




随着业务数据量增长原来设置的 300M 大小 redo 日志组已经出现各种小问题,“log file switch (checkpoint incomplete)” 等待事件,alert 日志中经常出现“Checkpoint not complete”检查点未完成等信息说明需要重建 redo 日志组,下面来一起看下 RAC 与 ADG 如何重建 redo 日志组。
RAC 主库重建 redo 日志组
首先查看 redo 日志组及大小
set linesize 250 pages 300
COLUMN groupno FORMAT a6 HEADING 'Group'
COLUMN thread FORMAT a6 HEADING 'Thread'
COLUMN member FORMAT a50 HEADING 'Member'
COLUMN redo_file_type FORMAT a10 HEADING 'Redo Type'
COLUMN group_status FORMAT a12 HEADING 'Group Status'
COLUMN member_status FORMAT a15 HEADING 'Member Status'
COLUMN bytes FORMAT 999,999 HEADING 'Size(M)'
COLUMN archived FORMAT a10 HEADING 'Archived?'
BREAK ON groupno
SELECT to_char(f.group#) groupno, to_char(l.thread#) thread, f.member member, f.type redo_file_type, l.status group_status, f.status member_status, l.bytes/1024/1024 bytes, l.archived archived
FROM v$logfile f, v$log l
WHERE f.group# = l.group# ORDER BY f.group#, f.member;
Group Thread Member Redo Type Group Status Member Status Size(M) Archived?
------ ------ -------------------------------------------------- ---------- ------------ --------------- -------- ----------
1 1 +REDO01/EDW/ONLINELOG/group_1.263.1037405633 ONLINE ACTIVE 300 YES
1 +REDO02/EDW/ONLINELOG/group_1.265.1037405633 ONLINE ACTIVE 300 YES
1 +REDO03/EDW/ONLINELOG/group_1.259.1037405751 ONLINE ACTIVE 300 YES
1 +REDO03/EDW/ONLINELOG/group_1.268.1037405635 ONLINE ACTIVE 300 YES
2 1 +REDO01/EDW/ONLINELOG/group_2.262.1037405633 ONLINE CURRENT 300 NO
1 +REDO02/EDW/ONLINELOG/group_2.266.1037405633 ONLINE CURRENT 300 NO
1 +REDO03/EDW/ONLINELOG/group_2.258.1037405763 ONLINE CURRENT 300 NO
1 +REDO03/EDW/ONLINELOG/group_2.267.1037405635 ONLINE CURRENT 300 NO
3 1 +REDO01/EDW/ONLINELOG/group_3.261.1037405633 ONLINE ACTIVE 300 YES
1 +REDO02/EDW/ONLINELOG/group_3.264.1037405633 ONLINE ACTIVE 300 YES
1 +REDO03/EDW/ONLINELOG/group_3.257.1037405771 ONLINE ACTIVE 300 YES
