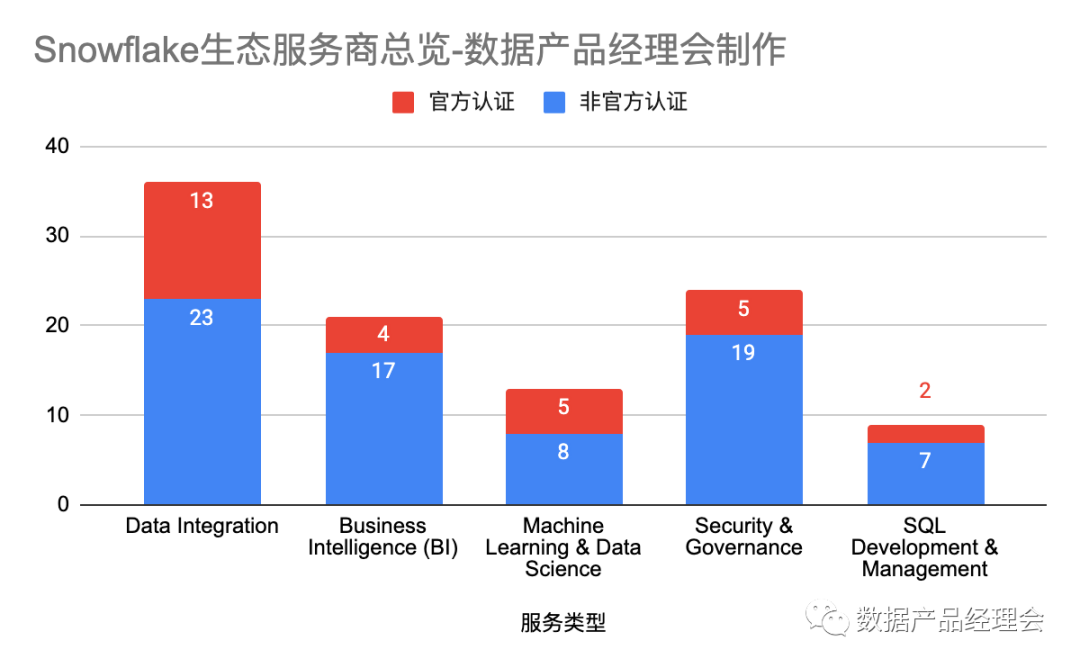
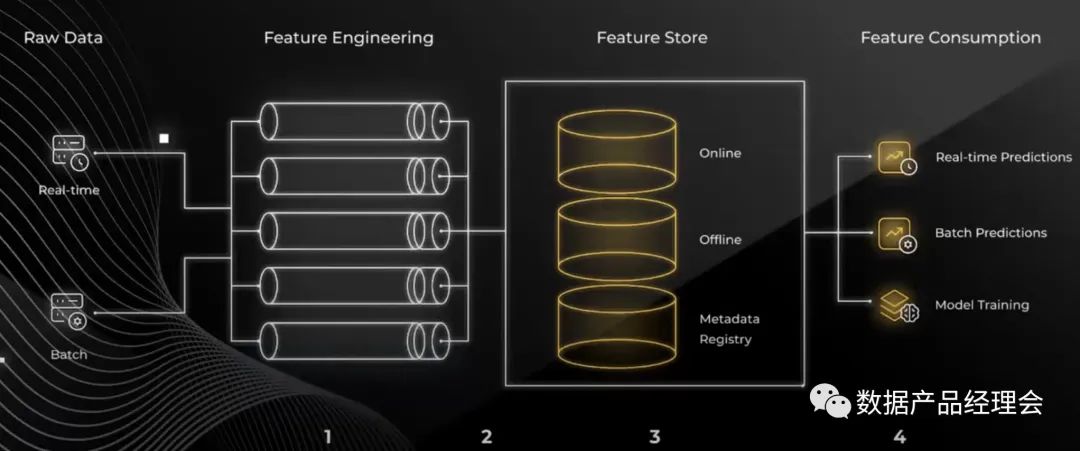
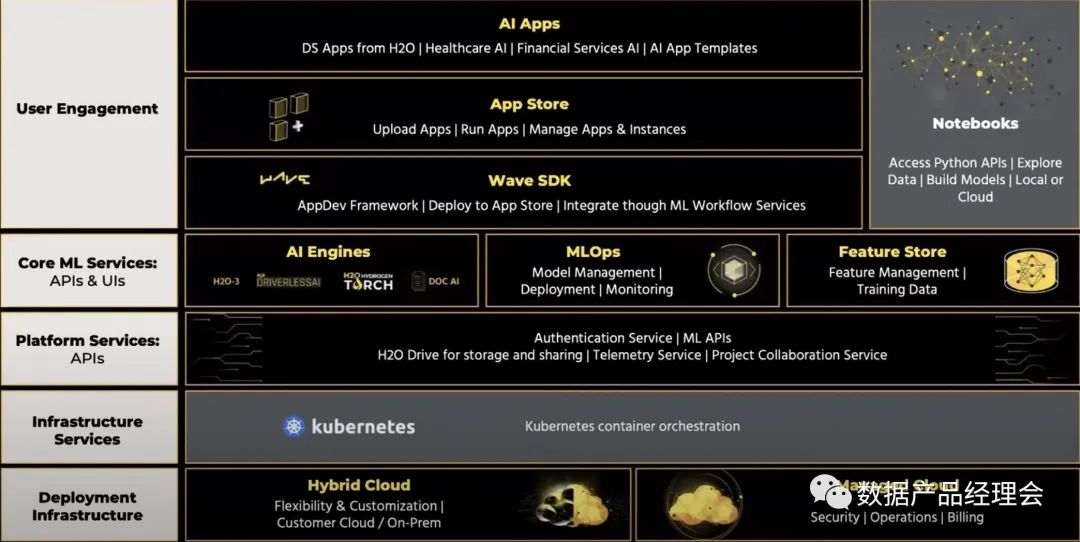
ML&DS这个板块的公司数量是整个Snowflake生态里面最少的。合作的公司仅有13家,独立的创业公司仅有4家:Dataiku、DataRobot、Domino、H2O.ai。融资方面,这个板块的合作伙伴累计融资22.4亿美金,估值最高的是DataRobot,达63亿美金,然后是Dataiku估值46亿美金,H2O.ai估值17亿美金,Domino估值10亿美金。从估值可以看出,这个板块的公司数量虽少,但是质量都很高。个人推测这类型的公司本身产品的研发门槛就比较高,你需要又懂算法,又懂统计,又懂工程还要懂用户场景,特别是DataRobot、Dataiku这类号称无代码ML的公司,就难上加难。此外在客户方面,虽然国外的DataScience发展相对会快一些,但是门槛也非常高,起码要求使用者有比较强的统计基础和一定的Python、SQL、R的代码基础,然后还需要精通业务逻辑,这类人才在国外都是香饽饽,在国内那真的是凤毛麟角了。