




作者简介
施博文,目前就职于腾讯云 PG 团队
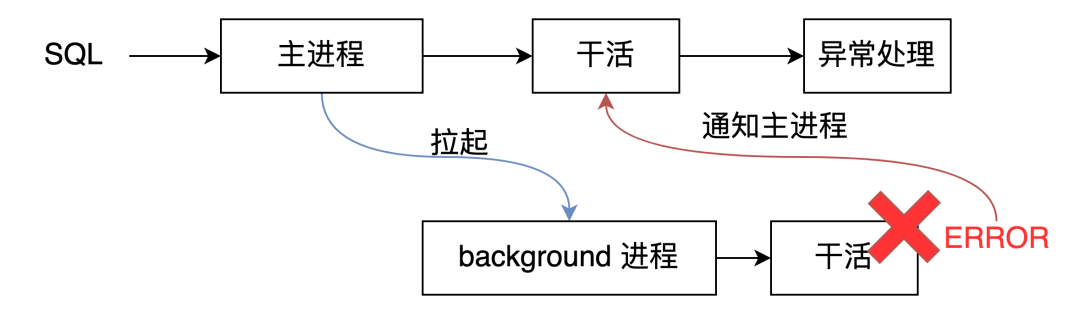
如何使用并行框架
/* 进入并行模式,防止不安全调用。例如在使用并行框架的时候出现写操作 */EnterParallelMode();/* 初始化 ParallelContext:存放本次并行计算的基本信息 */pcxt = CreateParallelContext("library_name", "function_name", nworkers);/* 给用户自定义内容预分配空间 */shm_toc_estimate_chunk(&pcxt->estimator, size);shm_toc_estimate_keys(&pcxt->estimator, keys);/* 创建动态共享内存,并将 GUC、Snapshot 这类的信息序列化后拷进去 */InitializeParallelDSM(pcxt);/* 将用户自定义内容插入动态共享内存中 */space = shm_toc_allocate(pcxt->toc, size);shm_toc_insert(pcxt->toc, key, space);/* 启动 background worker 进程(从进程)*/LaunchParallelWorkers(pcxt);/* do parallel stuff *//* 等待所有从进程退出 */WaitForParallelWorkersToFinish(pcxt);/* read any final results from dynamic shared memory *//* 清理 ParallelContext */DestroyParallelContext(pcxt);/* 退出并行模式 */ExitParallelMode();
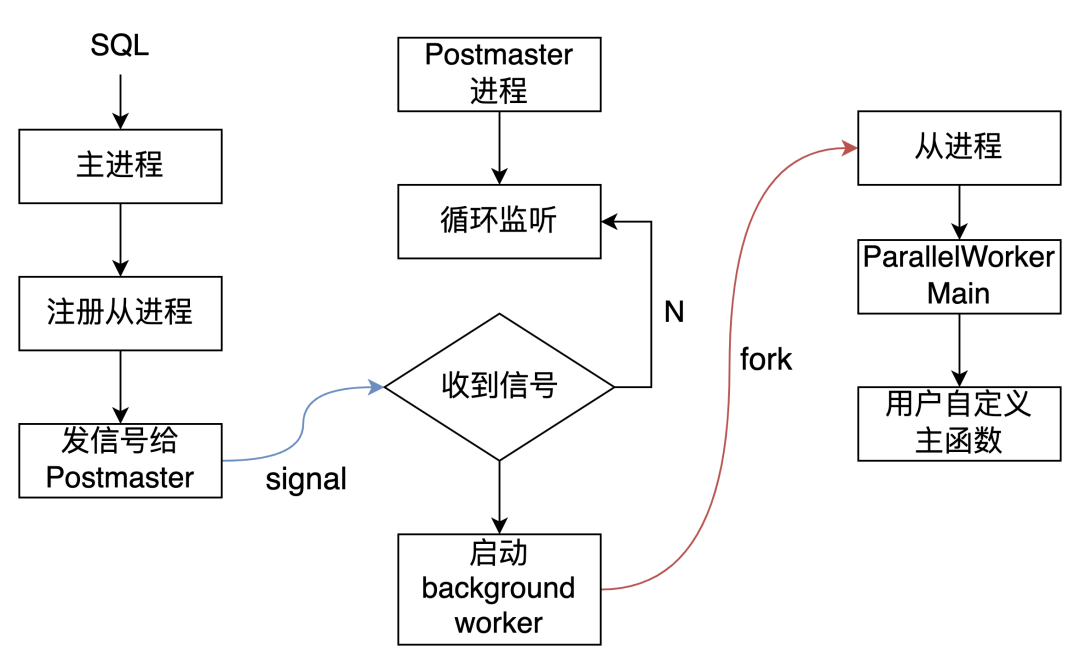
LaunchParallelWorkers函数的核心代码。
voidLaunchParallelWorkers(ParallelContext *pcxt){* 并行框架要求在不能启动从进程的情况下,也能正常运行 */if (pcxt->nworkers == 0 || pcxt->nworkers_to_launch == 0)return;** 主进程需要成为 Lock Group Leader** PG 认为:对于一个并行查询,主进程和它的从进程们为一个进程组,同一个进程组内部锁是共享的。* 即一个进程拿到 AccessExclusiveLock 的时候,同一进程组的另一个进程能拿到 AccessShareLock 锁。* 如果不这么做的话,会出现死锁。举个例子,主进程已经拿了一个 AccessExclusiveLock 锁,* 这时候从进程需要拿 AccessShareLock 才能完成工作。* 此时从进程无法拿到锁,没法结束工作;主进程因为从进程没有结束,不能释放锁,于是就 hang 住了。* 因此,并行框架引入了 lock group 的概念。同一个 lock group 中的进程不受锁排他性的影响。* 具体可参考 src/backend/storage/lmgr/README ,我会在后续的博客中介绍。