1 +REDO03/EDW/ONLINELOG/group_3.269.1037405635 ONLINE ACTIVE 300 YES
8 2 +REDO01/EDW/ONLINELOG/group_8.257.1037405655 ONLINE ACTIVE 512 YES
2 +REDO02/EDW/ONLINELOG/group_8.260.1037405667 ONLINE ACTIVE 512 YES
2 +REDO03/EDW/ONLINELOG/group_8.262.1037405677 ONLINE ACTIVE 512 YES
9 2 +REDO02/EDW/ONLINELOG/group_9.258.1037405701 ONLINE ACTIVE 512 YES
2 +REDO02/EDW/ONLINELOG/group_9.259.1037405691 ONLINE ACTIVE 512 YES
2 +REDO03/EDW/ONLINELOG/group_9.261.1037405711 ONLINE ACTIVE 512 YES
10 2 +REDO02/EDW/ONLINELOG/group_10.257.1037405729 ONLINE CURRENT 512 NO
2 +REDO03/EDW/ONLINELOG/group_10.256.1037405719 ONLINE CURRENT 512 NO
2 +REDO03/EDW/ONLINELOG/group_10.260.1037405739 ONLINE CURRENT 512 NO
21 rows selected

可以发现日志组大都处于 ACTIVE 活跃状态,部分处于 CURRENT 状态,但没有 INACTIVE 状态的,而且日志组大小不一样,前面三组为 1024M,每组有 4 个成员,后面三组大小为 512M 但只有 3 个成员。
后台 alert 日志中经常出现“Checkpoint not complete”检查点未完成的信息,如下图所示:
Thread 1 cannot allocate new log, sequence 1816543
Checkpoint not complete
Current log# 3 seq# 1816542 mem# 0: +REDO01/EDW/ONLINELOG/group_3.261.1037405633
Current log# 3 seq# 1816542 mem# 1: +REDO02/EDW/ONLINELOG/group_3.264.1037405633
Current log# 3 seq# 1816542 mem# 2: +REDO03/EDW/ONLINELOG/group_3.269.1037405635
Current log# 3 seq# 1816542 mem# 3: +REDO03/EDW/ONLINELOG/group_3.257.1037405771
2022-03-17T16:30:16.053214+08:00
Thread 1 advanced to log sequence 1816543 (LGWR switch)
Current log# 1 seq# 1816543 mem# 0: +REDO01/EDW/ONLINELOG/group_1.263.1037405633
Current log# 1 seq# 1816543 mem# 1: +REDO02/EDW/ONLINELOG/group_1.265.1037405633
Current log# 1 seq# 1816543 mem# 2: +REDO03/EDW/ONLINELOG/group_1.268.1037405635
Current log# 1 seq# 1816543 mem# 3: +REDO03/EDW/ONLINELOG/group_1.259.1037405751
2022-03-17T16:30:16.168849+08:00
TT02 (PID:22579): SRL selected for T-1.S-1816543 for LAD:2
2022-03-17T16:30:16.342747+08:00
