





云筑网技术团队
助推建筑行业数字化
图数据结构,能够很自然地表征现实世界。比如采购商、供应商、采购合同这些实体可以用图中的点来表示,采购商对商品的采购行为、供应商对合同的履约行为都可以用图中的边来表示。使用图的方式对场景建模,便于描述复杂关系。在云筑中的应用主要包括以下 4 个方面:
图谱挖掘:根据业务领域划分云筑网可以分为商品知识图谱、供应商知识图谱、工程项目知识图谱等多种领域专用知识图谱。
安全风控: 业务部门有金融风控的需求、内容风控需求的场景
数据治理:数据血缘管理、一致性数据链路追踪等场景
搜索/推荐服务:个性化推荐、意图识别等场景
2 图数据库选型
在图数据库的选型上我们主要考虑了以下 5 点:
(A) 项目开源,暂不考虑需付费的图数据库;
(B) 分布式架构设计,具备良好的可扩展性;
(C) 毫秒级的多跳查询延迟;
(D) 支持千亿量级点边存储;
(E) 具备批量从数仓导入数据的能力。
基于以上考虑将剩余的图数据库分为三类:
第一类:Neo4j、ArangoDB、Virtuoso、TigerGraph、RedisGraph。此类图数据库只有单机版本开源可用,性能优秀,但不能应对分布式场景中数据的规模增长。
第二类:JanusGraph、HugeGraph。此类图数据库在现有存储系统之上新增了通用的图语义解释层,图语义层提供了图遍历的能力,但是受到存储层或者架构限制,不支持完整的计算下推,多跳遍历的性能较差,很难满足 OLTP 场景下对低延时的要求。
第三类:DGraph、NebulaGraph。此类图数据库根据图数据的特点对数据存储模型、点边分布、执行引擎进行了全新设计,对图的多跳遍历进行了深度优化,基本满足我们的选型要求。
DGraph 是由前 Google 员工 Manish Rai Jain 离职创业后,在 2016 年推出的图数据库产品,底层数据模型是 RDF,基于 Go 语言编写,存储引擎基于 BadgerDB改造,使用 RAFT 保证数据读写的强一致性。
NebulaGraph 是由前 Facebook 员工叶小萌离职创业后,在 2019年 推出的图数据库产品,底层数据模型是属性图,基于 C++ 语言编写,存储引擎基于 RocksDB改造,使用 RAFT 保证数据读写的强一致性。
这两个项目的创始人都在互联网公司图数据库领域深耕多年,对图数据库的落地痛点有深刻认识,整体的架构设计也有较多相似之处。在图数据库最终的选型上,我们基于 LDBC-SNB 数据集对 NebulaGraph、DGraph、HugeGraph 进行了性能测评,从测试结果看 NebulaGraph 在数据导入、实时写入及多跳查询方面性能均优于竞品。此外,NebulaGraph 社区活跃,问题响应速度快,所以最终我们选择基于 NebulaGraph 来搭建知识图谱平台。
