




前文
目标是在我的小弱鸡的1-1-1架构(租户总资源是3C12G)上得出sysbench极限性能测试探索,前面已经实验验证表的物理建模和haproxy加速,下面提升思路是拿OB大神的独门配方优化参数和官方优化参数。
调优参数
ob大神的调味料如下,主要是OB的参数的变化,这里描述为计算层的优化
alter system set net_thread_count=4;
alter system set cpu_quota_concurrency=8;
alter system set use_large_pages="true";
alter system set enable_sql_audit=false;
alter system set enable_perf_event=false;
alter system set _clog_aggregation_buffer_amount=4 tenant=all;
alter system set _flush_clog_aggregation_buffer_timeout='1ms';
alter proxyconfig set enable_compression_protocol=false;
sysctl kernel.sched_migration_cost_ns=0;
经过反复调试,本人在这里的两个配置如下,但是设置数值再大始终没有把CPU打满
alter system set net_thread_count=32;
alter system set cpu_quota_concurrency=16;
测试思路
基于ob大神的的调味料混合haproxy和表结构启用bloom_filter、blocksize做四组测试。
- ob大神调味料+原表结构+obproxy【主要目标是优化OB参数看性能提升了多少】
- ob大神调味料+原表结构+haproxy【主要目标是优化OB参数结合接入层的obproxy看提升了多少】
- ob大神调味料+原表blom filter以及blocksize+obproxy【主要目标是优化OB参数结合存储层的设置变动看提升了多少】