ARC1 (PID:22567): Archived Log entry 5673988 added for T-1.S-1816542 ID 0x30a949 LAD:1
2022-03-17T16:30:41.531006+08:00
Thread 1 cannot allocate new log, sequence 1816544
Checkpoint not complete
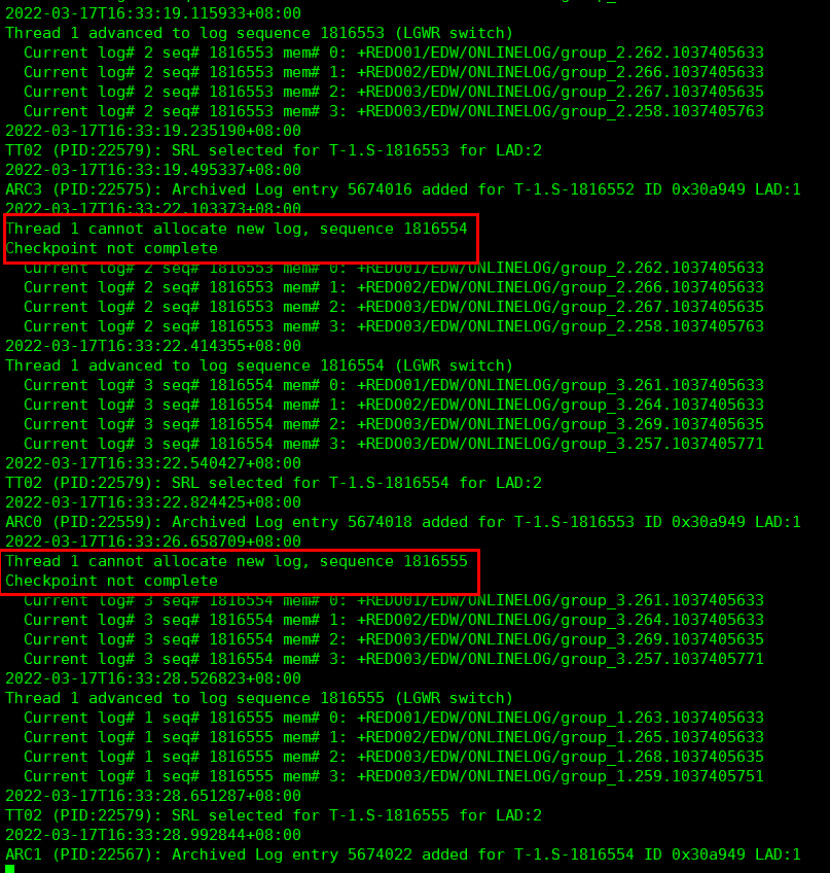
现需重建 redo 日志组,将 1024M和 500M的日志组修改为 6 组 1G大小的 redo 日志,且每组 4 个成员。
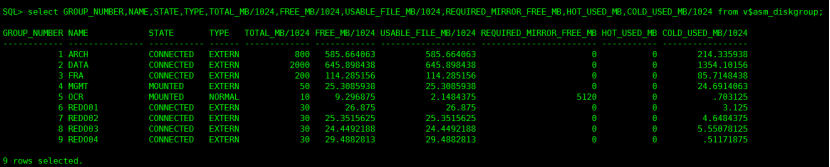
查看磁盘组大小
如果是单机环境,df -h 查看文件系统空间大小。
set lin 1000 pagesize 999
col PATH for a30
col NAME for a15
col FAILGROUP for a15
select GROUP_NUMBER,DISK_NUMBER,OS_MB/1024,TOTAL_MB/1024,FREE_MB/1024,NAME,FAILGROUP,PATH,FAILGROUP_TYPE,header_status,state from v$asm_disk order by 1;
select GROUP_NUMBER,NAME,STATE,TYPE,TOTAL_MB/1024,FREE_MB/1024,USABLE_FILE_MB/1024,REQUIRED_MIRROR_FREE_MB,HOT_USED_MB,COLD_USED_MB/1024 from v$asm_diskgroup;
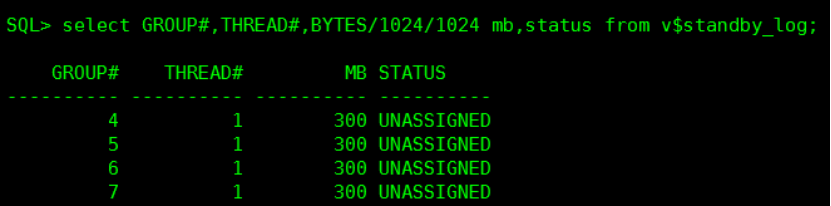
查看主库是否添加 standby log
select GROUP#,THREAD#,BYTES/1024/1024 mb,status from v$standby_log;
删除 standby log
alter database drop logfile group 4;
alter database drop logfile group 5;
alter database drop logfile group 6;
alter database drop logfile group 7;
添加新的 redo 日志组
SELECT to_char(f.group#) groupno, to_char(l.thread#) thread, f.member member, f.type redo_file_type, l.status group_status, f.status member_status, l.bytes/1024/1024 bytes, l.archived archived
FROM v$logfile f, v$log l
WHERE f.group# = l.group# ORDER BY f.group#, f.member;
ALTER DATABASE ADD LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') size 1024M;
ALTER DATABASE ADD LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') size 1024M;
ALTER DATABASE ADD LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') size 1024M;
ALTER DATABASE ADD LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') size 1024M;
ALTER DATABASE ADD LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') size 1024M;
ALTER DATABASE ADD LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') size 1024M;
删除老的 redo 日志组
切换日志使其状态变为 INACTIVE 后将原 redo 日志组删除。
