云筑网技术团队
助推建筑行业数字化
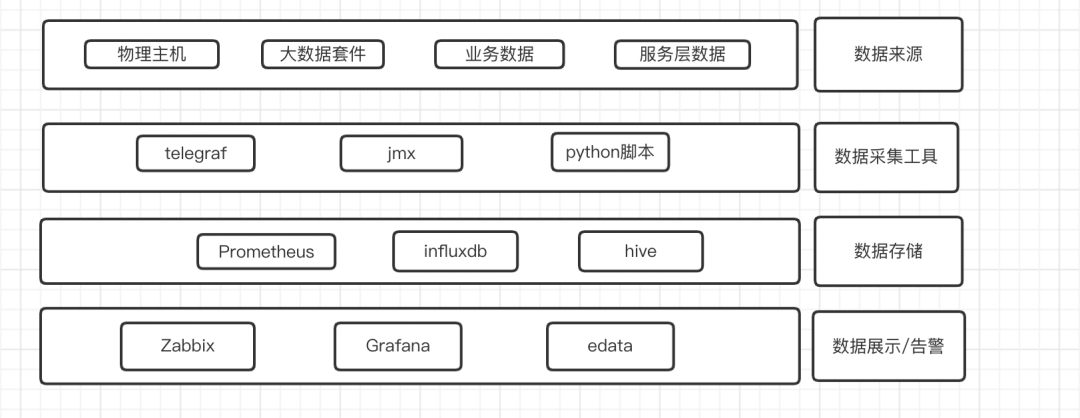
分层指标的梳理
数据采集
可视化展示
报警、预警
2 分层指标梳理
整个指标体系从下到上可以分为以下几层
底层物理主机层
大数据组件监控
业务服务监控
业务数据监控
2.1 底层物理主机层
2.2 大数据基础组件层
HDFS
Yarn
Zookeeper
Kafka
Clickhouse
Hive
Trino
2.3 业务服务层
2.4 业务数据层
3 数据采集
3.1 物理主机采集
