




前言
前面2篇文章我们介绍KunlunBase的查询优化原理和Project和Filter下推演示(KunlunBase 查询优化(一),KunlunBase查询优化(二)Project和Filter下推),本节讲述排序查询优化之排序下推。
一、order by下推
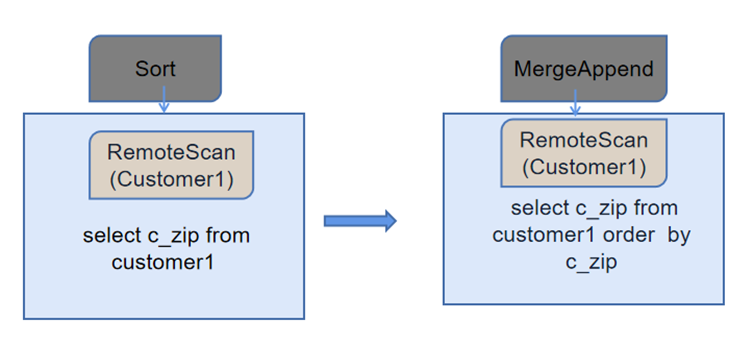
一条含有order的SQL的执行计划在如下生成过程中,Sort被下推到RemoteScan算子里面。
Sort下推的操作是异步方式,指令在各个数据节点并行执行,过滤数据后,将排序后的结果反馈给计算节点,降低了计算节点的负载。
下面我们来测试查看查询下推的执行计划
为支持排序下推,需要在KunlunBase设置如下如下参数为true:
set enable_remote_orderby_pushdown=true;
测试语句:
select c_zip from customer1 order byc_zip;
查看执行计划:
explain select c_zip fromcustomer1 order by c_zip;
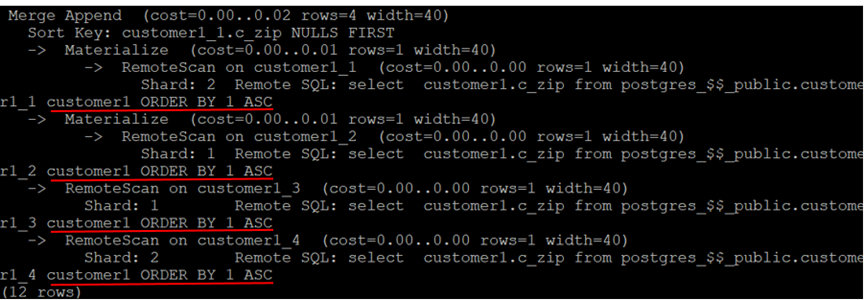
根据上面的执行计划,RemoteScan在传达了远程排序操作到每一个相关的存储节点,存储节点将结果反馈给计算节点再做Merge Append。
如果关闭排序下推的特性,执行计划会发生变化,排序操作将在计算节点执行。
演示如下:
set enable_remote_orderby_pushdown=false;
排序操作将在计算节点执行:
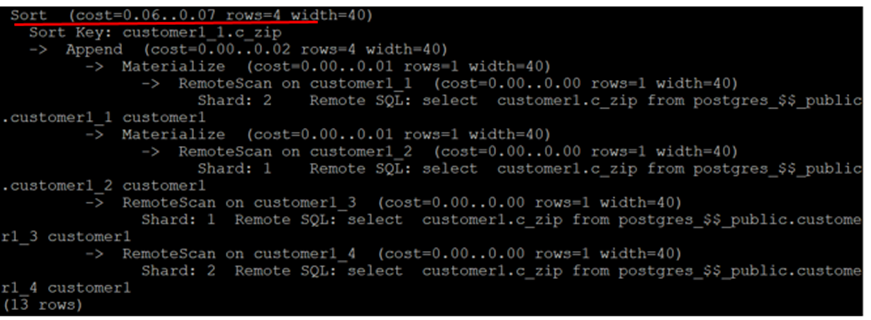
语句的执行过程:语句在计算节点改写后,下发到2个数据节点执行,从计算节点拉取符合条件的值到计算节点排序,排序后反馈给客户端。
二、性能比对
性能比对环境:
复制下方链接登录KunlunBase在线体验系统:
zettatech.tpddns.cn:8000/ci/index.php/Main/PGList
在SQL框中输入排序操作的语句,按执行键执行。
左边窗口是KunlunBase社区版本的执行信息(社区版不支持排序下推操作),右边窗口是KunlunBase企业版有下推操作的执行信息。
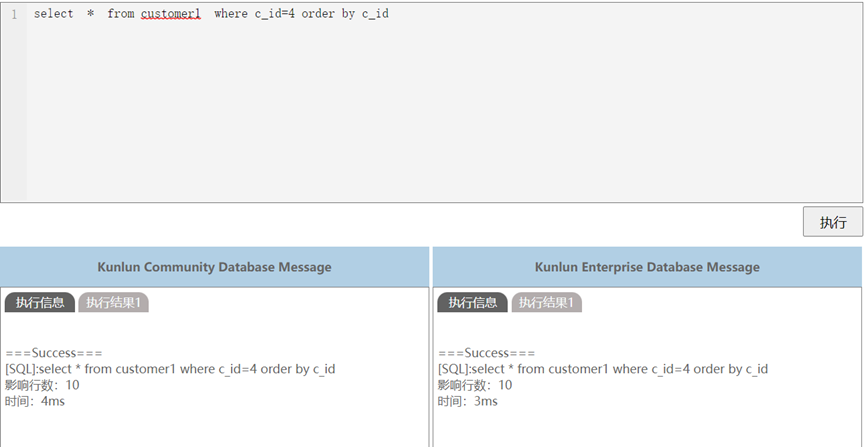
对比可以发现,order by下推后,执行效率提高了(执行时间由4毫秒下降到3毫秒)
推荐阅读
KunlunBase架构介绍
KunlunBase技术优势介绍
KunlunBase技术特点介绍
KunlunBase集群基本概念介绍
END
昆仑数据库是一个HTAP NewSQL分布式数据库管理系统,可以满足用户对海量关系数据的存储管理和利用的全方位需求。
应用开发者和DBA的使用昆仑数据库的体验与单机MySQL和单机PostgreSQL几乎完全相同,因为首先昆仑数据库支持PostgreSQL和MySQL双协议,支持标准SQL:2011的 DML 语法和功能以及PostgreSQL和MySQL对标准 SQL的扩展。同时,昆仑数据库集群支持水平弹性扩容,数据自动拆分,分布式事务处理和分布式查询处理,健壮的容错容灾能力,完善直观的监测分析告警能力,集群数据备份和恢复等 常用的DBA 数据管理和操作。所有这些功能无需任何应用系统侧的编码工作,也无需DBA人工介入,不停服不影响业务正常运行。
昆仑数据库具备全面的OLAP 数据分析能力,通过了TPC-H和TPC-DS标准测试集,可以实时分析最新的业务数据,帮助用户发掘出数据的价值。昆仑数据库支持公有云和私有云环境的部署,可以与docker,k8s等云基础设施无缝协作,可以轻松搭建云数据库服务。
请访问 http://www.kunlunbase.com/ 获取更多信息并且下载昆仑数据库软件、文档和资料。
KunlunBase项目已开源
【GitHub:】
https://github.com/zettadb
【Gitee:】
https://gitee.com/zettadb