- ob大神调味料+原表blom filter以及blocksize+haproxy【主要目标是优化OB参数结合存储层的设置变动再加上接入层的 haproxy看提升了多少】
测试过程
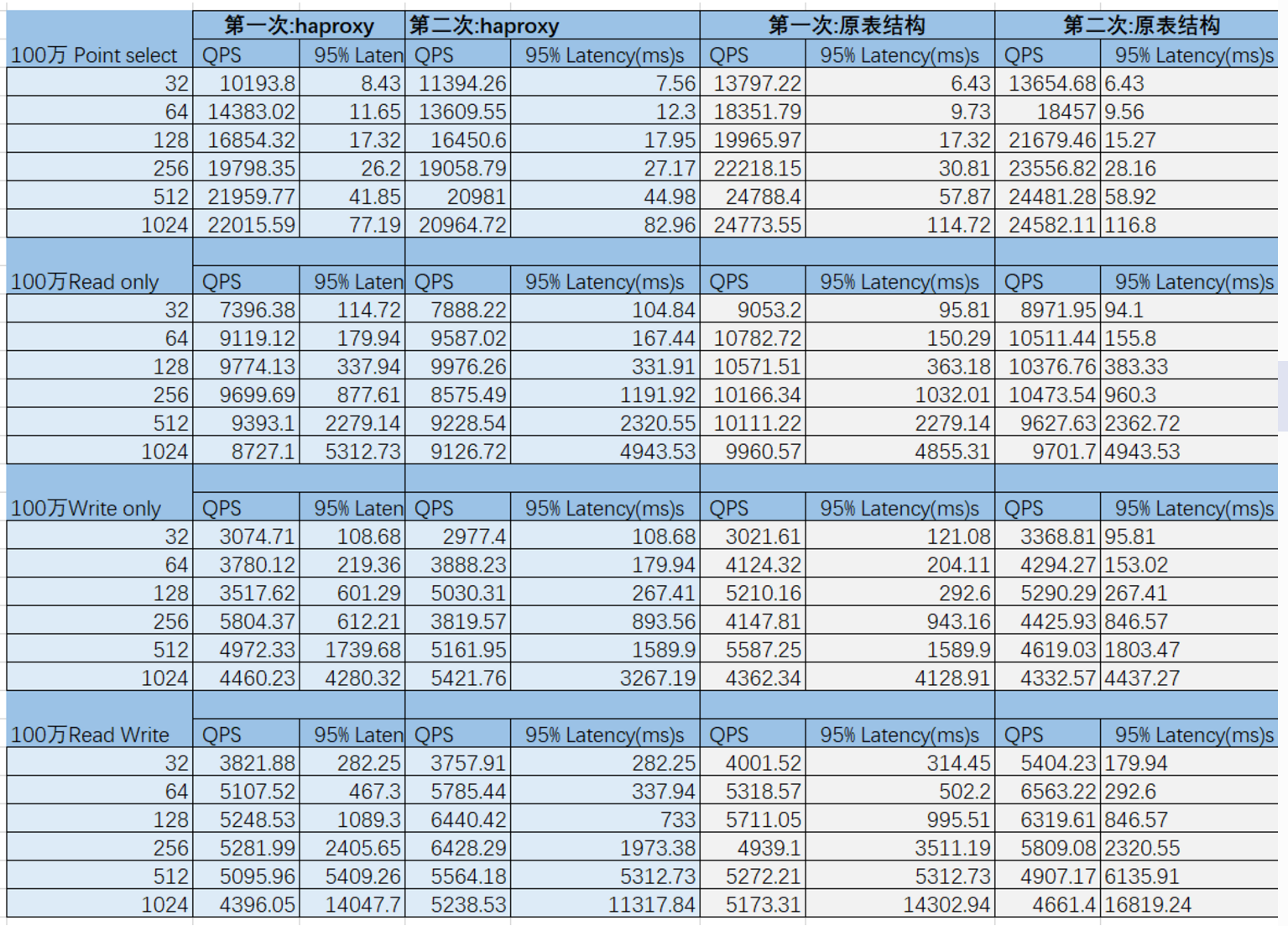
同样100万的数据,基于原表结构,obproxy或者haproxy分别执行两次
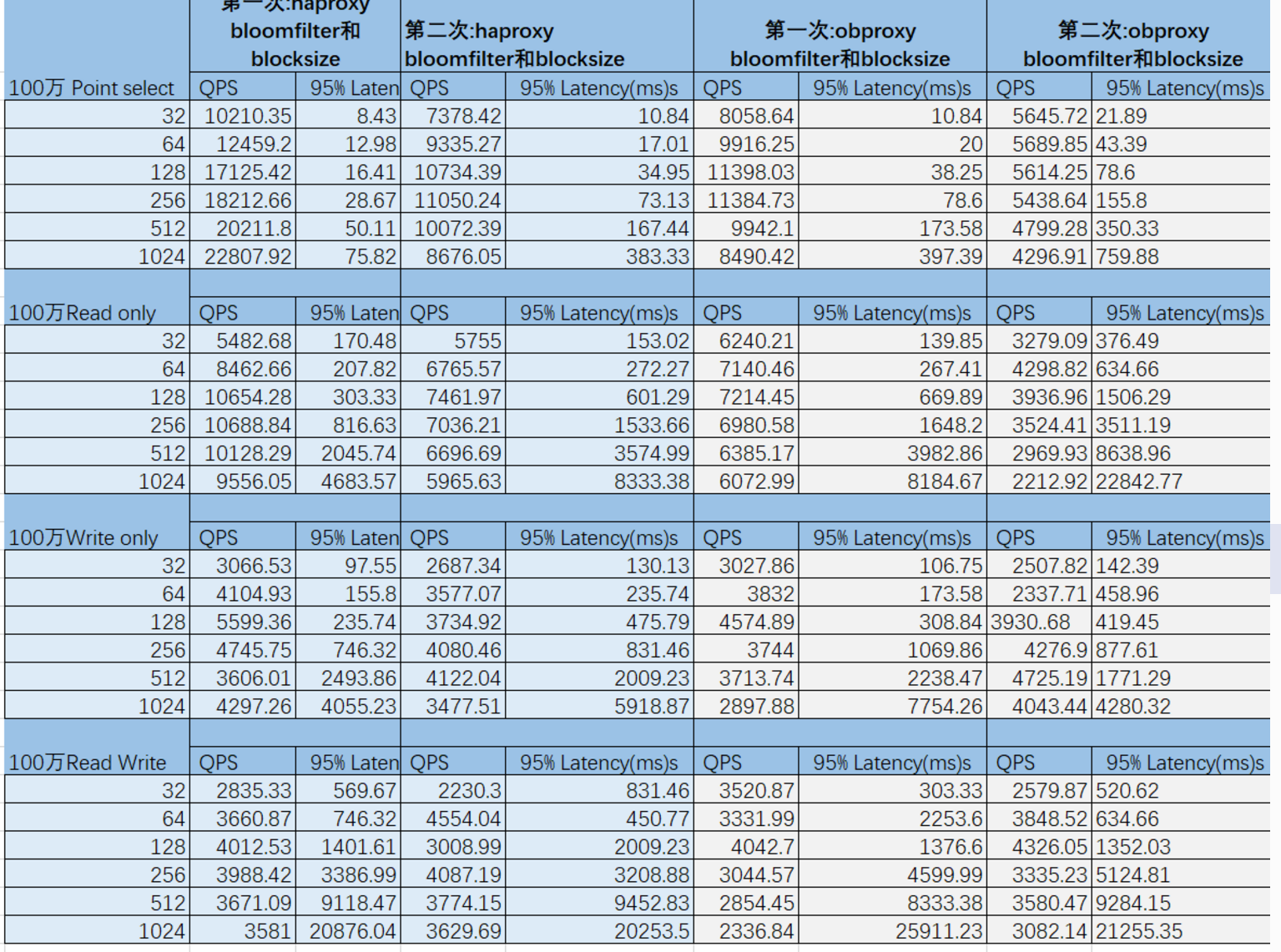
同样100万的数据,设置use_bloom_filter等于true,提高blocksize,基于obproxy或者基于haproxy分别执行两次
数据解读
- 测试性能有质的飞跃,主要动力加速来源于OB大神的调味料,相对之前大幅度的提升,笔者前面说过OB默认的参数较温和,马上打脸。
- 前面两篇文章测试,haproxy与use_bloom_filter和blocksize 和sysbench有直接相关的联系,但是现在基于100万数据,haproxy的加速甚少,use_bloom_filter和blocksize设置性能反而有所降低,笔者认为haproxy与sysbench有强联系,而use_bloom_filter与blocksize是弱联系。强联系通过深一层的优化,还可以有所提高,其中一个节点的2883的连接特别多,其它两个节点的连接特别少,弱联系则是影响不大,如今基于100万的数据 use_bloom_filter与blocksize没有起作用了。
- 使用haproxy测试,一个obproxy接收的请求连接远远大于其它两个obrpxy,所以haproxy这里还是有优化的空间。
准备通过应用层的层面,看性能有没有进一步提高 的可能性。sysbench的业务逻逻辑全看oltp_common.lua ,如下
local stmt_defs = {
point_selects = {
"SELECT c FROM sbtest%u WHERE id=?",
t.INT},
simple_ranges = {
"SELECT c FROM sbtest%u WHERE id BETWEEN ? AND ?",
t.INT, t.INT},
sum_ranges = {
"SELECT SUM(k) FROM sbtest%u WHERE id BETWEEN ? AND ?",