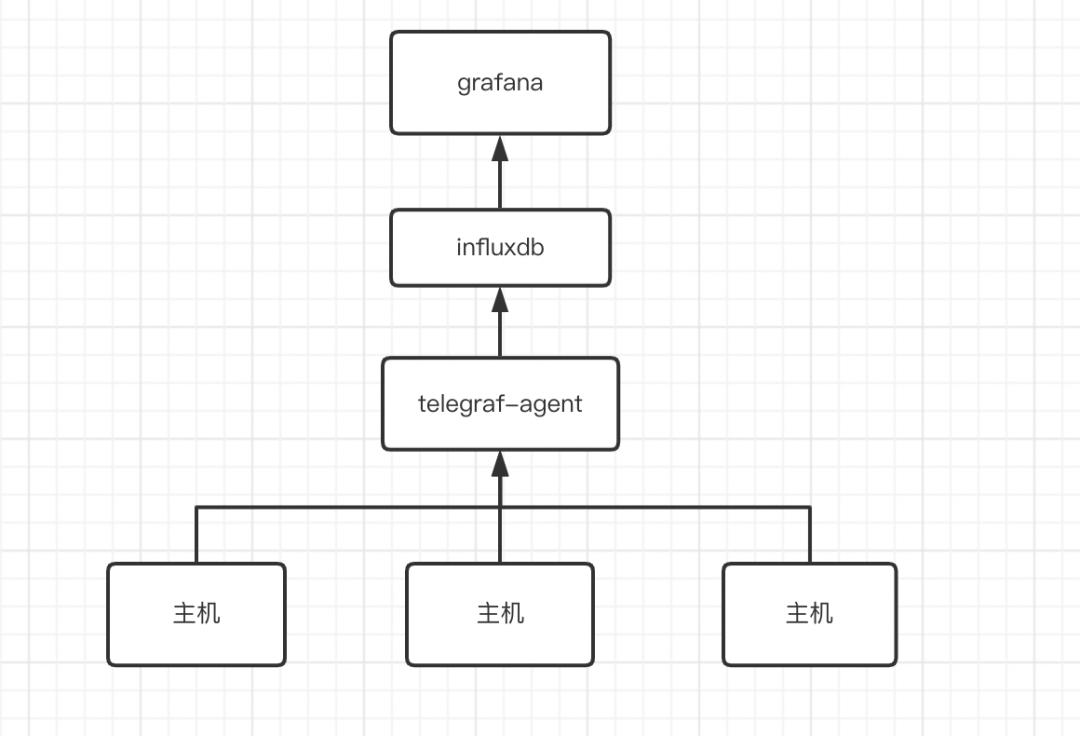
3.2 大数据套件的数据采集
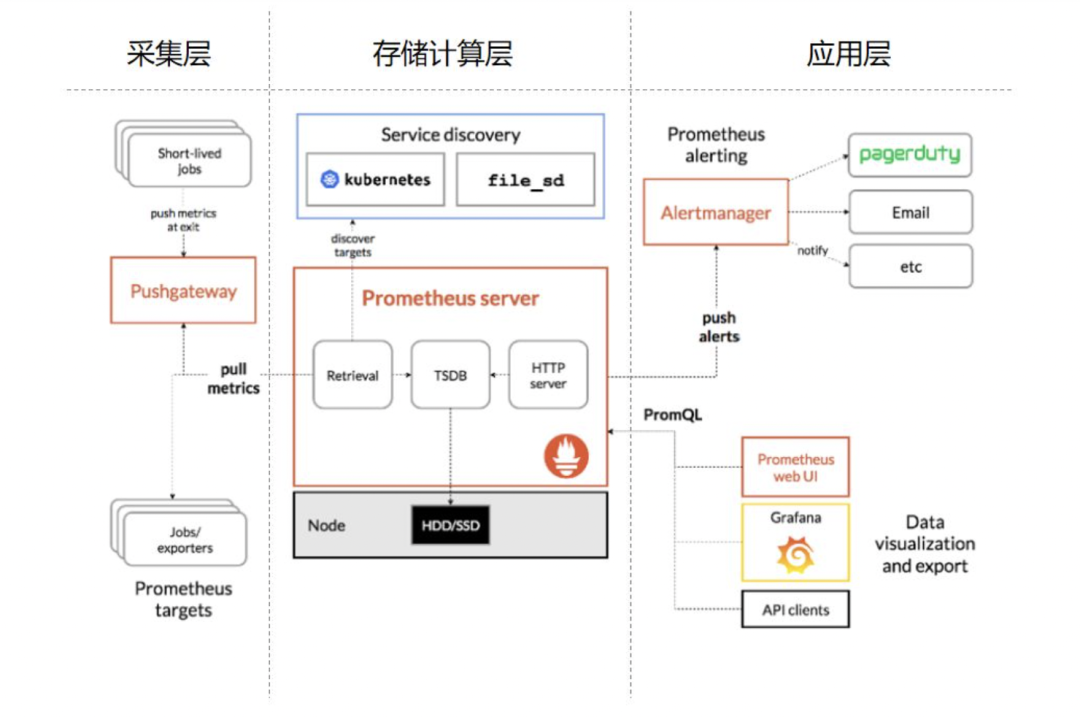
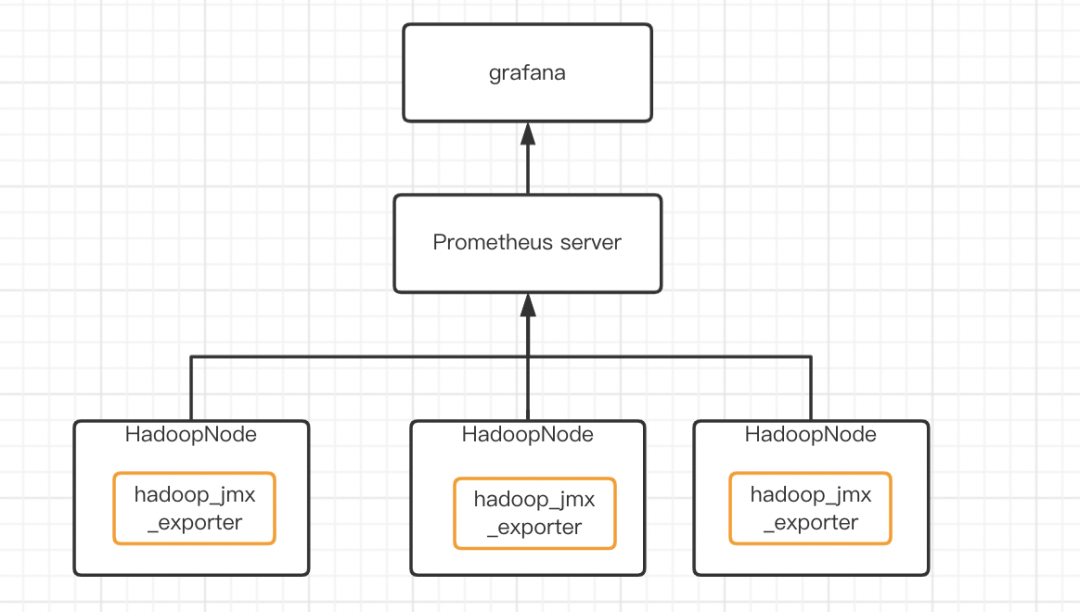
3.3 业务服务层数据采集
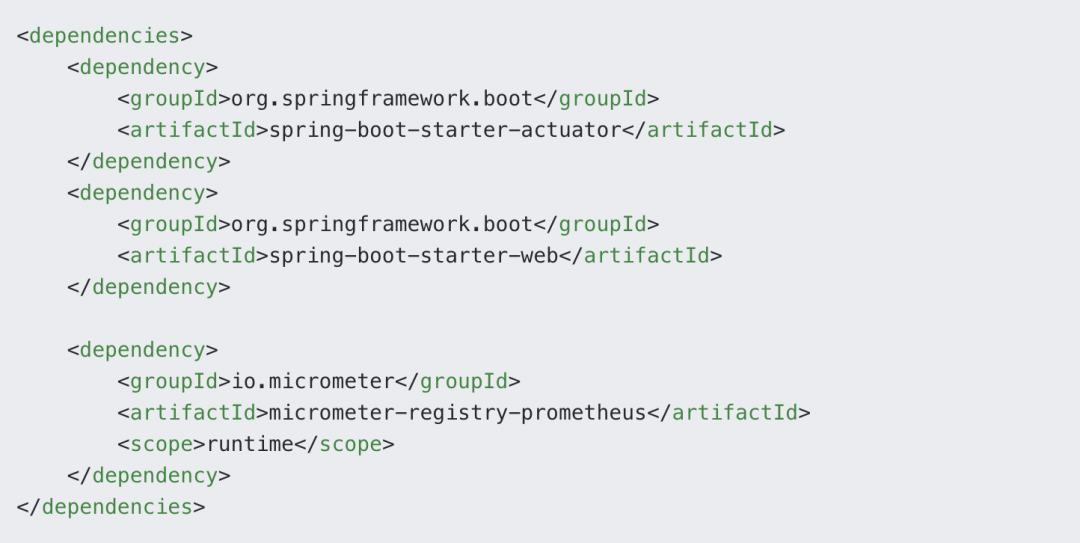
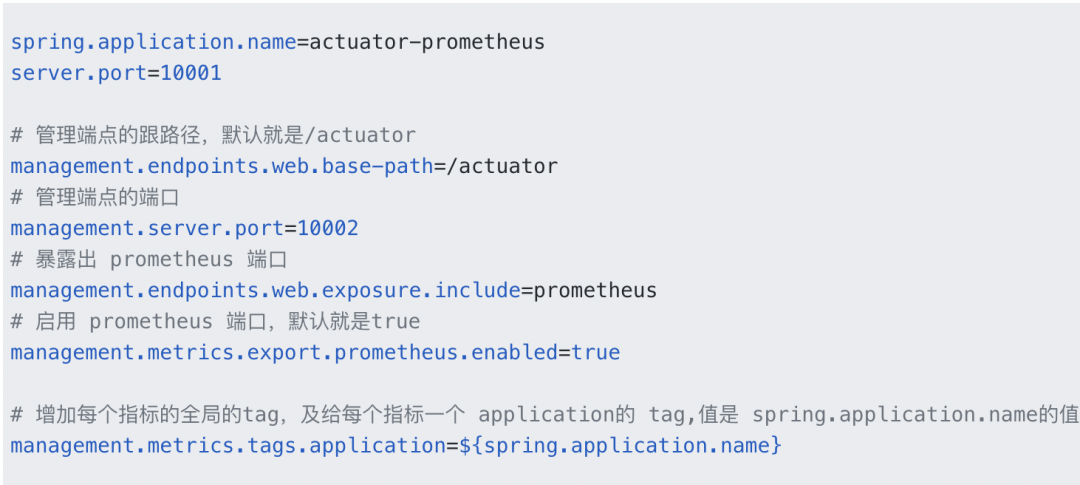
3.4 业务数据层的采集
