





环境
- 源端数据库执行 update 更新一条记录
test_dml=# select * from test.to_date2;
id | col1 | col2 | col3
----+----------------------------+----------------------------+----------------------------
1 | 2022-04-29 23:44:34.372525 | 2022-04-29 23:44:34.372525 | 2022-04-29 23:44:34.372525
2 | 2022-04-30 09:21:31.51693 | 2022-04-30 09:21:31.51693 | 2022-04-30 09:21:31.51693
3 | 2022-04-30 09:23:48.090589 | 2022-04-30 09:23:48.090589 | 2022-04-30 09:23:48.090589
4 | 2022-04-30 09:29:27.644005 | 2022-04-30 09:29:27.644005 | 2022-04-30 09:29:27.644005
(4 rows)
test_dml=# update test.to_date2 set col1=now() where id =1;
UPDATE 1
test_dml=# select * from test.to_date2;
id | col1 | col2 | col3
----+----------------------------+----------------------------+----------------------------
2 | 2022-04-30 09:21:31.51693 | 2022-04-30 09:21:31.51693 | 2022-04-30 09:21:31.51693
3 | 2022-04-30 09:23:48.090589 | 2022-04-30 09:23:48.090589 | 2022-04-30 09:23:48.090589
4 | 2022-04-30 09:29:27.644005 | 2022-04-30 09:29:27.644005 | 2022-04-30 09:29:27.644005
1 | 2022-04-30 11:24:21.227334 | 2022-04-29 23:44:34.372525 | 2022-04-29 23:44:34.372525
(4 rows)
- 目标端连接器参数配置
[root@docker tutorial]# cat oracle-datatype-sink.json
{
"name": "oracle-datatype-sink10",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url": "jdbc:oracle:thin:@//172.17.0.2:1521/pdbtt",
"connection.user": "test",
"connection.password": "test",
"tasks.max": "1",
"topics": "datatype.test.to_date2",