3 NebulaGraph架构
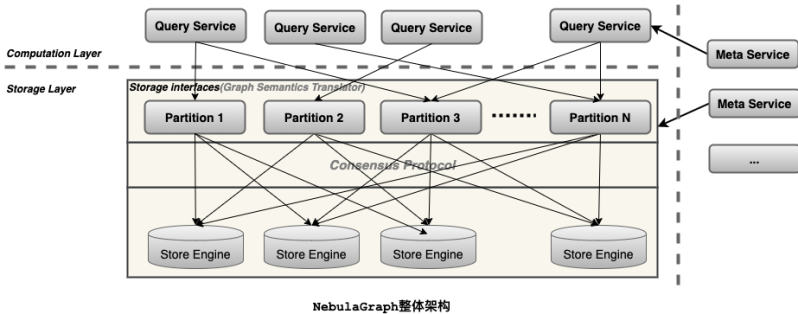
一个完整的 NebulaGraph 集群包含三类服务,即 Query Service、Storage Service 和 Meta Service。每类服务都有其各自的可执行二进制文件,既可以部署在同一节点上,也可以部署在不同的节点上。下面是NebulaGraph 架构设计的几个核心点。
Meta Service:架构图中右侧为 Meta Service 集群,它采用 Leader/Follower 架构。Leader 由集群中所有的 Meta Service 节点选出,然后对外提供服务;Followers 处于待命状态,并从 Leader 复制更新的数据。一旦 Leader 节点 Down 掉,会再选举其中一个 Follower 成为新的 Leader。Meta Service 不仅负责存储和提供图数据的 Meta 信息,如 Schema、数据分片信息等;同时还提供 Job Manager 机制管理长耗时任务,负责指挥数据迁移、Leader 变更、数据 compaction、索引重建等运维操作。
存储计算分离:在架构图中 Meta Service 的左侧,为 NebulaGraph 的主要服务,NebulaGraph 采用存储与计算分离的架构,虚线以上为计算,以下为存储。存储计算分离有诸多优势,最直接的优势就是,计算层和存储层可以根据各自的情况弹性扩容、缩容。存储计算分离还带来了另一个优势:使水平扩展成为可能。此外,存储计算分离使得 Storage Service 可以为多种类型的计算层或者计算引擎提供服务。当前 Query Service 是一个高优先级的 OLTP 计算层,而各种 OLAP 迭代计算框架会是另外一个计算层。
无状态计算层:每个计算节点都运行着一个无状态的查询计算引擎,而节点彼此间无任何通信关系。计算节点仅从 Meta Service 读取 Meta 信息以及和 Storage Service 进行交互。这样设计使得计算层集群更容易使用 K8s 管理或部署在云上。每个查询计算引擎都能接收客户端的请求,解析查询语句,生成抽象语法树(AST)并将 AST 传递给执行计划器和优化器,最后再交由执行器执行。
Shared-nothing 分布式存储层:Storage Service 采用 Shared-nothing 的分布式架构设计,共有三层,最底层是 Store Engine,它是一个单机版 Local Store Engine,提供了对本地数据的get/put/scan/delete 操作,该层定义了数据操作接口,用户可以根据自己的需求定制开发相关 Local Store Plugin。目前,NebulaGraph 提供了基于 RocksDB 实现的 Store Engine。