




PostgreSQL复制(同步和异步复制)是最广泛使用的特性之一。可以应用复制实现高可用集群或创建只读副本,以分散工作负载。这里需要注意的是,如果您正在使用复制,则必须确保正确地监视集群。
这篇文章的目的是解释一些基本原理,以确保您的PostgreSQL集群保持健康。
pg_stat_replication:检查当前状态
监视复制的最佳方法是使用pg_stat_replication
视图,它包含许多重要信息。下面是该视图的样子:
test=# \d pg_stat_replicationView "pg_catalog.pg_stat_replication"Column | Type | Collation | Nullable | Default-----------------+-------------------------+-----------+----------+---------pid | integer | | |usesysid | oid | | |usename | name | | |application_name | text | | |client_addr | inet | | |client_hostname | text | | |client_port | integer | | |backend_start | timestamp with time zone| | |backend_xmin | xid | | |state | text | | |sent_lsn | pg_lsn | | |write_lsn | pg_lsn | | |flush_lsn | pg_lsn | | |replay_lsn | pg_lsn | | |write_lag | interval | | |flush_lag | interval | | |replay_lag | interval | | |sync_priority | integer | | |sync_state | text | | |reply_time | timestamp with time zone| | |
这个视图中的字段数量多年来大幅增长。不过,让我们先讨论一些基本问题。
pg_stat_replication:wal_sender进程信息
人们经常说pg_stat_replication
只在主库上有显示。这并不完全正确。视图所做的就是公开关于wal_sender
进程的信息。换句话说:如果您正在运行级联复制,这意味着一个从库也可能显示条目,以防它复制到更多的从库。下面的图片说明了这种情况:
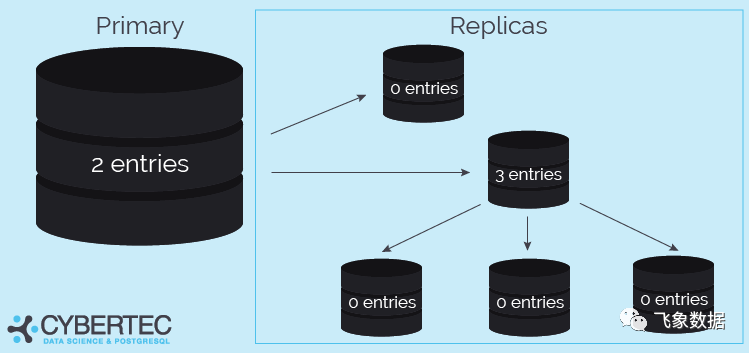
对于每个wal_sender
进程,你将得到一个条目。重要的是,每个库只会看到链中的下一个库——发送库永远不会“穿过”一个从库。换句话说:在级联复制的情况下,您必须要求每个发送库获得概述。
通常人们需要确定一个从库是否是最新的。这些字段做了说明:
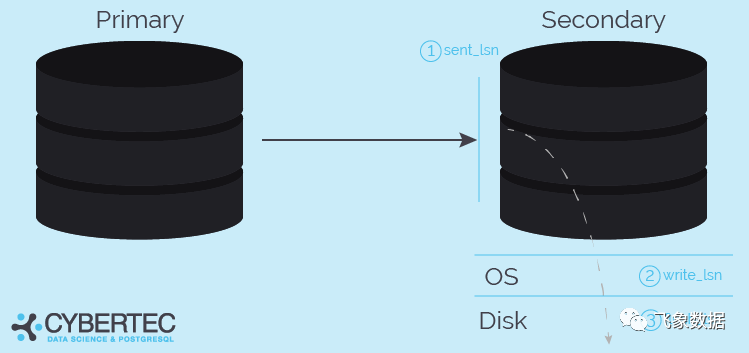
sent_lsn:已经通过网络发送了多少WAL ?
write_lsn:有多少WAL已经发送到操作系统了?(没有刷新)
flush_lsn:有多少 WAL 已经刷新到磁盘?
replay_lsn:重放了多少 WAL,因此对查询可见?
下图展示了这些字段的意义:
这里需要注意的是,PG提供了一种特殊的数据类型来表示这些数据:pg_lsn
我们可以很容易地计算出WAL当前的位置:
test=# SELECT pg_current_wal_lsn();pg_current_wal_lsn--------------------3/DA06D240(1 row)
这里值得注意的是,我们可以很容易计算出一个副本落后了多少:
test=# SELECT pg_current_wal_lsn() - '3/B549A845'::pg_lsn;?column?-----------616376827(1 row)
PostgreSQL提供了各种操作符来进行这样的计算。
flush_lsn与replay_lsn
人们总是问我们flush_lsn
和replay_lsn
之间的区别是什么。让我们深入了解一下:当WAL从主库流向从库时,它首先通过网络发送,然后发送到操作系统,最后事务被刷新到磁盘以确保持久性(=崩溃安全)。flush_lsn
显然表示刷新到磁盘的最后一个WAL位置。现在的问题是:数据在刷新后是否可见?答案是:不,可能存在复制冲突。在复制冲突的情况下,WAL会持久化到副本上——但只有当冲突解决时才会重放它。换句话说,可能会发生数据存储在还没有重放的从库上,因此终端用户可以访问该从库。
注意这一点很重要,因为复制冲突发生的频率可能比您想象的要高。如果您看到如下消息,则说明您遇到了复制冲突:
ERROR: canceling statement due to conflict with recoveryDETAIL: User query might have needed to see row versions that must be removed.
复制滞后
有时需要确定复制延迟的数量(以秒为单位)。到目前为止,我们已经看到了以字节为单位的两个服务器之间的距离。如果您想测量延迟,可以查看*_lag
字段。这些列的数据类型是interval
,因此可以看到以秒甚至分钟为单位的延迟。如果复制正常工作,延迟通常非常非常小(毫秒)。但是,您可能需要监控它。
注意:如果您正在运行大规模导入(如VACUUM
)或其他一些昂贵的操作,很容易出现磁盘吞吐量高于网络带宽的情况。在这种情况下,从库很可能会落后。你必须容忍这一点,并确保提醒不会太早生效。
