排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
1
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
AWR报告解析的一些心得(1)
AWR报告解析的一些心得(1)
白鳝的洞穴
2022-04-26
2176
昨天我说今天要发一个详细解读AWR报告的长文。确实是的,AWR分析我做了二十多年了,期间的感悟如果真的要认真写一写,这个内容够写一本书的。实际上如果回到5年前,我真的想就此写一本书,不过大家都要搞信创了,再花大力气去写本书可能会卖不动。不过我想稍微仔细的分析一下AWR报告的内容,可能会对我们国产数据库类似功能的开发有些帮助,因此我还是花点时间来写一篇文章吧。虽然说我想通过一篇长文来详细描述AWR,不过从今天的写作来看,这个任务恐怕无法完成。AWR报告才写了一点点,就已经将近3000字了。我想这篇文章哪怕分为上中下三部分也很难写完了。
这回我们选取了一个12.2版本的Oracle数据库的AWR报告,虽然这个系统的问题不是那么突出,不过比较新的版本包含的内容可以让我们更加清晰地了解Oracle在这方面的最新思路。关于报告头的内容我们就不多说了,从有效的内容开始说起。
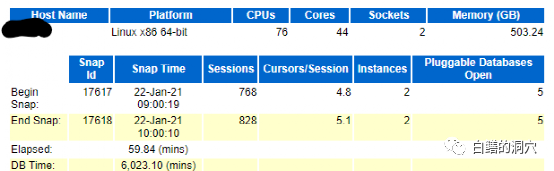
其实从报告的正文开始,我们就可以获得有用的信息了,服务器的内存,CPU核数,可以看出服务是2路X86,22核一路,一共44核,88线程。不过我们看到CPUS的数量是76,这个应该是设置了CPU_COUNT参数导致的。物理内存可以看到的是500G,应该是512G的物理配置。报告时间是1小时间隔的,DB TIME是6023,说明系统还是有些负载和等待的。会话数为768/828,说明这套数据库在这段时间内会话数是变化的,等会儿要重点看一看每秒Logon的指标是否过大。打开的PDB是5个,这是一个容器数据库架构的CDB的报告。
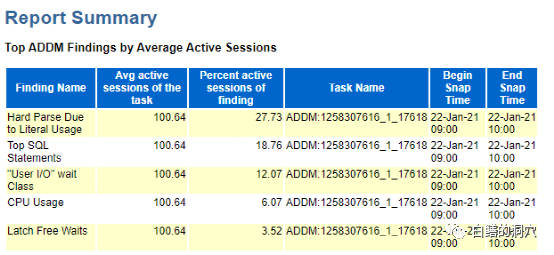
12C的AWR报告的最大特色是把AWR/ASH/ADDM三个报告的内容融合了。ADDM是根据timed model分析出来的系统中比较严重的问题,这个部分的内容容易引起经验不足的DBA的误解,把问题分析引向了一个错误的方向,最终导致找到了错误的答案,这是因为ADDM目前的智能化还不够,因此这个内容用起来不总是有效。
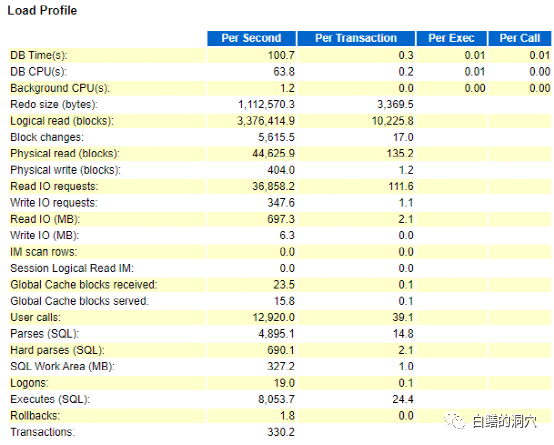
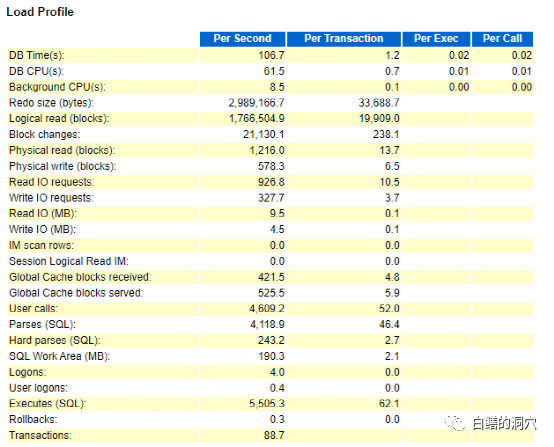
Load Profile很可能会被经验不足的DBA直接忽略,不过这个内容是我每次阅读AWR报告都会认真分析一阵子的内容。在绝大多数场景下,在分析所有的问题之前,先了解一下系统的负载情况是十分必要的。没有基于负载去分析等待事件,盲目性要大很多。Oracle选取出这些指标来代表负载,实际上对我们也是十分有参考意义的。12.2版本里增加了一个background cpu的指标,这个在11g里是没有的,如果这个指标过高,说明后台进程开销过大,系统可能存在一些不健康的问题。12C还新增了IM(IN-MEMORY DB)的指标,配置了IM特性的系统可以看到相关的负载。