不难看出,这类产品从产品的研发设计到客户本身的素质要求都会比较高,国内一般也只有大型公司才会配那么几位,所以市场容量比较有限。但是这类产品的用途非常广泛,产出的结果也非常的可观,远非BI这类统计分析类的产出可以相提并论的,用好了,对业务的指导意义极其巨大,我想这是为什么他们的估值普遍比较高的原因。Snowflake在生态图表中,把ML&DS部分跟BI是并列的,实际上二者使用流程也类似。只是与BI只能用来处理结构化数据不同,ML&DS对非结构化数据非常友好,也能产出非常多的insight(我们在后文会单独讲述DataRobot的时候可以举个例子)。在Snowflake从云原生数据仓库转向云仓一体化,并与Databricks进行竞争的的时候,ML&DS的应用是他们这个转型的巨大助力。许多朋友可能觉得这个玩意儿很高深,不知道怎么用,其实不然。从结果来说,ML&DS产出的业务insight是非常高级也非常实用的,使用门槛有一些高,需要使用人员有比较多的统计基础,接触过一些统计知识的朋友,会用Excel里面的预测功能、SPSS、Mltlab、R等工具能够很快上手。核心重点的是做好的模型的可解释性与可视化,就能够让这类产品在业务中被广泛的应用出来。但是产品架构上是需要完全重新设计的,以H2O.ai的产品架构为例:
滴滴在早期的比较大的问题是供给不足,也就是职业司机不多,那时候有非常多的兼职司机。但是具体哪些是职业司机?哪些是兼职司机?哪些可以从兼职转化到职业?以及基于此的订单分配逻辑都是没有清晰的目标的。比如一个司机跑多长时间,基本上就是职业了?一个司机月均收入达到多少,他就可以成为一个职业司机?带着子这些问题,当时采用SPSS,随机抽取一部分司机的数据,包含了其行驶、订单、作息、收入等各类数据进行了一个简单的K-means分类,分类结果出乎意料的好——所有的司机大致分成五类:第一类:职业司机,这类司机行驶时间长,一天超过12小时在线,收入高,可以判定就是职业司机。第二类:半职业司机,这类司机行驶时间在6-8小时,收入可观,喜欢跑大单,虽然不是完全职业,但是很接近职业司机。第三类:半兼职司机,这类司机有的时候在线时间特别长,有的时候又比较短,基本判断是之前的工作空闲时间分布不均匀,一般没事儿就出来跑。