"table.name.format": "TO_DATE3",
"quote.sql.identifiers": "never",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false"
}
}
问题一:源端和目标端进行数据同步的表都是以 id 列为主键,为什么源端执行 UPDATE 操作,目标端会报 ORA-00001 违反唯一约束呢?
- 查看目标端连接器的报错信息,可以看到 “Sql = INSERT INTO TO_DATE3”,明明是一个 UPDATE 操作,为什么变成 INSERT 语句?
tutorial-connect-1 | Caused by: java.sql.SQLException: Exception chain: tutorial-connect-1 | java.sql.BatchUpdateException: ORA-00001: unique constraint (TEST.SYS_C007770) violated tutorial-connect-1 | tutorial-connect-1 | java.sql.SQLIntegrityConstraintViolationException: ORA-00001: unique constraint (TEST.SYS_C007770) violated tutorial-connect-1 | tutorial-connect-1 | Error : 1, Position : 0, Sql = INSERT INTO TO_DATE3(id,col1,col2,col3) VALUES(:1 ,:2 ,:3 ,:4 ), OriginalSql = INSERT INTO TO_DATE3(id,col1,col2,col3) VALUES(?,?,?,?), Error Msg = ORA-00001: unique constraint (TEST.SYS_C007770) violated
- 查看这条 UPDATE 记录在 Kafka 中的消息记录
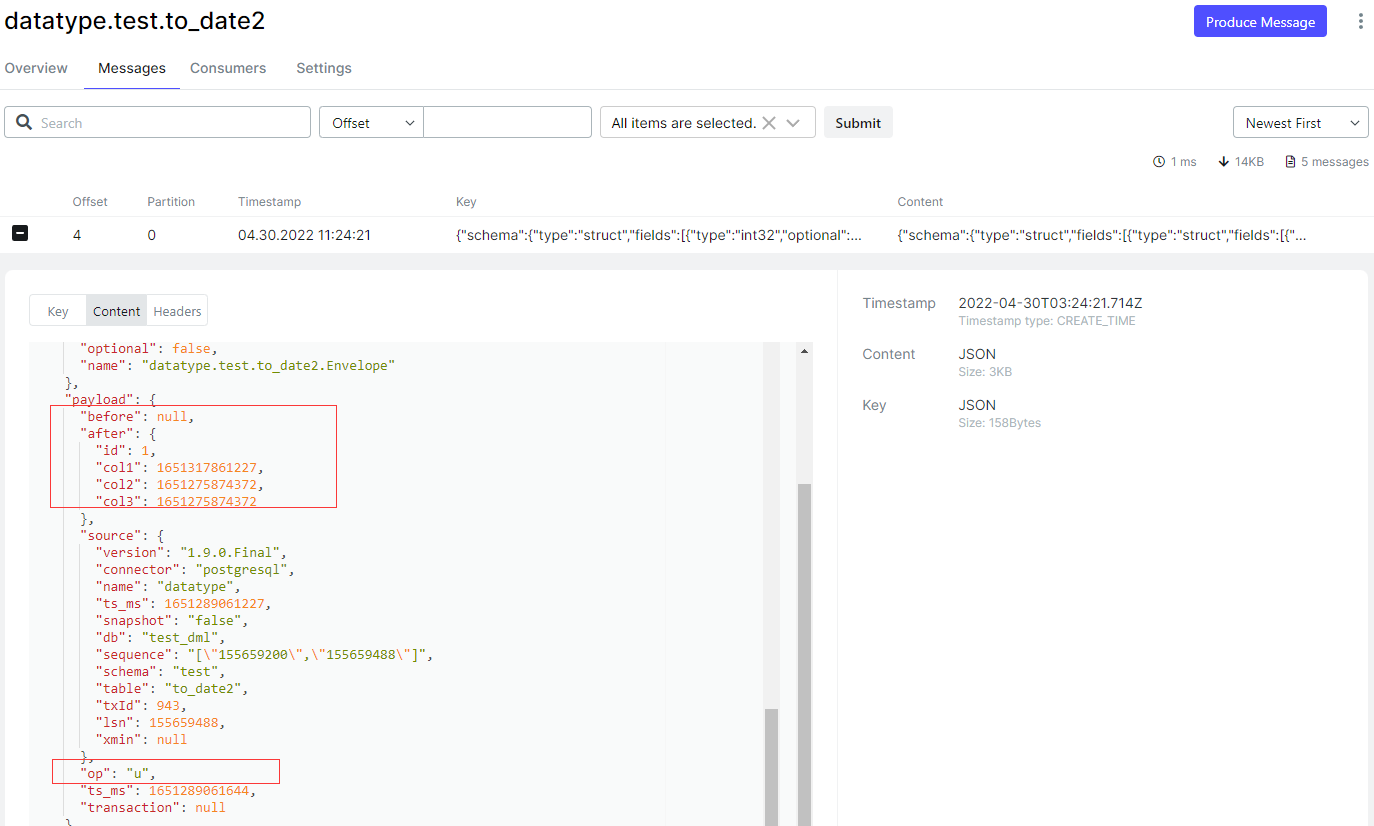
- 这里有两点,第一点是这条 UPDATE 记录在 Kafka 中的消息中没有记录旧值(before 为 NULL),但是这一点对数据同步没啥关系。第二点是 “op”: “u”,告知目标端连接器此条消息是个 update 事件,然而 update 事件和 insert 事件都会对数据库执行写入操作,这样就引出了目标端连接器的另一个参数 insert.mode,控制写入模式。
- insert.mode 参数有3个值 [insert, upsert, update],默认值是 insert,表示写入数据使用标准的 INSERT SQL,所以目标端连接器将那条 UPDATE 使用 INSERT INTO TO_DATE3(id,col1,col2,col3) VALUES (1,1651317861227,1651275874372,1651275874372),而源库中存在 id=1 的记录,就会报出 ORA-00001 违反唯一约束。
问题二:为什么要控制写入模式,设定 insert.mode 参数?
