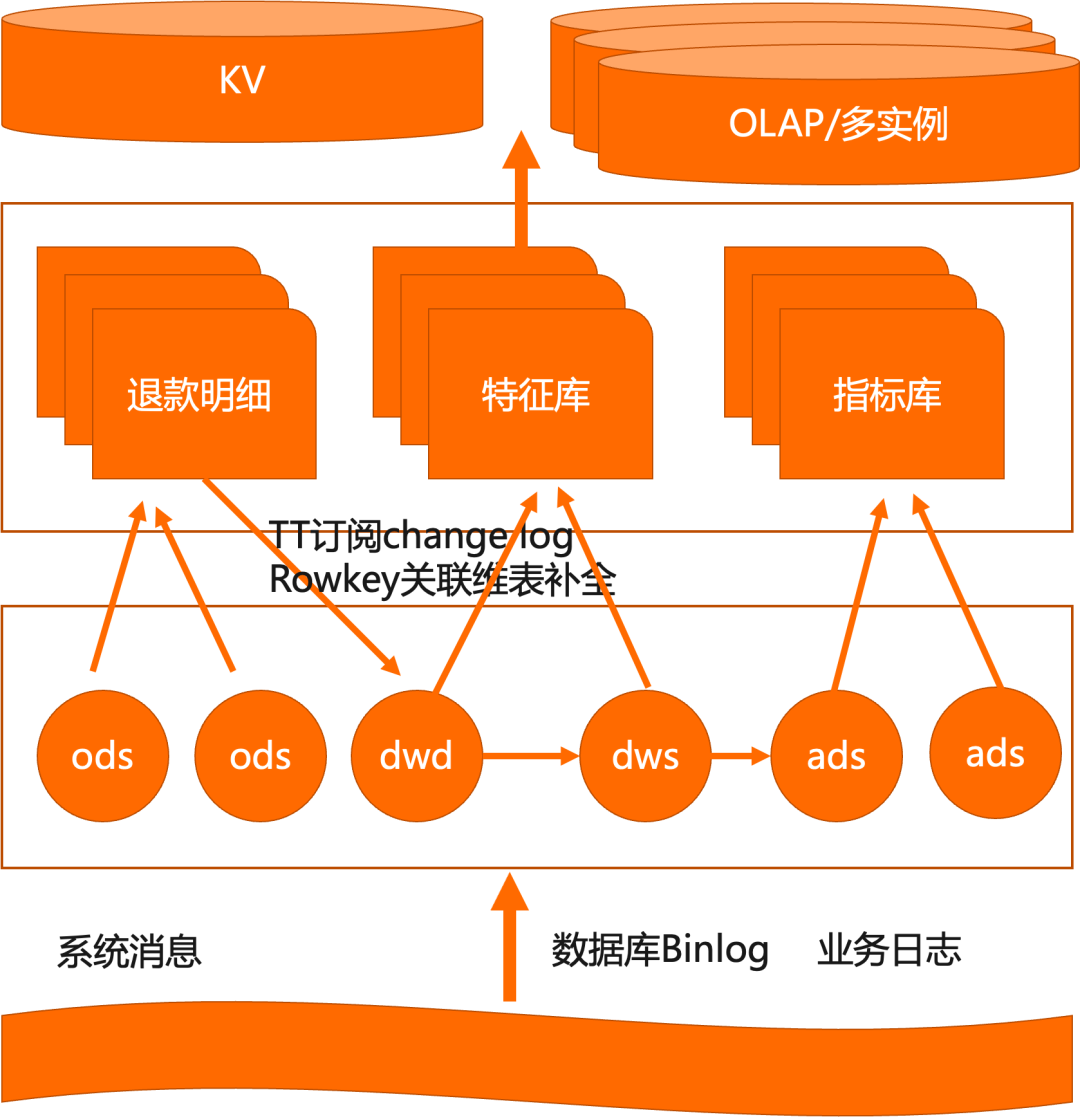
智能客服部早期实时数仓通过传统数据库构建,是非常典型的Lambda架构:
· 实时加工层,通过Flink订阅上游数据库Binlog的方式进行ETL处理、维表关联等,并最终输出到不同的引擎;
· 通过不同的服务引擎支持不同的服务形式,高QPS低Latency的服务场景使用HBase,低QPS较高Latency数据分析型使用OLAP交互式分析引擎;
· 而针对不同的场景还会设置不同的SLA等级,把不同保障等级的数据存放在不同的实例里,以减少用户查询对于底层引擎稳定性的影响,比如大促对外的实时大屏会做多链路高保,对内的分析看板则会降低保障。
随着业务量的增加,该架构也逐渐面临着一些的挑战和痛点:
1)实时加工链路长,任务冗余
· 上游数据源多,需要几十个任务完成加工,并通过KV引擎高效更新,导致加工链路长
· 大多数服务引擎不提供数据消费能力,数据想要2次消费,增加任务冗余
2)离线加工慢
· 离线任务多,数据导入慢,有大量的任务排队甚至加速失败,运维压力大
3)数据孤岛
· 不同的引擎提供数据出口,数据需要存储多份,造成数据的天然割裂,也很容易造成数据不一致。
· 不同的保障场景实例天然隔离,数据也冗余多份
· 架构复杂,元数据管理弱。