对于hive中的业务数据,采用编写python脚本的方式从metastore底层的mysql元数据库中将数据同步到hive中,进行数据聚合加工。防止在mysql中进行聚合影响,metastore服务的稳定行.hive metastore中mysql 库元数据如下
对于clickhouse的元数据采集, clickhouse将数据存储信息元数据存放在system库里面。直接clickhouse的需要的数据同步到hive的数据仓库里面。clickhouse系统表详情参见官网介绍(https://clickhouse.com/docs/en/operations/system-tables)。

ES业务数据采集
4 监控数据可视化
所有组件层面Metrics数据收集之后, 需要有一个地方集中监控维度的看板,在研究行业的通用的技术方案中,grafana是一个比较理想的选择。grafana本身自带了丰富的图表功能,能够连接不同的数据源。比如prometheus、es等。QA环境效果图如下
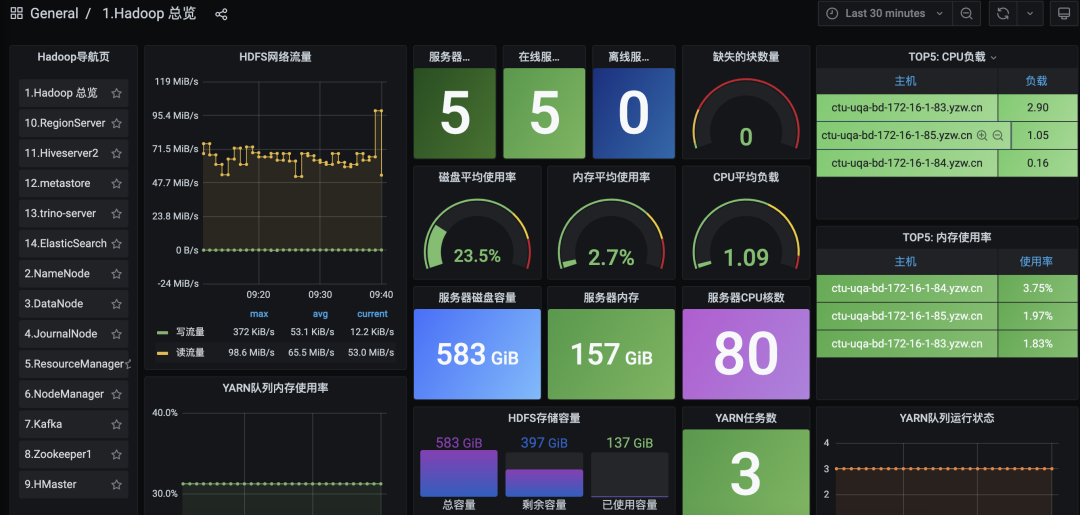
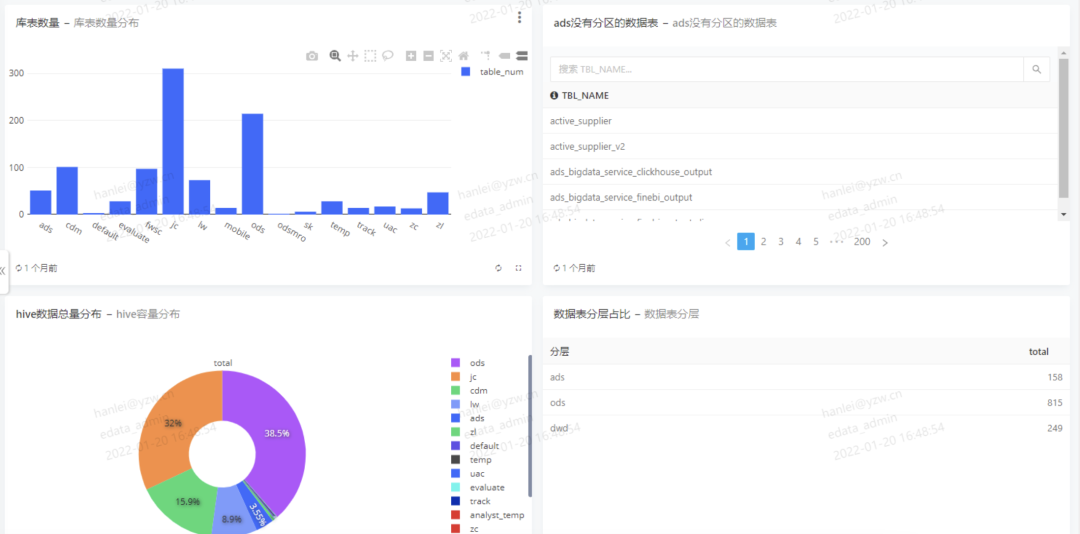
对于业务层面数据,我们收集在hive中之后,采用公司自研的edata自主报表平台,展示业务数据层面的数据,形成固定通用的业务数据周报,发给上层的领导。局部效果如下