如果你对比同一个数据库的不同时间段的多个LOAD PROFILE,那么可以关注一下每个事务对应的指标,如果这些指标相差比较大,那么说明这两份报告的应用负载类型存在较大差异,直接可比性并不是很强。也有一种可能是有一些SQL的执行计划发生了变化,导致了这些数据出现差异。
如果系统的负载出现了问题,那么从LOAD PROFILE上就可以看出一些端倪的,不过要更好的阅读这部分数据,需要你对系统的日常负载指标有一定的了解。对比着日常的历史数据,可以看出问题所在。比如rollbacks/秒从日常的1.8上升到10了,那么本身就说明一些问题了。
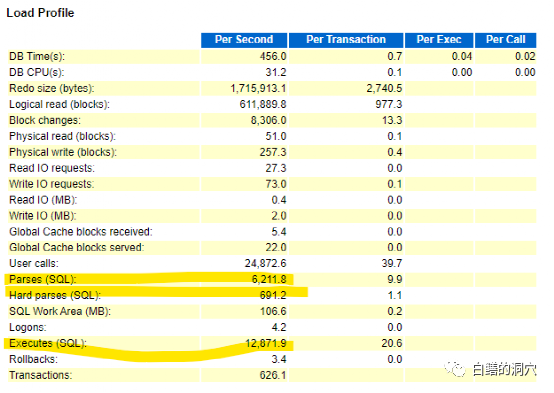
Oracle从众多指标中挑出了二十来个能够反映出负载的指标来,如果仔细分析分析,确实是很有道理的,早期的8i数据库,LOAD PROFILE里的指标更少:
上面的截图来自于一个8.1.7.4的数据库的Statspack报告,redo size反映出数据库并发修改数据的情况,逻辑读反映了数据库查询语句读取数据的并发情况,block changes是数据块被修改的并发情况,物理读反映了从磁盘中读取数据块的情况。USER CALLS是各种调用的综合,解析和硬解析反映出SQL解析的负载。其他我就不占用篇幅了去仔细描述了,不过这些经典的负载确确实实真是的反应出Oracle数据库的负载情况。目前的12.2的Load profile也是在这些核心的负载指标上进行了一定的扩展。
想要从Load Profile里获得更多有价值的信息,是需要你有足够的积累,如果你已经了解了各种规模的系统的Load Profile模型,那么你从这一小节很快就能发现系统当前的特点。如果你了解一个系统的各种时间窗口或者业务负载下的Load Profile,那么你很快就可以从中发现一些异常。这些对于一个初学者来说是有些困难的,不过别灰心,只要你坚持这方面的积累,一两年后,你就对此十分有数了。
目前的大多数国产数据库的LOAD PROFILE上表现的十分潦草,有些数据库干脆就不提供Load Profile。谈数据库的状态或者性能,不依托负载来谈,都是虚妄的,这方面国产数据库也应该学习学习Oracle,从自己的数据库监控指标中找出一些能够反映出负载的指标出来。
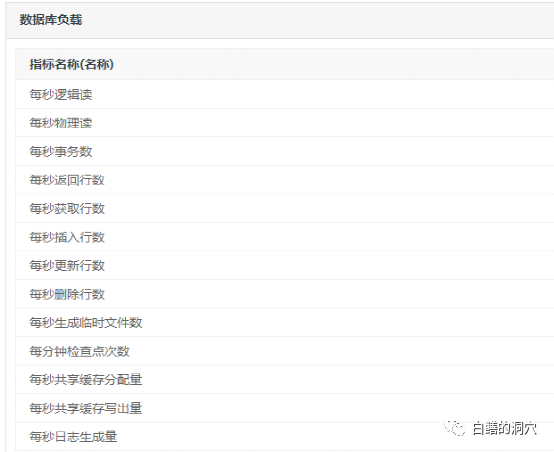
这是D-Smart 2.0以前针对PG数据库形成了一个的负载指标集,也可以说是我们自己版本的PG LOAD PROFILE,通过一段时间在生产环境中的应用,效果还可以,基本上能反映出系统的负载情况。不过在实际应用场景中使用一段时间后,我们进去准备对PG的Load Profile做一个较大的调整,加入一些新的因素,去掉一些价值不大的指标。Oracle的OWI经过了3个大版本后才形成了初步的LOAD PROFILE,我们构建自己的LOAD PROFILE也不可能一蹴而就。比如物理读的数量并不能直接反应出数据库物理IO的实际情况,因为很多物理读是从OS CACHE中获得的。这些问题如何解决,我们目前也在做一些尝试,不过如果能在内核中对这些统计数据进行细分,那么就可以获得更为准确地数据。
看完LOAD PROFILE,不要急着下结论,LOAD PROFILE反映出的仅仅是系统的负载,并不说明某种负载已经引起了系统的某个问题。如果想要确认系统存在什么问题,还需要往后看。后面的数据再参考LOAD PROFILE的数据,才能获得更有价值的信息。比如说后面发现并发执行的相关问题比较严重,而LOAD PROFILE能够印证这个问题,那么问题发现正确的可能性就很高了,否则就要打上一个问号了。