alter system switch logfile;
alter system switch logfile;
alter system switch logfile;
alter system archive log current;
SELECT to_char(f.group#) groupno, to_char(l.thread#) thread, f.member member, f.type redo_file_type, l.status group_status, f.status member_status, l.bytes/1024/1024 bytes, l.archived archived
FROM v$logfile f, v$log l
WHERE f.group# = l.group# ORDER BY f.group#, f.member;
alter database drop logfile group 1;
alter database drop logfile group 2;
alter database drop logfile group 3;
alter database drop logfile group 8;
alter database drop logfile group 9;
alter database drop logfile group 10;
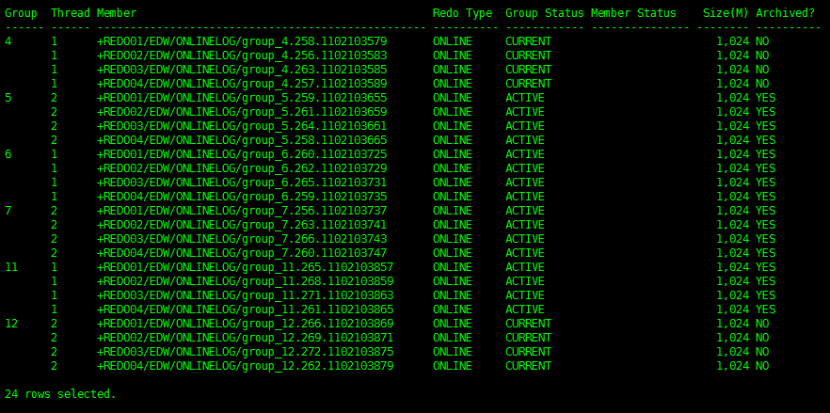
然后可在主库继续添加 standby log 日志组,或直接在备库添加。
添加 standby 日志组:
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 1 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
ALTER DATABASE ADD standby LOGFILE THREAD 2 ('+REDO01','+REDO02','+REDO03','+REDO04') SIZE 1024M;
查看日志组
col Member for a120
select l.group#,l.MEMBER,l.type,l.status,s.BYTES/1024/1024 mb from v$logfile l,v$standby_log s where l.TYPE='STANDBY' and s.group#=l.group# order by group#;

GROUP# Member TYPE STATUS MB
---------- ------------------------------------------------------------------------------------------------------------------------ -------------- -------------- ----------
4 /data/oradata/EDWDG/onlinelog/o1_mf_4_hpmf72z2_.log STANDBY 500
5 /data/oradata/EDWDG/onlinelog/o1_mf_5_hpmf9v1s_.log STANDBY 512
6 /data/oradata/EDWDG/onlinelog/o1_mf_6_hpmfbcnl_.log STANDBY 512
7 /data/oradata/EDWDG/onlinelog/o1_mf_7_hpmfc7sl_.log STANDBY 512
11 /data/oradata/EDWDG/onlinelog/o1_mf_11_hm7c22f9_.log STANDBY 512
12 /data/oradata/EDWDG/onlinelog/o1_mf_12_hm7c36jf_.log STANDBY 512
15 /data/oradata/EDWDG/onlinelog/o1_mf_15_hpmfoww7_.log STANDBY 512
16 /data/oradata/EDWDG/onlinelog/o1_mf_16_hpmfpgv1_.log STANDBY 512
8 rows selected.