在 Local Store Engine 之上是 Consensus 层,实现了 Multi Group Raft,每一个 Partition 都对应了一组 Raft Group。在 Consensus 层上面是 Storage interfaces,这一层定义了一系列和图相关的 API。这些 API 请求会在这一层被翻译成一组针对相应 Partition 的 KV 操作。正是这一层的存在,使得存储服务变成了真正的图存储。否则,Storage Service 只是一个 KV 存储罢了。而 NebulaGraph 没把 KV 作为一个服务单独提出,最主要的原因便是图查询过程中会涉及到大量计算,这些计算往往需要使用图的 Schema,而 KV 层没有数据 Schema 概念,这样设计比较容易实现计算下推,是 NebulaGraph 查询性能优越的主要原因。
4 知识图谱平台架构
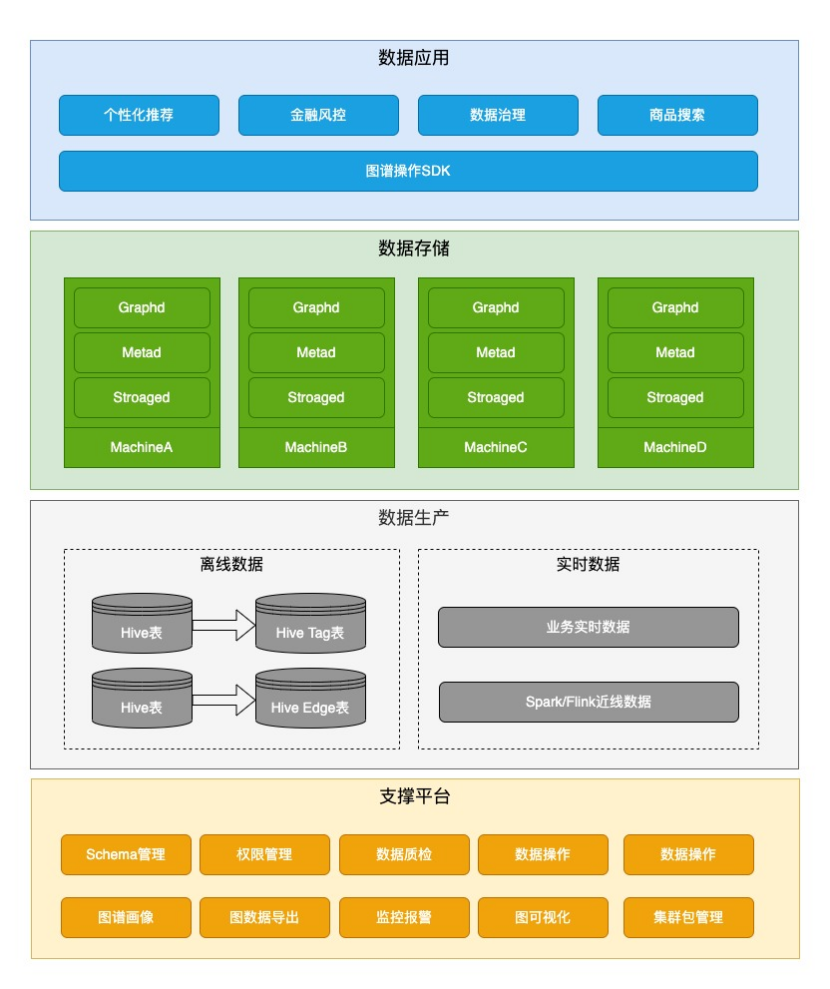
该平台包含以下 4 层:
数据应用层:业务方可以在业务服务中引入图谱 SDK,实时地对图数据进行增删改查。
数据存储层:集群部署,集群中机器数量大于等于副本的数量,副本数量大于等于 3 。只要集群中有大于副本数一半的机器存活,整个集群就可以对外正常提供服务。
数据生产层:图数据主要有两种来源,第一种是业务方把数仓中数据通过 ETL Job 转成点和边的 Hive 表,然后离线导入到图数据库中;第二种是业务线上实时产生的数据、或者通过 Spark/Flink 等流式处理产生的近线数据,调用在线批量写接口实时灌到图数据库中。
支撑平台:提供了 Schema 管理、权限管理、数据质检、数据增删改查、集群扩缩容、图谱画像、图数据导出、监控报警、图可视化、集群包管理等功能。
5 总结与展望
知识图谱平台将具备对图数据的一站式自助管理功能。如果某个业务方要使用这种图数据库能力,那么业务方可以在平台上自助地创建图的 Schema、导入图数据、配置导入数据的执行计划、引入平台提供的 SDK 对数据进行操作等等。
未来与业务侧的结合,预计主要是通过研发基于知识图谱的搜索引擎、推荐引擎、店铺客服自动问答系统和数据治理。搜索引擎计划服务目前云筑网总共超过XX万供应商和目前云筑网全量材料库超过XXX万上建材商品。推荐引擎全面覆盖云筑网目前所有的招投标信息、询价信息、推荐供应商、云筑优选猜你喜欢等产品,并计划把平台运营内容(例如云筑学苑,云筑蜂会)和行业资讯,结合整合供应商App,打造一款面向建筑供应链领域的信息流产品;此外推荐引擎也会应用到“建材市场”的精准推广系统里面,打造一个以精准匹配供需双方建材采购需求为特色的建筑交易平台。店铺客服自动问答系统,将会覆盖全量的在线店铺,提高供需撮合的效率。预计到2023年将有效支持云筑网各种营收预计共计XX元。