第四类:兼职司机,这类司机的路线非常固定,可以判断出来是日常上下班就顺路接一下人的兼职司机。第五类:玩票司机,基本上注册完了偶尔来拉几单,没啥规律, 也不靠这个挣钱。1、第一类职业司机分类中心点的各项指标,基本上就可以判定为成为一个职业司机的标准。后续订单分配就知道如何给这类司机更多的好单,支撑其在平台的生存和活跃。2、第二类、第三类司机是非常有可能转化成职业司机的,因此平时的运营活动就可以根据第一类职业司机的指标来进行设计,鼓励他们转型为职业司机。3、第四类司机则只需要高峰期派单即可,缓解高峰运力不足的情况,同时加一些运营手段,看是否可以往第三、第二类司机转化。现在来看,基本上滴滴都是职业司机了,而这种策略是在2014/2015年左右就开始制定和落地的。比如阿里数据银行有个子产品,数据工厂。他提供了一些模型,比如随机森林、罗辑回归等,和海量的品牌AIPL匿名化的明细数据,品牌商可以挑选诸如加购、浏览、进店、停留时长、关注等等用户行为来作为目标进行预测,最终找出高权重影响因子的用户行为,再返回数据银行把他们圈出来进行投放。使用这类产品的用户效率提升非常可观,只是大概只有10%(笔者负责数据银行产品期间)的品牌商有能力玩这一套,国内玩儿得好的比如蒙牛这类,都是超大型的企业了。这类产品对数据量的需求非常大,计算效率要求也非常高,可扩展性也要求非常好,因此非常适合云原生的企业去做。国内独立做ML&DS的创业公司好像不多,如果有读者朋友知道相关的信息,可以加好友(VX liuyangfjnu)深聊。-DataRobot-
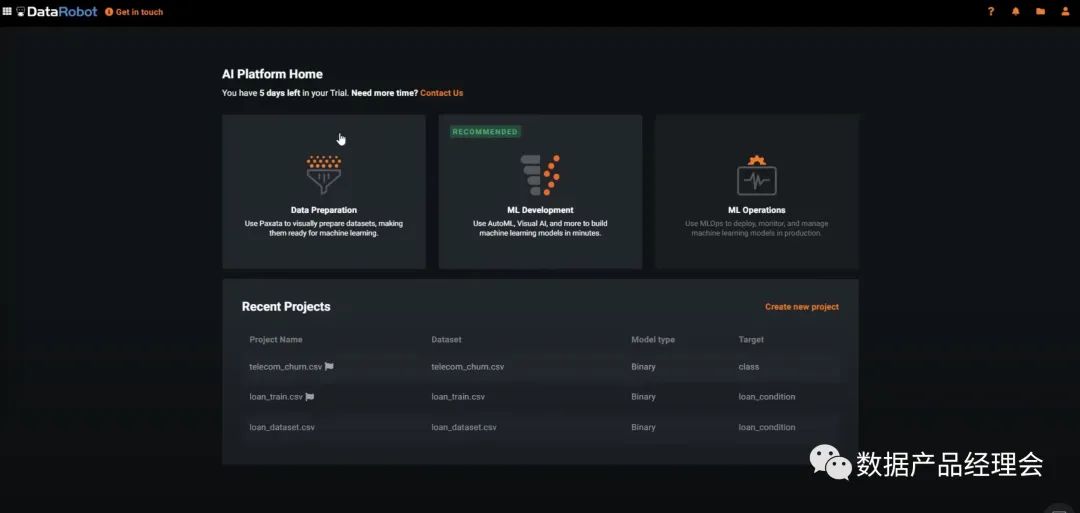
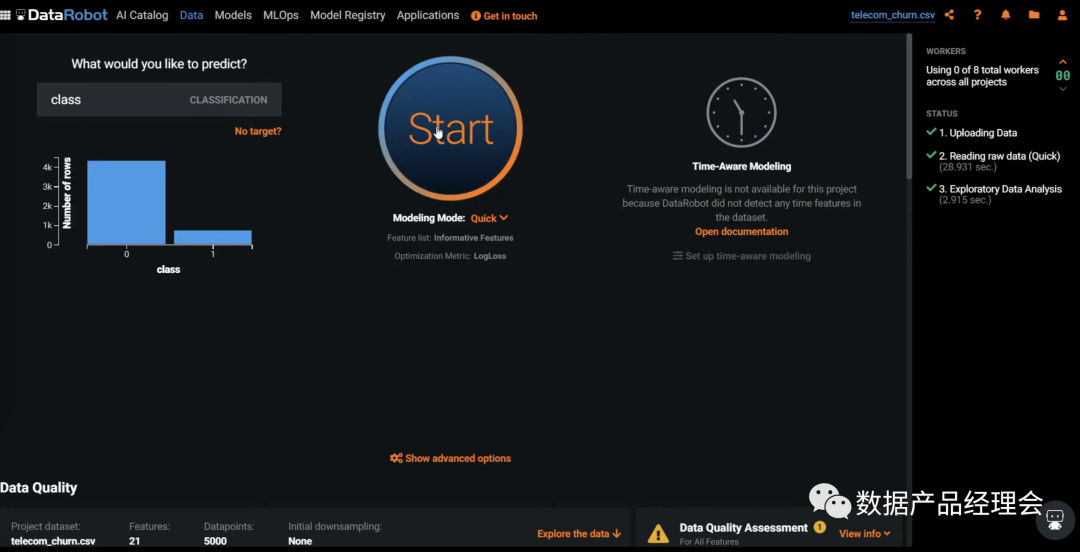
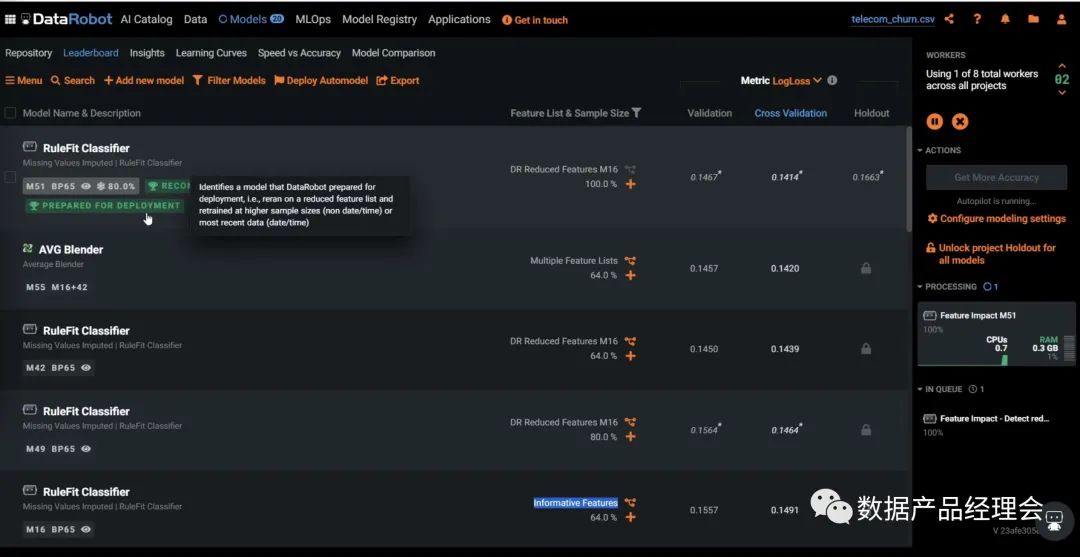
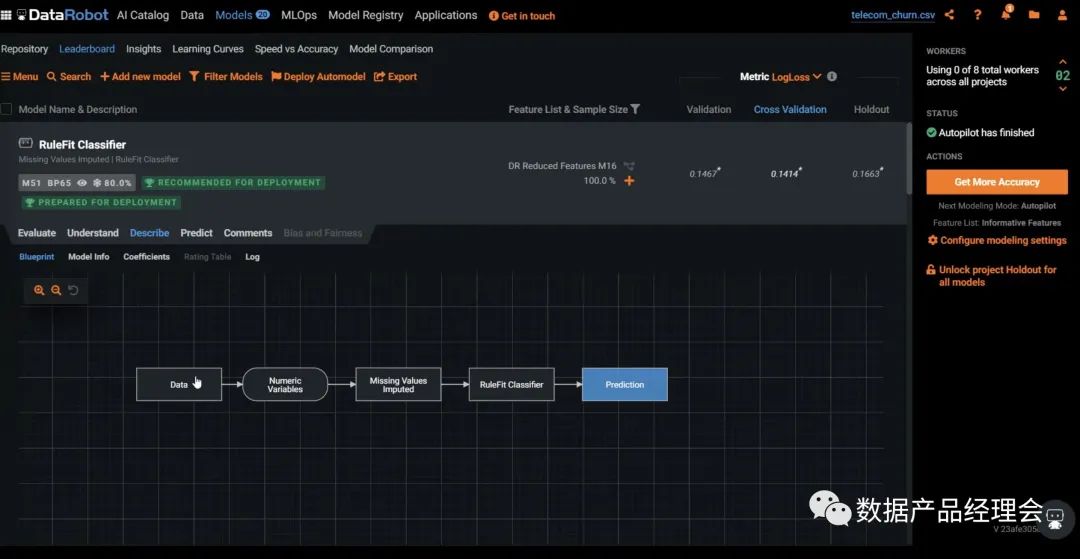
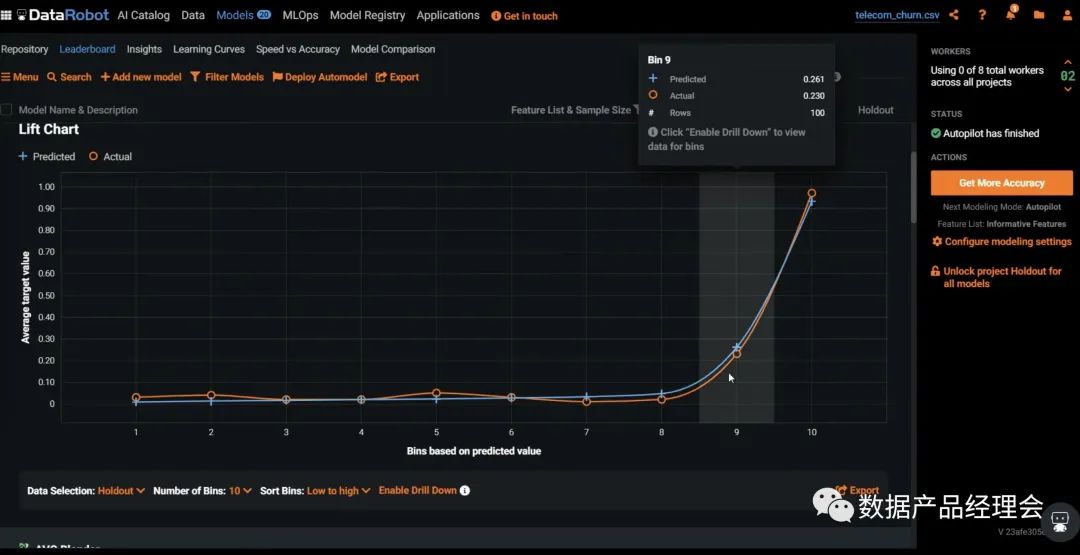
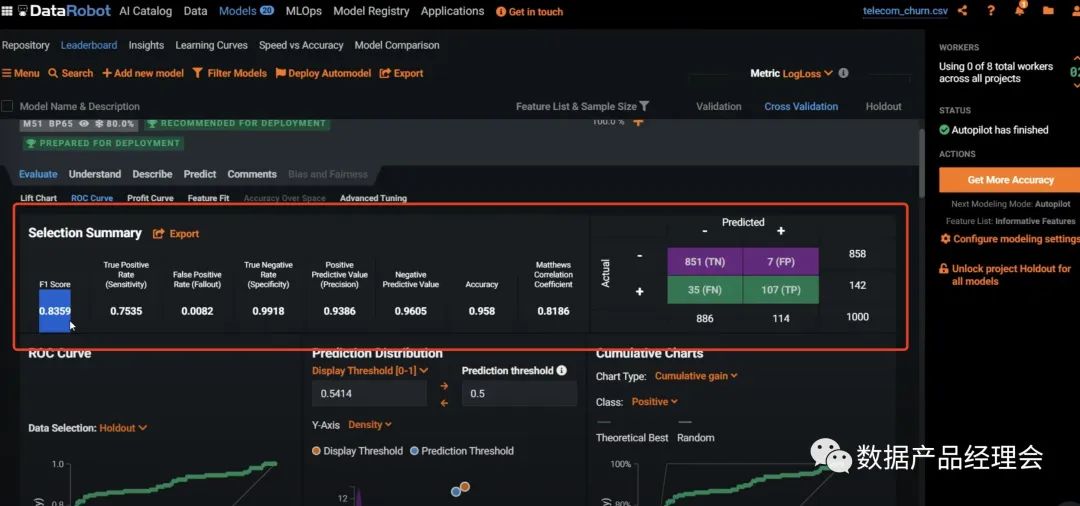
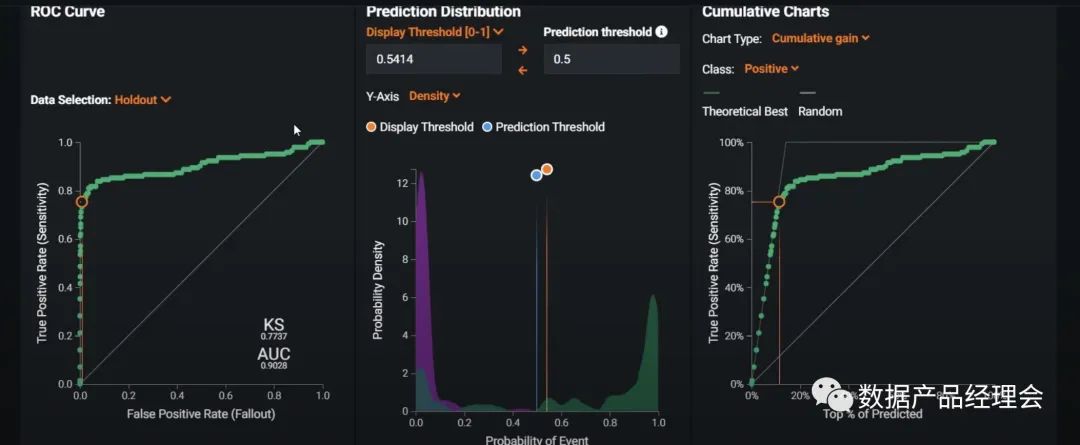
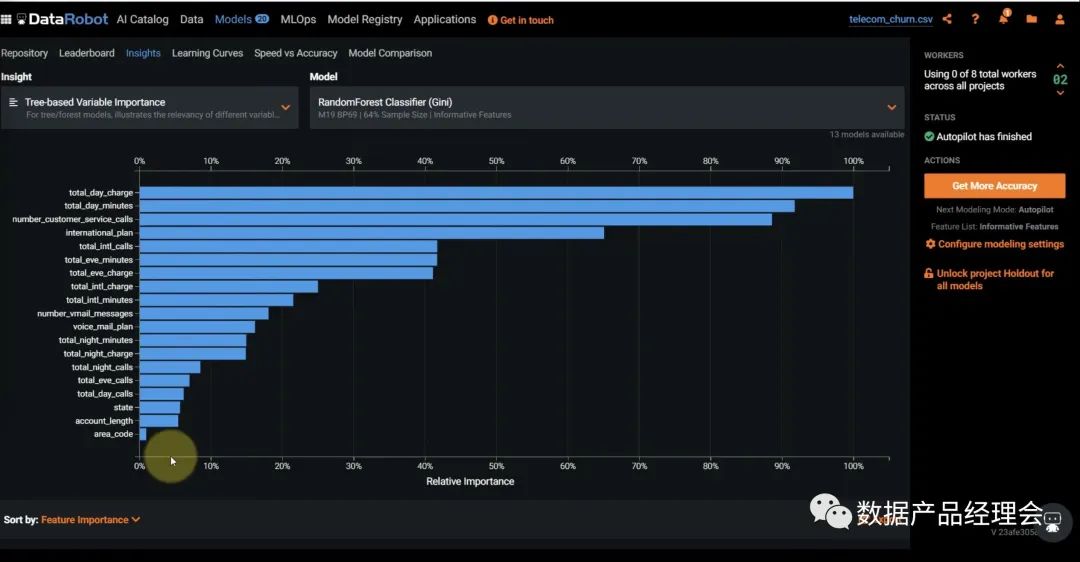
