




DuckDB 不仅可以方便访问 Pandas DataFrame, CSV、Parquet、PyArrow,甚至可以方便地访问数据湖。
安装需要的包
pip install duckdb deltalake
DeltaTable
表示特定版本的增量表的状态。这包括哪些文件是当前表的一部分、表的结构以及其他元数据,例如创建时间。
加载本地文件系统的数据湖(当前版本)
path = "/tmp/iris_delta"from deltalake import DeltaTabledt = DeltaTable(path)
本次使用的测试数据由 PySpark
+Delta Lake
生成, 更多相关信息可以访问 Delta Lake 快速入门-PySpark 版
使用 DuckDB 访问
import duckdbcon=duckdb.connect()def dsql(sql): return con.execute(sql).df()ds = dt.to_pyarrow_dataset()sql = "select * from ds limit 3"dsql(sql)
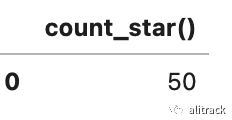
当前版本只有 50 条信息
sql = "select count(*) from ds"dsql(sql)
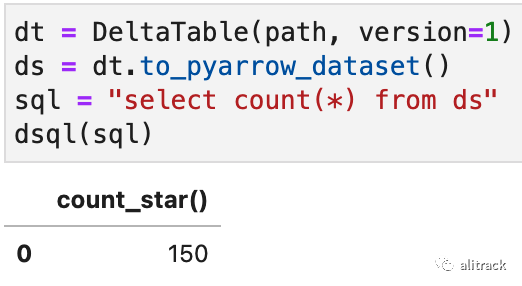
时间旅行(Time Travel)
除了可以访问最新版本的数据,还可以通过提供要加载的版本号来加载相应的版本:
dt = DeltaTable(path, version=1)ds = dt.to_pyarrow_dataset()sql = "select count(*) from ds"dsql(sql)
也可以在加载表格后,通过使用版本号或日期时间字符串更改版本:
dt.load_version(1)#等价于👇的from datetime import datetimetimestamp =(datetime .fromtimestamp(1650358332868 / 1e3) .astimezone() .isoformat())dt.load_with_datetime(timestamp)dt.files()
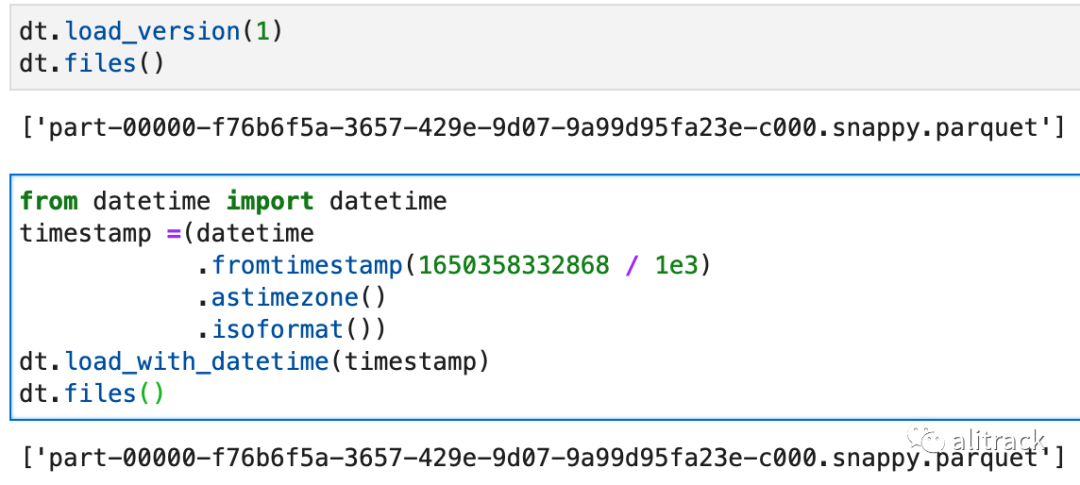
这里的时间戳可以通过下面的命令获得,
#版本历史信息dt.history()
返回
[{'timestamp': 1650358316226, 'operation': 'CREATE TABLE', 'operationParameters': {'isManaged': 'false', 'description': None, 'partitionBy': '[]', 'properties': '{}'}, 'isolationLevel': 'Serializable', 'isBlindAppend': True, 'operationMetrics': {}, 'engineInfo': 'Apache-Spark/3.2.1 Delta-Lake/1.2.0', 'txnId': '0b21cbea-5672-4367-84be-5d6c2fd07aef'}, {'timestamp': 1650358332868, 'operation': 'WRITE', 'operationParameters': {'mode': 'Append', 'partitionBy': '[]'}, 'readVersion': 0, 'isolationLevel': 'Serializable', 'isBlindAppend': True, 'operationMetrics': {'numFiles': '1', 'numOutputRows': '150', 'numOutputBytes': '2792'}, 'engineInfo': 'Apache-Spark/3.2.1 Delta-Lake/1.2.0', 'txnId': 'aea8a270-4f3d-4ad3-8a63-2d9aebedefa7'}, {'timestamp': 1650358460951, 'operation': 'CREATE OR REPLACE TABLE', 'operationParameters': {'isManaged': 'false', 'description': None, 'partitionBy': '["Species"]', 'properties': '{}'}, 'readVersion': 1, 'isolationLevel': 'Serializable', 'isBlindAppend': False, 'operationMetrics': {}, 'engineInfo': 'Apache-Spark/3.2.1 Delta-Lake/1.2.0', 'txnId': '679a731d-9456-4ed0-aa63-3ce8a4ece8bc'}, {'timestamp': 1650358516037, 'operation': 'WRITE', 'operationParameters': {'mode': 'Append', 'partitionBy': '[]'}, 'readVersion': 2, 'isolationLevel': 