




4月15号凌晨3点,我被一个电话吵醒。
“你好,我们数据库升级有问题。”电话那头传来一个男人的声音。接连便是难懂的话,什么“数据库连接不上”,什么“ORA-308”之类 ,店内外充满了快活的空气……哦不,拿错剧本了。
我那时候贼困脑子处于宕机状态,难以理解 他说的情况。后来换了一个人,他告诉我,今晚版本升级,修改了账号密码后数据库连接不上了。
这是我第二次遇到密码修改导致的数据库故障了,于是我让对方提供了向日葵账号,登上去之后查了等待事件,看到大量的library cache lock和row cache lock,修改了event后重启数据库,问题解决。
本月第三次这个点被客户吵醒了,还好我本单身狗可以随时响应,不担心会影响到别人。
这次比较匆忙,从故障发现到解决大约10分钟,没有任何截图,下面回顾第一次遇到这个故障的情况:
那是去年9月份。有客户反馈,有个数据库账号修改完密码后,所有的关于这个账号的操作全部hang住,业务收到很大的影响。当时的等待事件是这样的:
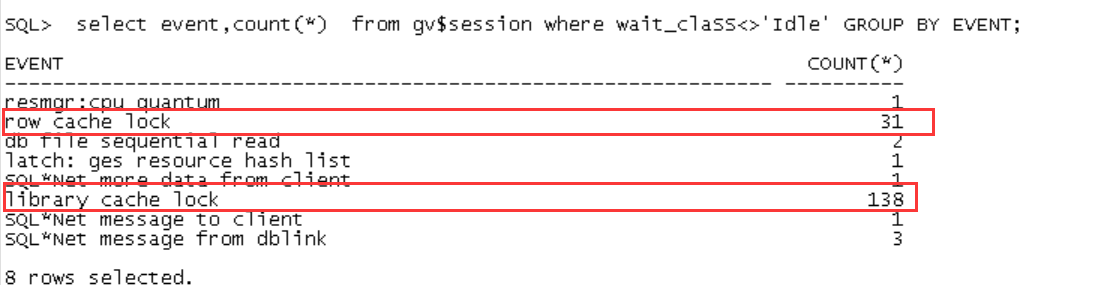
当时查看了row cache lock 的dc参数以及library cache lock的namespace,可以确定,争用发生在account status上面,可以确定,就是密码修改后部分应用进程使用错误密码连接数据库导致的问题。
当时第一个想到的解决办法,是让应用排查使用了错误密码的进程。但是客户表示排查需要很长时间。
第二个办法是停掉监听,杀掉所有会话后修改回原来的密码。客户表示停机需要申请。
这两个方法都不行,我突然有个疑问,密码我改过很多次了,一般情况下,用户账号密码错误次数太多,账号回直接锁住,为什么这次会出现大量异常的等待呢?
在群里面问了大佬,他告诉我,这是11g的密码延迟认证特性导致的。如果用户输入了错误的密码登录,那么随着登录错误次数的增加,每次登录前等待验证的时间也会增加。超时连接自动断开并返回一个错误。
找到问题根源,就很好解决了。彻底关闭特性使用以下的命令:
ALTER SYSTEM SET EVENT = '28401 TRACE NAME CONTEXT FOREVER, LEVEL 1' SCOPE = SPFILE;
但是由于客户表示不能重启数据库,所以用了下面的语句临时修改:
ALTER SYSTEM SET EVENTS '28401 TRACE NAME CONTEXT FOREVER, LEVEL 1';
至此问题解决。