5 监控告警
5.1 告警等级划分
5.2 告警收敛
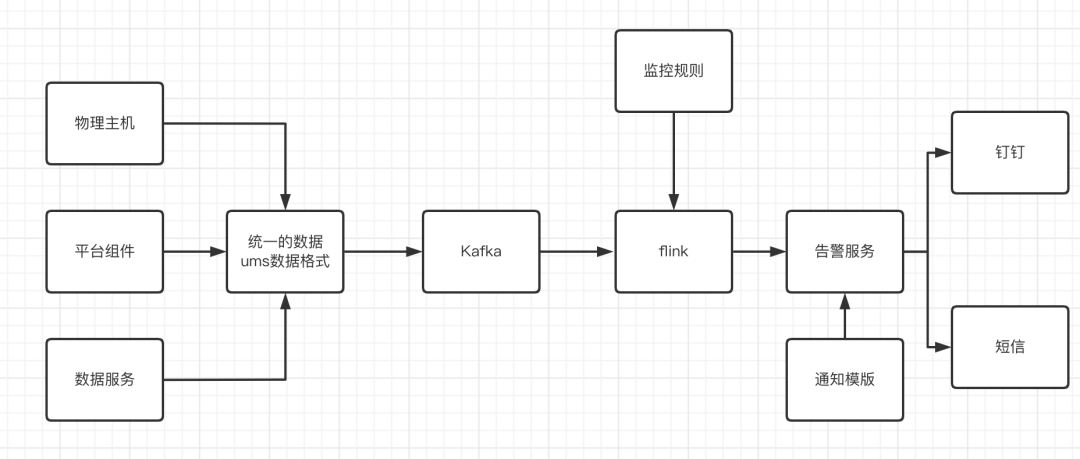
5.3 告警实现
第一块是主机层面的告警,采用的是zabbix自带的告警功能,通过配置相应的trigger进行告警处理
第二块为prometheus监控大数据组件和大数据对服务,利用prometheus的alter manager的功能实现报警
第三块为业务数据层监控告警,由开发人员执行编写python脚本进行数据对比达到报警的目的