'Serializable', 'isBlindAppend': True, 'operationMetrics': {'numFiles': '3', 'numOutputRows': '150', 'numOutputBytes': '5612'}, 'engineInfo': 'Apache-Spark/3.2.1 Delta-Lake/1.2.0', 'txnId': '443c8613-6dd7-4442-9111-adfd8dca7a67'}, {'timestamp': 1650358641212, 'operation': 'DELETE', 'operationParameters': {'predicate': '[]'}, 'readVersion': 3, 'isolationLevel': 'Serializable', 'isBlindAppend': False, 'operationMetrics': {'numRemovedFiles': '3', 'executionTimeMs': '194', 'scanTimeMs': '192', 'rewriteTimeMs': '0'}, 'engineInfo': 'Apache-Spark/3.2.1 Delta-Lake/1.2.0', 'txnId': 'c6f4373f-3f7b-41ca-8fa1-11501dbd2715'}, {'timestamp': 1650358662597, 'operation': 'WRITE', 'operationParameters': {'mode': 'Append', 'partitionBy': '[]'}, 'readVersion': 4, 'isolationLevel': 'Serializable', 'isBlindAppend': True, 'operationMetrics': {'numFiles': '3', 'numOutputRows': '50', 'numOutputBytes': '5031'}, 'engineInfo': 'Apache-Spark/3.2.1 Delta-Lake/1.2.0', 'txnId': 'cee79e6b-63bc-48a1-9818-ccb37e17d811'}]
多种文件系统支持
除了本地文件系统,可以通过 storage_options
来配置存储后端,如 AWS S3,
storage_options = {"AWS_ACCESS_KEY_ID": "AWS_ACCESS_KEY_ID", "AWS_SECRET_ACCESS_KEY":"AWS_SECRET_ACCESS_KEY"}dt = DeltaTable("../rust/tests/data/delta-0.2.0", storage_options=storage_options)
或者,如果您有一个数据目录,您可以通过引用数据库和表名来加载它。目前仅支持 AWS Glue。
对于 AWS Glue 目录,使用 AWS 环境变量进行身份验证。
from deltalake import DeltaTablefrom deltalake import DataCatalogdatabase_name = "simple_database"table_name = "simple_table"data_catalog = DataCatalog.AWSdt = DeltaTable.from_data_catalog(data_catalog=data_catalog, database_name=database_name, table_name=table_name)dt.to_pyarrow_table().to_pydict(){'id': [5, 7, 9, 5, 6, 7, 8, 9]}
除了本地文件系统,还支持以下后端:
AWS S3
,由前缀 检测s3://
。可以使用与 CLI 相同的方式使用环境变量指定 AWS 凭证。Azure Data Lake Storage Gen 2
,由前缀 检测adls2://
。请注意, 必须按照说明设置 Azure 存储帐户[1]。Google Cloud Storage
,由前缀 检测gs://
。
更多的访问方式
除了使用 SQL 的方式访问,可以可以这样的方式
import duckdbfrom deltalake import DeltaTabledt = DeltaTable(path)ds = dt.to_pyarrow_dataset()ex_data = duckdb.arrow(ds)(ex_data
.filter("Species = 'virginica' and Sepal_Length > 7")
.project("Sepal_Length")
.to_df())
#返回
Sepal_Length
0 7.2
1 7.1
2 7.2
从上面的代码可以看出,DuckDB 其实是借助于强大的 DeltaTable
和 PyArrow
来实现对数据湖的访问。
参考资料
设置 Azure 存储帐户: https://github.com/delta-io/delta-rs/blob/main/docs/ADLSGen2-HOWTO.md
文章转载自alitrack,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