select GROUP#,THREAD#,BYTES/1024/1024 mb,status from v$standby_log;
重建备库 standby 日志组
检查主备同步情况
set linesize 150;
set pagesize 20;
column name format a13;
column value format a20;
column unit format a30;
column TIME_COMPUTED format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
取消日志应用
alter database recover managed standby database cancel;
修改日志管理模式为手动
show parameter standby_file_management
alter system set standby_file_management='manual';
show parameter standby_file_management
查看日志组
set lines 200 pages 9999 LONG 5000
col member for a80
select a.thread#,a.group#,b.member,b.type,a.bytes/1024/1024 MB from v$log a,v$logfile b where a.group#=b.group#
union all
select a.thread#,a.group#,b.member,b.type,a.bytes/1024/1024 MB from v$standby_log a,v$logfile b where a.group#=b.group#;
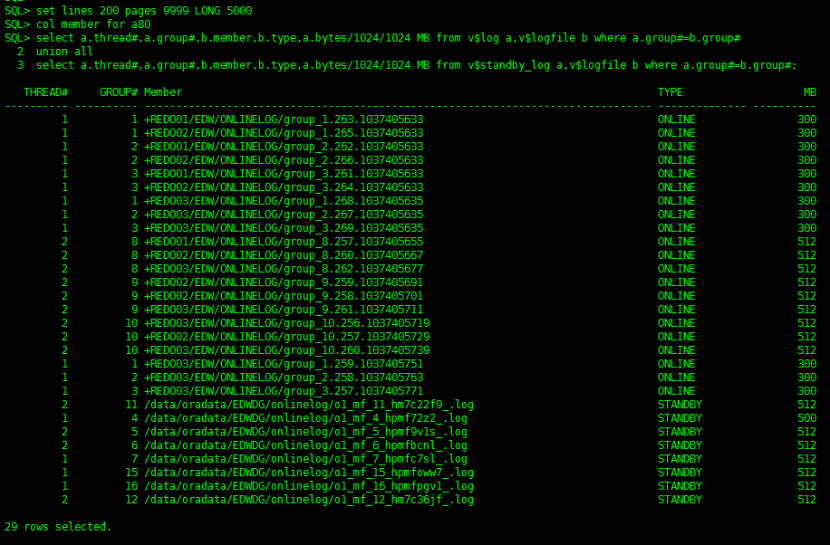
删除备库 standby 日志组
select GROUP#,THREAD#,BYTES/1024/1024 mb,status from v$standby_log;
alter database drop logfile group 16;
alter database drop logfile group 15;
alter database drop logfile group 12;
alter database drop logfile group 11;
alter database drop logfile group 7;
alter database drop logfile group 6;
alter database drop logfile group 5;
alter database drop logfile group 4;
新建备库 standby 日志组
alter database add standby logfile thread 1 group 15 ('/data/oradata/EDWDG/onlinelog/group_15.317.1091972705','/data/oradata/EDWDG/onlinelog/group_15.647.1091972705') size 1024M reuse;
alter database add standby logfile thread 1 group 16 ('/data/oradata/EDWDG/onlinelog/group_16.318.1091972717','/data/oradata/EDWDG/onlinelog/group_16.394.1091972717') size 1024M reuse;
alter database add standby logfile thread 1 group 14 ('/data/oradata/EDWDG/onlinelog/group_14.316.1091972697','/data/oradata/EDWDG/onlinelog/group_14.705.1091972697') size 1024M reuse;
alter database add standby logfile thread 1 group 13 ('/data/oradata/EDWDG/onlinelog/group_13.269.1102104843','/data/oradata/EDWDG/onlinelog/group_13.265.1102104845') size 1024M reuse;
alter database add standby logfile thread 1 group 17 ('/data/oradata/EDWDG/onlinelog/group_17.273.1102104889','/data/oradata/EDWDG/onlinelog/group_17.273.1102104893') size 1024M reuse;
alter database add standby logfile thread 1 group 18 ('/data/oradata/EDWDG/onlinelog/group_18.320.1091972803','/data/oradata/EDWDG/onlinelog/group_18.564.1091972803') size 1024M reuse;
alter database add standby logfile thread 1 group 19 ('/data/oradata/EDWDG/onlinelog/group_19.321.1091972811','/data/oradata/EDWDG/onlinelog/group_19.549.1091972811') size 1024M reuse;
alter database add standby logfile thread 1 group 20 ('/data/oradata/EDWDG/onlinelog/group_20.322.1091972819','/data/oradata/EDWDG/onlinelog/group_20.485.1091972819') size 1024M reuse;
查查日志组
select a.thread#,a.group#,b.member,b.type,a.bytes/1024/1024 MB from v$log a,v$logfile b where a.group#=b.group#
union all
select a.thread#,a.group#,b.member,b.type,a.bytes/1024/1024 MB from v$standby_log a,v$logfile b where a.group#=b.group#;
打开实时应用日志
alter database recover managed standby database using current logfile disconnect;
alter system set standby_file_management='AUTO';
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');

以上则完成了 redo 日志组的重建工作,重建 redo 不需要停止业务,对业务也是无感知的,可随时操作。全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号,来一起玩耍吧!!!
————————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