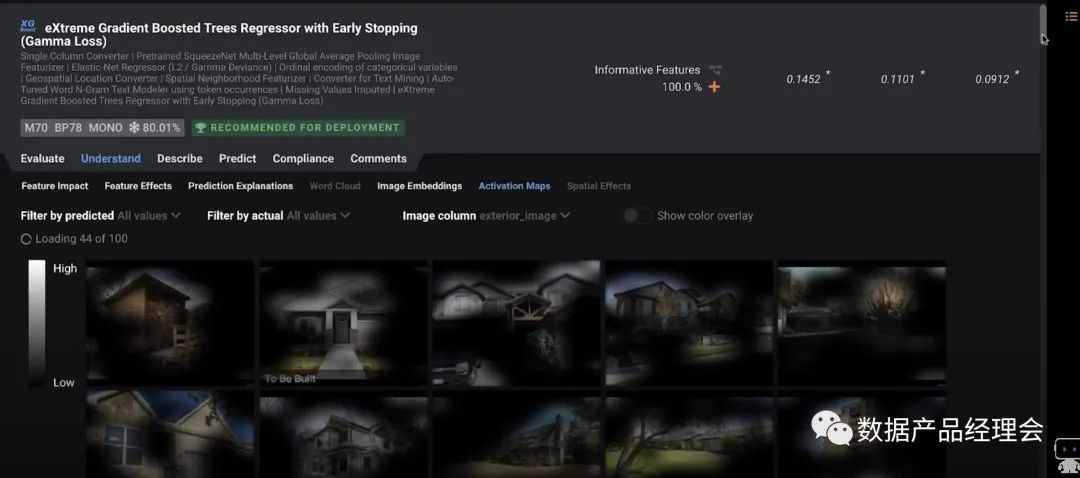
在Snowflake的生态合作伙伴中,ML&DS板块的非常少,而独立的创业公司仅有4家:Dataiku、DataRobot、Domino、H2O.ai。DataRobot是这个列表里面估值最高的公司,笔者就拿他做一个简单的分析。整个产品分为三个大的部分:Data Preparation数据准备、ML Development机器学习开发、ML Operation机器学习运营。咱们重点看看第二部分ML Development机器学习开发:这部分官方提供了多平台的多种模型来适配你的数据源,并且会根据你设定的目标来匹配最适合你的模型。选好预测目标,去除掉异常点之后,就可以一键运行了模型了:普通的测试数据集运行速度很快,大约4-10分钟就出结果了。途中第一个模型就是系统Run完之后推荐的最佳模型。点击这个模型你就可以查看模型的流程、模型的评分等,来看最终是否选择它:也提供了一个insight的模块,来让你仔细查看每一个影响因子的权重,方便你更好地理解这个模型的决策逻辑。前文我们提到会举个栗子:DataRobot的一个房产价值预估的模型案例中,就会针对房产图片以及地理位置等非结构化数据来做分析,并给出优化建议。完成模型测试之后,你就可以部署到线上生产环境,并且不断的去查看线上的模型运行情况,好及时做调整。全程几乎不涉及到代码开发,非常的简单易用,适用80%的业务场景。国内的零售行业在ML这个场景下的应用非常多,不过大部分都是in-house的团队在做,人员难找,效率也低,底层数据的处理也是个大难题,希望随着企业数字化转型进程的加快,有更多这类场景的产品能够被创造出来,加速从数字化到智能化。下一期我将继续介绍Security&Governance的部分,敬请期待...喜欢本文的朋友可以【转发】【点赞】【在看】【收藏】【留言】哟
| 刘洋,前阿里数据中台高级产品专家,全域数据中台总负责人,前小米广告产品总监。建有数据产品经理行业群,群员800余人,有兴趣的朋友可以加我微信【liuyangfjnu】入群讨论。 |
最后修改时间:2022-04-22 14:52:06
文章转载自
数据产品经理会,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。