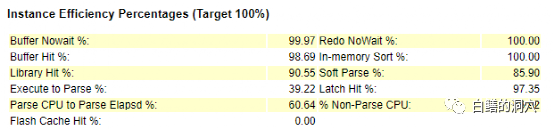
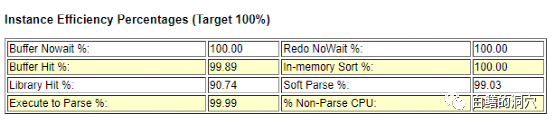
下一节是主要命中率的指标,早期运维Oracle数据库的时候,这些命中率是十分关键的,不过随着硬件的提升,这些指标的重要性没那么高了。虽然如此,这些命中率如果出现一些明显的问题,还是很说明问题的。Buffer nowait如果比较低,那么就需要分析后面的BBW是否比较严重了。而BUFFER HIT如果比较低,而后面发现IO负载较高,并且性能存在问题,那么提高BUFFER HIT就会有助于改善IO。
在目前的硬件上,硬件资源比较丰富,因此Execute to Parse的高低对系统的性能影响已经没有那么大了。Parse CPU to Parse Elaspsd如果比较低,那么说明SQL解析除了消耗CPU之外,还有大量的时间浪费在一些共享池相关的争用上了,如果后面的等待事件中发现解析和共享池方面的等待事件比较严重,平均延时比较高,那么优化PARSE还是有助于提升系统性能的。和PASRSE有关的百分比还有NON-PARSE CPU,如果这个比例比较低,那么说明消耗在PARSE上的CPU比较多。如果你的系统CPU资源出现了问题,那么减少PARSE还是会有效果的。
其他的命中率我就不一一解释了。大家也可以看出,单独看某些命中率指标是不够的,一定要参照相关的其他数据一起看才有意义。这些数据大多数在后续的报告中是可以看到的。
不过即使是如此简单的数据,要想看懂也不那么容易,比如上面这个案例,LIBRARY HIT比例只有不到90%,更值得怀疑的是non-parse cpu的比例只有17.2,%,也就是说数据库把80%多的CPU消耗在了SQL解析上了。看到这里,我们如果已经认真看了Load Profile的指标,那么我们很可能会得到一个比较明确的结论。
这套系统的PARSE和HARD PARSE都很高,应该是SQL解析方面的问题,最后通过对SQL的分析,发现有一条SQL的并发执行量有700多,没有使用绑定变量。通过把cursor_sharing设置为force,系统很快就恢复了正常。
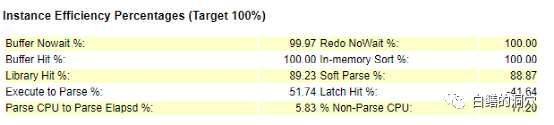
似乎分析这样的问题不难吧,看看non-parse%和library hit就可以大致定位问题了。这个技巧似乎很管用,不过并不是总是管用的。我们再来看一个案例。
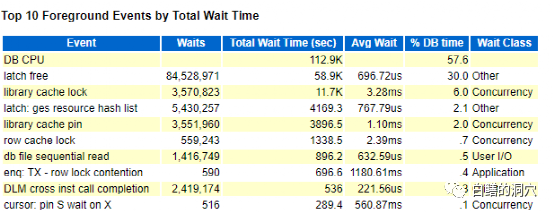
似乎现象上看有点类似上面的案例,LOAD PROFILE也有相似之处。
当时看到这个报告的时候,大家都觉得是SQL解析出了问题。TOP EVENT的数据更加佐证了这个结论。
不过我的直觉是对于一台8路服务器,这样的负载下,并不应该因为每秒200多的硬解析和5000+每秒的执行数量,就出现如此严重的问题,是不大应该的。常见积累下的经验让我并没有把重点关注放在这里,最后我们通过了一个GCS指标的异常,发现了一个因为Oracle BUG导致library cache性能问题。
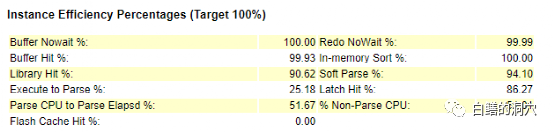
国产数据库的命中率指标也很丰富。
