




周末看到了一篇文章《核酸结果统计难?130行代码搞定!》,讲的是复旦大学的博士生,写了一段程序,将人工统计核酸的工作,转成了自动化,提高了工作效率,正如他所说,"只是用我学到的知识解决实际工作中的困难"。
我们从小就学习各种知识,重要的是怎么将这些知识运用到实际中,不光懂理论,还能和实践结合,这才是我们所要追求的。
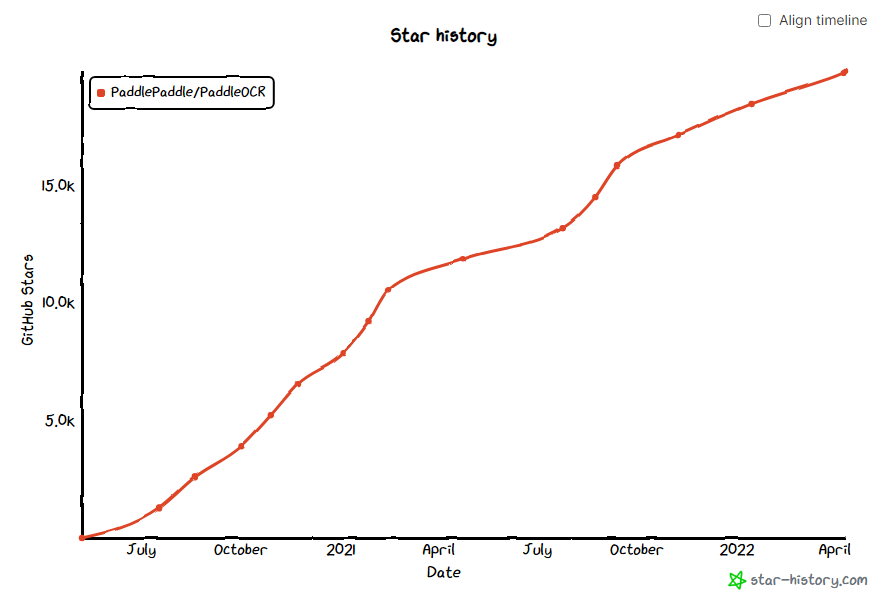
回到主题,文章中他说的用的是现成的OCR库,再加上用的Python,推测应该是PaddleOCR(https://github.com/PaddlePaddle/PaddleOCR),从GitHub上的star能看出他的关注度还是很猛的,
像百度、腾讯等厂商,都提供了付费的OCR服务,
GitHub上有很多OCR项目,
如果用Java写程序可以选择tessdata,
https://github.com/tesseract-ocr/tessdata
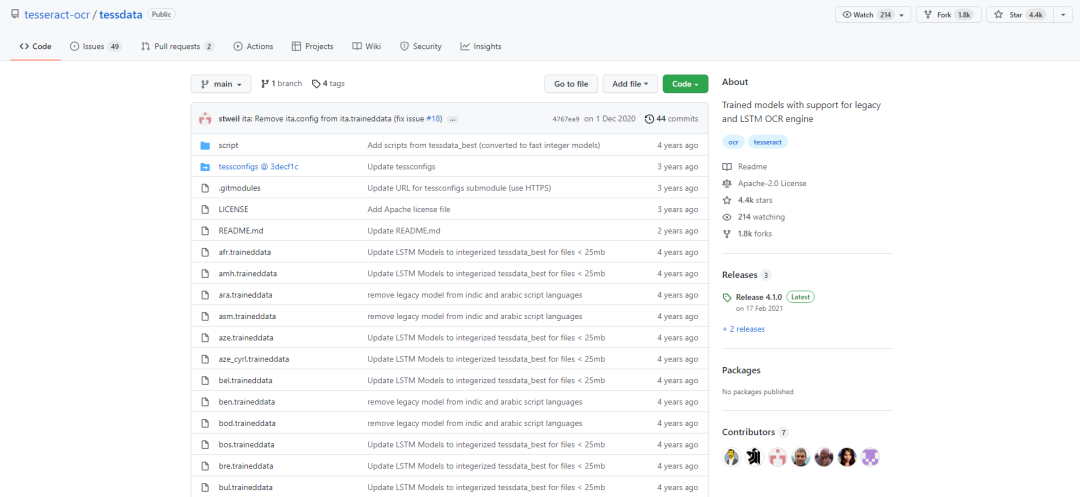
点击下载,然后解压缩,可以看到这些.traineddata,应该是数据文件,例如语言类的,中文集、英文集等,
如果用的maven,可以配置依赖库,
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>5.0.0</version></dependency>
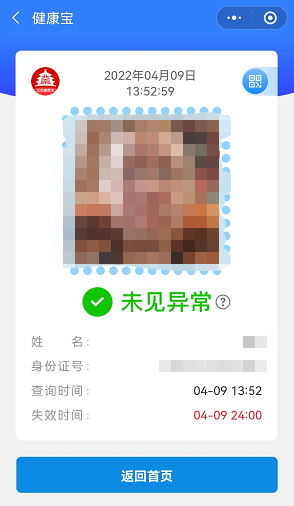
为了测试,我们尝试解析一张健康宝的图片,
程序如下,主要就是两步,第一步是指定数据集合的位置,设置解析语言,此处是中文(chi_sim),第二步就是指定待解析的图片路径,调用Tesseract的doOCR(),
package com.bisal.ocr;import java.io.File;import net.sourceforge.tess4j.Tesseract;import net.sourceforge.tess4j.TesseractException;public class Ocr {public static void main(String[] args) {Tesseract tesseract = new Tesseract();tesseract.setDatapath("C:\\ocr\\tessdata-main\\tessdata-main");// 简体中文:chi_sim,英文:engtesseract.setLanguage("chi_sim");try {String result = tesseract.doOCR(new File("C:\\ocr\\1.jpg"));System.out.println("result: " + result);} catch (TesseractException e) {e.printStackTrace();}}}
返回的就是这个,乱码应该是图片这些内容,但是一些关键信息还是能找到的,例如姓名、状态、时间等,而且结构相对比较固定,写下解析逻辑,就可以批量做了,
result: LS N 明 冬 jD{30% 匮 I 13:53〈 健 康 宝 … @2022 年 04 月 09 日一 13:52:59@ @ @ @ @ 8 @ @ @ 白 白 @...(为了安全,屏蔽一些内容)吴 严 绍“ 白@ G 8 8 8 8 8 日 @ @ @ @巳 t园 未 见 异 常 e姓 。名 : XXX查 询 时 间 : 04-09 13:52失 效 时 间 : 04-09 24:00
所以,像这种操作,技术上可能不难,难的是能不能想到通过这种方式,提高工作效率,降低工作成本,真正能做到学以致用。
近期更新的文章:
《最近碰到的问题》
文章分类和索引:
文章转载自bisal的个人杂货铺,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