解决方案
在Hologres诞生之初,智能客户部便开始了与Hologres的合作,通过Hologres逐渐替换OLAP分析引擎和KV引擎
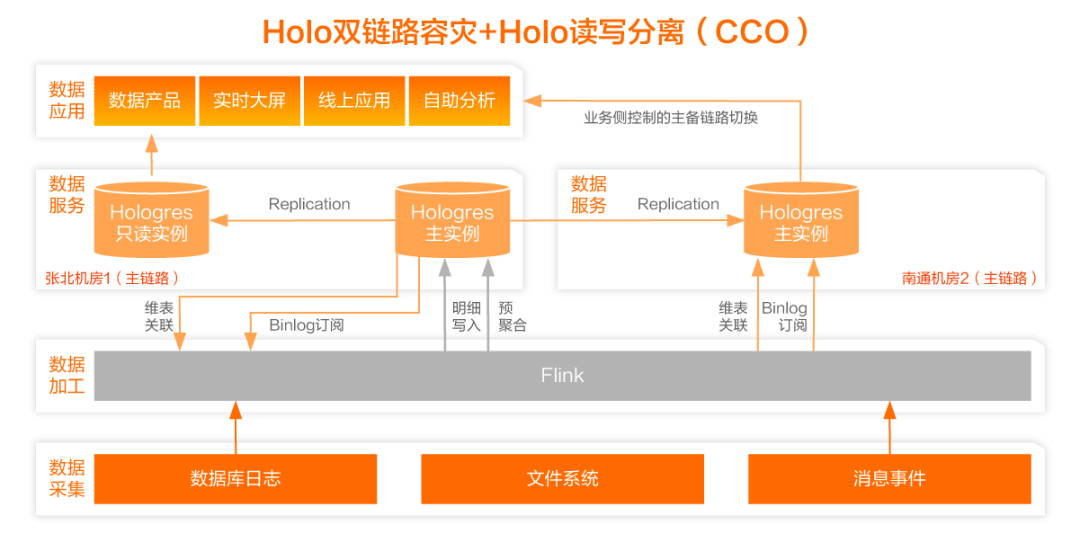
精简架构,数据链路如下:
· Flink(原Blink)处理完的数据直接写入Hologres,由Hologres统一存储数据,如果要2次消费,直接订阅Hologres Binlog,完成事件的全链路驱动;
· 由Hologres提供统一的数据出口,通过其行存表提供KV查询,列存表提供OLAP查询;
· 根据不同场景的SLA保障要求,以多实例共享存储的方式提供读写分离和多机房双链路容灾,减少冗余存储。
项目价值
通过使用Hologres,阿里智能客服部的整体项目收益如下:
· 精简架构,统一了数据存储、数据服务出口,同时支撑复杂多维分析和高QPS服务化查询,真正做到一站式实时数仓
· 简化实时加工链路,直接面向公共层的开发和复用,降低运维成本和提升开发效率。对离线数据(如MaxCompute)进行加速查询,缓解离线处理压力,提高查询性能。
· 完成了从传统数据仓库到新一代高可用实时数仓的升级,99.99%的查询在200ms以内返回,生产级稳定支撑了阿里历年双11等大促的核心场景。
· 整体资源成本下降30%+