





第一步:配置时钟同步
时钟同步可以采用ntpd同步,也可通过timesyncd;
采用timesyncd,需要修改
/etc/systemd/timesyncd.conf, 配置时钟同步客户端,通过timedatectl管理;
查看命令如下:
timedatectl show-timesync;
第二步:配置共享磁盘
由于KingbaseES高可用共享集群使用多节点共享磁盘,因此需要采用DAS、NAS、SAN等存储。本次采用FC磁盘阵列作为共享磁盘,FC磁盘整阵列就是光纤磁盘阵列;
共享磁盘客户端制作多路径绑定,可以提高磁盘的可用性,有效防止磁盘故障、网络故障导致的数据丢失或损坏;
首先在配置安装multipathd时,修改 /etc/multipath.conf (具体配置参见其他文章,不是本文重点),systemctl restart multipathd 启动;
在FC磁盘整列服务端划分磁盘,在磁盘客户端(也就是数据库服务端),执行rescan-scsi-bus.sh后,在主机群可以找到新创建的盘;
这时候进行多路径聚合multipath –v2;
查看多路径绑定multipath –ll 。
第三步:配置udev规则,固定磁盘名
01)udevadm info --query=all --name=/dev/dm-0
02)vim etc/udev/rule.d/60-scsi.rules
03)
ENV{ID_SERAIL}=="...",ENV{DM_WWN}=="..."RUN+="/bin/sh -c 'mknod /dev/chmpatha b $major $minor; chmod 0644 dev/chmpatha; rm -f dev/block/$major\:$minor; ln -s dev/chmpatha dev/block/$major\:$ninor'"
第四步:业务系统测试
问题来了。在进行断网的测试中,发现数据库一直在不停地切换节点。查看日志,发现是文件系统损坏导致的数据库无法启动。
采用fsck的方法进行修复,
fsck -a /dev/mapper/mpatha
但是未能修复!客户表明2天内必须解决。
第五步:问题排查
继续分析集群各节点的挂载记录,发现一些mpatha磁盘在系统重启后,在另一节点莫名其妙的挂载上了,目前推断可能是双挂导致的文件系统损坏,但是无法继续敲定重启为何导致双挂?
没有办法,只有将磁盘重新格式化,继续进行复现测试,终于抓住了问题,在异常重启后的机器上出现一条挂载记录:
/dev/mappper/mpatha 1007G 146M 956G 1%/media/root/9g0oc559-2d0a-4e88-a1e7-1b1badc9a7
实际上磁盘在另外节点正在被数据库管理进程使用,显然是双挂,那么这条挂载记录怎么来的?
重新思考操作的每一步骤,最终发现了问题的根本原因:
第六步:问题根因
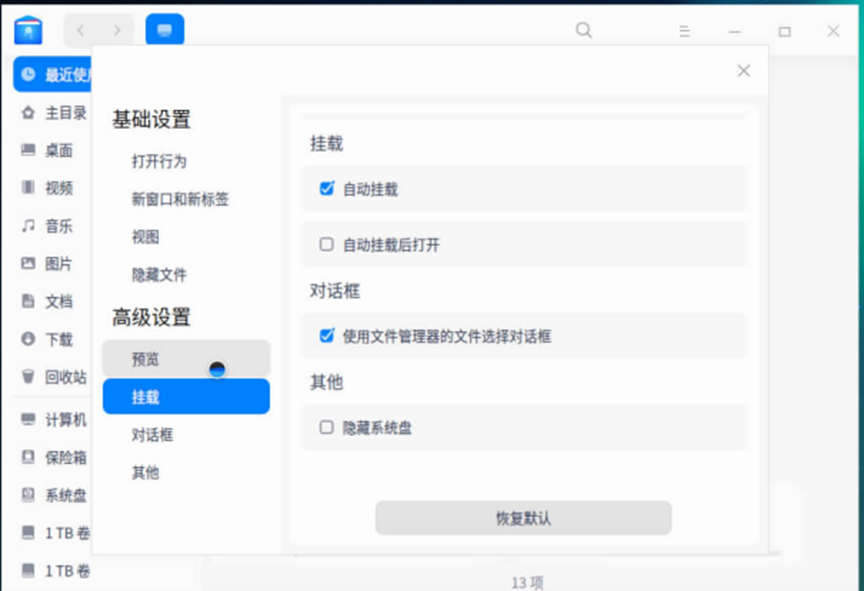
没错,是操作系统的自动挂载导致的双挂问题。
于是我们将"自动挂载"选项去掉,同时为了保险起见,将数据库服务端所在节点的图形界面关掉,在图形模式下使用如下命令可以切换到纯命令行模式:
如果需要每次重启都进入纯命令行模式,可以使用如下命令:
systemctl set-default multi-user.target

小结