*/BecomeLockGroupLeader();* 如果需要启动 worker 的话,必须已经注册动态共享内存了*/Assert(pcxt->seg != NULL);* We might be running in a short-lived memory context. */oldcontext = MemoryContextSwitchTo(TopTransactionContext);* worker 信息初始化 */memset(&worker, 0, sizeof(worker));snprintf(worker.bgw_name, BGW_MAXLEN, "parallel worker for PID %d",MyProcPid);snprintf(worker.bgw_type, BGW_MAXLEN, "parallel worker");worker.bgw_flags =BGWORKER_SHMEM_ACCESS | BGWORKER_BACKEND_DATABASE_CONNECTION| BGWORKER_CLASS_PARALLEL;worker.bgw_start_time = BgWorkerStart_ConsistentState;worker.bgw_restart_time = BGW_NEVER_RESTART;sprintf(worker.bgw_library_name, "postgres");sprintf(worker.bgw_function_name, "ParallelWorkerMain");worker.bgw_main_arg = UInt32GetDatum(dsm_segment_handle(pcxt->seg));worker.bgw_notify_pid = MyProcPid;** 启动进程,并行框架要求在不能启动从进程的情况下,也能正常运行。*/for (i = 0; i < pcxt->nworkers_to_launch; ++i){memcpy(worker.bgw_extra, &i, sizeof(int));if (!any_registrations_failed &&RegisterDynamicBackgroundWorker(&worker,&pcxt->worker[i].bgwhandle)){shm_mq_set_handle(pcxt->worker[i].error_mqh,pcxt->worker[i].bgwhandle);pcxt->nworkers_launched++;}else{** 即使少启动了 worker ,也能正常运行。但是需要先 detach 该 worker 的错误消息队列,否则后续我们会一直等这个 worker 启动(hang 住)。*/any_registrations_failed = true;pcxt->worker[i].bgwhandle = NULL;shm_mq_detach(pcxt->worker[i].error_mqh);pcxt->worker[i].error_mqh = NULL;}}** Now that nworkers_launched has taken its final value, we can initialize* known_attached_workers.*/if (pcxt->nworkers_launched > 0){pcxt->known_attached_workers =palloc0(sizeof(bool) * pcxt->nworkers_launched);pcxt->nknown_attached_workers = 0;}/* Restore previous memory context. */MemoryContextSwitchTo(oldcontext);}
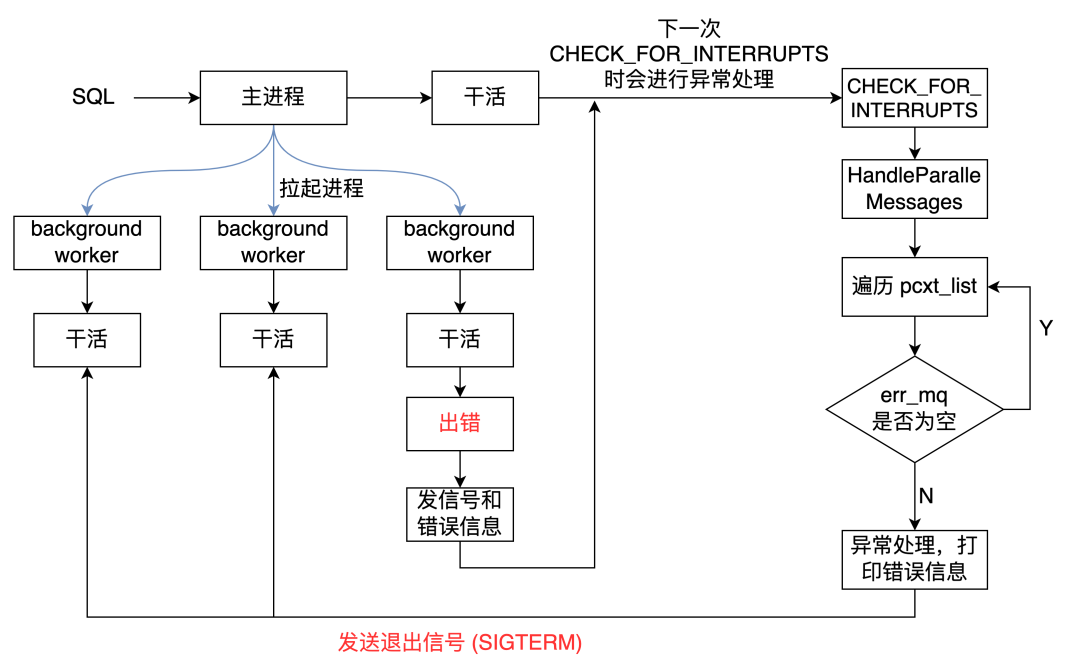
总结
PostgreSQL中文社区欢迎广大技术人员投稿
投稿邮箱:press@postgres.cn
文章转载自PostgreSQL中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