t.INT, t.INT},
order_ranges = {
"SELECT c FROM sbtest%u WHERE id BETWEEN ? AND ? ORDER BY c",
t.INT, t.INT},
distinct_ranges = {
"SELECT DISTINCT c FROM sbtest%u WHERE id BETWEEN ? AND ? ORDER BY c",
t.INT, t.INT},
index_updates = {
"UPDATE sbtest%u SET k=k+1 WHERE id=?",
t.INT},
non_index_updates = {
"UPDATE sbtest%u SET c=? WHERE id=?",
{t.CHAR, 120}, t.INT},
deletes = {
"DELETE FROM sbtest%u WHERE id=?",
t.INT},
inserts = {
"INSERT INTO sbtest%u (id, k, c, pad) VALUES (?, ?, ?, ?)",
t.INT, t.INT, {t.CHAR, 120}, {t.CHAR, 60}},
}
笔者现在还有两招, 一个是网上的方法,另外还有自己的一个自己的想法,
网上的方法,就把表分区,然后id和k一起做局部索引。
CREATE TABLE sbtest(
id int(11),
k INTEGER DEFAULT '0' NOT NULL,
c CHAR(120) DEFAULT '' NOT NULL,
pad CHAR(60) DEFAULT '' NOT NULL,
PRIMARY KEY (id),
KEY `k_1` (id,k) BLOCK_SIZE 16384 LOCAL
) PARTITION BY HASH(k) PARTITIONS 8 ;
实践出真知,经过笔者测试发现好慢啊,比原来更慢。最后试了笔者自己想的办法。笔者就是对余下两个也做局部索引, 虽说sysbench看上去与这两个字段没有关系,最关键的id和k已经做索引了,先补刀了再说,在原表上面再加了两个字段局部索引,
create index c1 on 表名© local;