- 这个问题又会引出另一个概念,Idempotent writes (幂等写入),而设定 insert.mode 参数就是为了控制幂等写入。
- 幂等写入,是说一个写入操作,可以重复执行很多次,但只导致一次写入更改,也就是说,后面再重复执行的写入就不起作用了。
- 哪些场景会发生幂等写入?例如:1. Kafka 中因某些原因一条消息存储了多次,在目标端消费的时候,这条消息就会被重复写入。2. Kafka 的一条消息在目标端消费完成后,由于某些故障原因导致 Kafka 没有记录这条消息被消费后的偏移量,就会导致这条消息会被重复消费写入。
- 如何知道某条消息是否为重复写入的消息?目标端连接器使用 “pk.mode” 参数来判断是否为重复写入的消息,“pk.mode” 和 “pk.fields” 参数指定哪个或哪些字段为主键字段,因为主键字段具有唯一性,所以不会产生重复写入的消息,实现了幂等性。
- insert.mode:默认是 insert,Valid Values: [insert, upsert, update]
- insert:使用标准SQL INSERT 写入数据,如果该行已存在于表中,则会发生错误。
- upsert:在违反主键约束的情况下原子地添加新行或更新现有行,使用 upsert 模式时,必须在连接器配置中添加和定义 pk.mode 和 pk.fields 属性,例如:“pk.mode”: “record_value”, “pk.fields”: “id”,如果该行已经存在,UPSERT 函数将使用提供的新值覆盖列值。
- update:使用标准SQL UPDATE 写入数据。
- 由于 upsert 没有标准语法,下表描述了使用的特定于数据库的 DML (dialect) 。
| Database | Upsert style |
|---|---|
| MySQL | INSERT … ON DUPLICATE KEY UPDATE … |
| Oracle | MERGE … |
| PostgreSQL | INSERT … ON CONFLICT … DO UPDATE SET … |
| SQLite | INSERT OR REPLACE … |
| SQL Server | MERGE … |
| Sybase | MERGE … |
- 强烈建议使用 upsert 模式,因为如果需要重新处理记录,它有助于避免违反约束或重复数据。
- 关于幂等写入找到以下两个文章,感觉说的比较好理解
https://www.lydtechconsulting.com/blog-kafka-idempotent-consumer.html
https://william-yeh.net/post/2020/03/idempotency-key-test/
问题三:这种情况如何解决呢?
- 很明显,目标端连接器修改 “insert.mode”: “upsert”
tutorial-connect-1 | org.apache.kafka.connect.errors.ConnectException:
Write to table '"TO_DATE3"' in UPSERT mode requires key field names to be known, check the primary key configuration
-
“insert.mode”: “upsert” 需要配合 “pk.mode” 和 “pk.fields” 参数告诉连接器使用那个列作为主键。
-
“pk.mode”:[none,kafka,record_key,record_value],默认是 none。
- none:不使用任何主键
- kafka: Apache Kafka 坐标用作主键,不建议使用。
- record_key:同步的表上存在主键,建议使用这个选项值,会使用表上的主键。
- record_value:同步的表上不存在主键的时候使用这个选项值,配合 “pk.fields” 参数选择使用表中的哪个或哪些字段作为主键。
-
当前同步的表上有主键,所以只需要在目标端连接器修改 “insert.mode”: “upsert” 和 “pk.mode”: “record_key”。
SQL> select * from test.to_date3;
ID COL1 COL2 COL3
---------- ------------------- ------------------------------ ---------------------------------------------------------------------------
1 2022-04-30 11:24:21 29-APR-22 11.44.34.372000 PM 29-APR-22 11.44.34.372000 PM
2 2022-04-30 09:21:31 30-APR-22 09.21.31.516000 AM 30-APR-22 09.21.31.516000 AM
3 2022-04-30 09:23:48 30-APR-22 09.23.48.090000 AM 30-APR-22 09.23.48.090000 AM
4 2022-04-30 09:29:27 30-APR-22 09.29.27.644000 AM 30-APR-22 09.29.27.644000 AM
- 这样目标端连接器会根据主键进行 UPDATE,数据同步过来了。
问题四:为什么这条 UPDATE 没有记录旧值呢?
参考文章:Debezium对源库DML操作的同步测试 ,搜索关键字:REPLICA IDENTITY
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