上图是opengauss的WDR报告,提供了5个命中率指标。其中Effective Cpu是CPU使用率与DB TIME的比值,WalWrite NoWait类似于Oracle的 REDO NOWAIT,NON-PARSE CPU也类似,不过指标的值有些令人怀疑。openGauss默认的也是会话内共享SQL,不同的会话是不共享SQL 解析的,实际上PARSE相关的命中率的参考性并不高。而soft parse比例就有点令人难以理解了。
实际上,上面的这些指标,除了一个不是很明确的buffer hit到底有没有用之外,似乎其他的命中率指标的指导意义并不大。5个指标中总觉得有些是凑数的,因为这些指标并没有随着数据库的负载、性能产生相应的变化。
达梦的命中率指标和Oracle早期的版本十分类似,实际上我这个压测负载的时候BBW还是比较严重的,不过在buffer nowait比例上并没有真正的表现出来。其他指标的指导性也并不是十分明确。总之我们没有从这里看出很多有价值的信息出来。后来我也和达梦的开发人员沟通过这些指标,后来他们定位为这是达梦AWR报告的一个BUG。
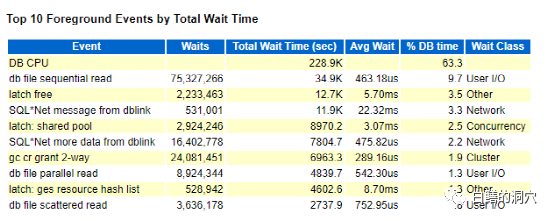
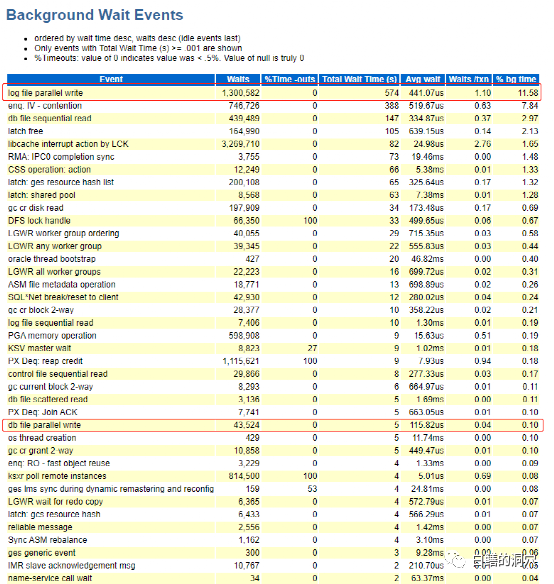
TOP EVENT是目前大多数DBA分析问题的首选分析内容,对于一个比较明显的问题,通过AWR的TOP EVENT一般是能够定位问题的。实际上WAIT EVENT分为前台和后台两部分,分别对应前台进程和后台进程。因为前台进程的并发量比较大,因此大部分分析都是使用前台的WAIT EVENT来分析的,TOP EVENT也仅仅针对前台。
不过Oracle的一部分工作是后台做的,比如lgwr/dbwr,我们应该从background EVENTS里去看这些指标才能找到这些等待事件。
要想完整的看懂这些等待事件实际上也并不容易。我们需要理解这些等待事件产生的原因,才能真正通过这些等待事件去分析出系统的主要问题在什么地方。对这些等待事件的认知我们已经花了十多年的时间。
目前这些成果已经成为构建D-SMART运维知识图谱的一部分。解读这些等待事件的方法前阵子我已经发过一篇文章,理解OWI的基本原理,在实践中不断总结才能不断地积累。而目前我们针对开源数据库的等待事件分析,大部分要通过源码的阅读来完成。最近我们通过这个方法,已经完成了对openGauss扩展的等待事件的分析工作,openGauss的等待事件比标准的PG数据库多了一倍还多,从这里我们也看得出来,openGauss对PG内核的改造还是相当大的。这部分内容已经成为最近发布的D-SMART 2.1版本的知识图谱的一部分。
前两天我写过一篇文章,写了梳理国产数据库等待事件根因的艰辛。我们不断地和数据库厂商的技术人员沟通,希望能够获得一些有价值的信息,不过似乎大部分国产数据库原厂的技术人员对此也知之甚少。很多时候,我们不得不从开源的源代码中去获得一些灵感,这种非直接的知识来源,其验证的成本还是挺高的。
写到这里,这篇文章已经有接近4000字了。今天就写到这里吧,实际上等待事件分析是分析AWR第一个高潮点,大多数DBA的分析重点也放在这个地方了。我想明天,我们可以认认真真的来讨论一下如何解读这部分的内容。
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