create index pad1 on 表名(pad) local;
把得到跑的最好一份数据如下,别小看这份数据,比以前好多了。虽说延迟降不了多少,但是吞吐量的QPS比以前强多了。基于1C4G,集群总资源是3C和12G,CPU用的是Intel® Xeon® Silver 4210 CPU @ 2.20GHz,主要变量变动是局部索引。 笔者还打算做个全局索引与局部索引比对,再观察内部活动SQL Trace、SQL Audit 表、慢查询日志的变化,很不幸,第二天虚拟机回收删除了,没有办法继续测试。多次测试的数据差不多逼近了我想要的结果,单就sysbench这个业务场景,OceanBase擅长做海量OLTP的业务场景,它不像TiDB那样松散耦合,协调、计算、存储分离,而是单个observer里面SQL、计算、存储紧密耦合,单独在本地节点完成称为本地作业、尽量避免远程作业和分布式作业。其中local建的就是局部索引,可以争取本地作业。
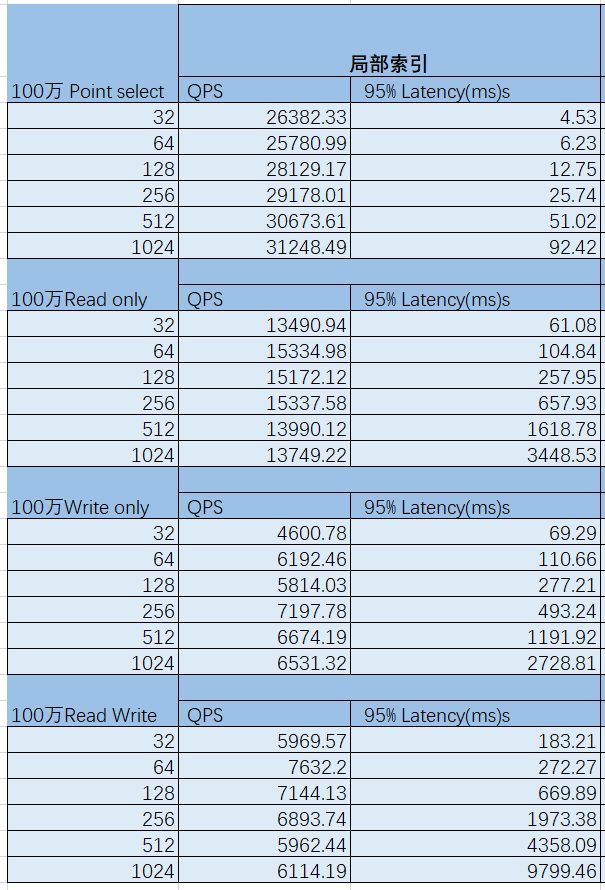

测试总结及问题归纳
- 永无止境 ,还有提升的空间,现在测试的 状态,磁盘IO在一瞬间快写满了,可以考虑SLOG与CLOG分开,最高峰时,一个节点的CPU用上80%左右,而另外两个节点用上接近70%左右。
- 整个过程最费时间和精力的就是填数,连续创建30个表需要大量的内存,因为内存太少,可以先创建10个100万的表,然后建空表,执行 insert into 空表名 select * from 100万表名 ,每填 充一个执行echo 3 > /proc/sys/vm/drop_caches, 这样不会发生租户内存错误。
- sysbench这个业务场景的OLTP都是基于单表的修改或删除,最好充分利用局部索引,因为局部索引,发生在单机,笔者在这里的调整还不够优化。
- haproxy与bloom filter、 blocksize对sysbench性能提升,要排在局部索引之后,要提高性能,先想好如何发挥OceanBase的集中式 优势, 然后再是如何发挥OceanBase的分布式 优势,现在来看haproxy与bloom filter、 blocksize属于分布式因素。
