




假设:关系s的记录数=5000,磁盘块数=100
关系r的记录数=10000,磁盘块数=400
以下代价估算全部不计磁盘搜索代价。
1.嵌套循环连接
由两个或者多个嵌套的for循环组成。嵌套循环连接的本质是对内层关系作选择运算。
对于 关系r与关系s 的θ连接,假设r为外层关系(驱动表),s 为内层关系(被驱动表),tr * ts表示将r和s的元组拼接而成的一个新元组,并且去掉重复的属性。
其伪代码如下:
for each元组tr in r do
begin
for each元组ts in s do
begin
测试元组对(tr,ts)是否满足连接条件θ
如果满足,把tr * ts加到结果中
end
end从上述算法可知,对于关系r中的每条记录都必须对s作一次完整的扫描。即r中有几条记录,s就必须被循环几次。
所以s要足够小,或者尽可能多地将其块装载进内存中。r通过条件过滤后的记录要少。由于需要逐个检查元组,所以嵌套循环连接的代价通常很高。
特点:以元组(记录)为单位进行操作。
优点:对参加运算的关系没有要求;适合于任何连接条件。
代价(I/O): 最坏情况(缓冲区只能够容纳每个关系的一个块):
nr * bs + br (r为外层关系)或 ns * br + bs (s为外层关系)
最好情况(内层关系s能完全放在内存中): bs + br
eg:考虑s与r做自然连接,并且没有可用索引。
假设s为外层关系,r为内层关系,在最坏的情况下,代价为5000*400+100=2000100.
假设r为外层关系,s为内层关系,在最坏的情况下,代价为10000*100+400=1000400。
最好情况下,代价为100+400=500.
2.块嵌套循环连接
嵌套循环连接的变种,是其在实践中最广泛使用的形式。当缓冲区太小而无法容纳任何一个关系时,可以以块的方式循环,以减少块读写次数。
for each 块 Br of r do
begin for each 块 Bs of s do
begin for each 元组 tr in Br do
begin for each 元组 ts in Bs do
begin
测试元组对(tr,ts)是否满足连接条件θ
如果满足,把tr * ts加到结果中
end
end
end
end特点:按块操作
优点:对参加运算的关系没有要求, 适合于任何连接条件。
代价: 最坏情况(缓冲区只能够容纳每个关系的一个块):
br * bs + br 或bs * br + bs
最好情况(内层关系s能完全放在内存中): bs + br
eg:考虑s与r做自然连接,使用块嵌套循环连接算法。
假设s为外层关系,r为内层关系,在最坏的情况下,代价为100*400+100=40100.
假设r为外层关系,s为内层关系,在最坏的情况下,代价为1400*100+400=10400。
最好情况下,代价为100+400=500.
对于(块)嵌套循环连接一些改进:
1.连接属性是内层关系的码时,则对于每个外层关系元组,内层循环一旦找到了首条匹配原则就可以终止。
2.外层关系不是每次读入一个磁盘块,而是每次读入内存最多能容纳的磁盘块数。即,如果内存有M块,则一次读取外层关系r中的M – 1(有些资料说M-2,区别在于是否考虑存放结果集占用的内存块)块,当读取到内层关系中的每一块时,把它与已读取到内存的外层关系中的M – 1块做连接。于是内层关系的扫描次数从b r次减少为 ⌈b r /( M – 1)⌉次,全部代价为 ⌈br /( M – 1)⌉* bs +br。
3. 内层循环轮流做正、反向扫描,重用缓冲区中的数据,以减少磁盘读取。
4.内层循环利用索引。
3.索引嵌套循环连接
在内层循环中利用连接属性上的索引, 用索引扫描代替对内部表的全表扫描。
伪代码:
for each 元组 tr in r do
begin for each与元组tr满足连接条件的索引项
in s关系在连接属性上的索引do
begin 利用索引取到相应的ts
把tr . ts加到结果中
end
end
代价: 最坏情况(缓冲区只能够容纳关系r的一个块和索引的一个块):
br + nr * c (其中c表示对关系S使用连接条件利用索引进行选择操作的代价)
不需要考虑最好情况。
从代价计算公式可以看出来,当r,s上均有索引时,把元组较少的关系(过滤后记录集小的)作为外层关系时效果较好。
eg :考虑s与r做自然连接,r在连接属性上有B+树索引,树高为4。s为外层关系,r为内层关系,在最坏的情况下,代价为 100+5000*5=25100。
4.嵌套循环连接适用情况
如果驱动结果集记录少,同时被驱动表的连接列存在选择性很好的索引,那么此时嵌套循环连接的效率就会非常高。
如果驱动结果集太多,那么就算被驱动表上有索引执行效率也不会高。
5.示例
oracle中,可以使用use_nl(表名) 或者 USE_NL_WITH_INDEX(表索引) 来 强制优化器走嵌套循环连接。
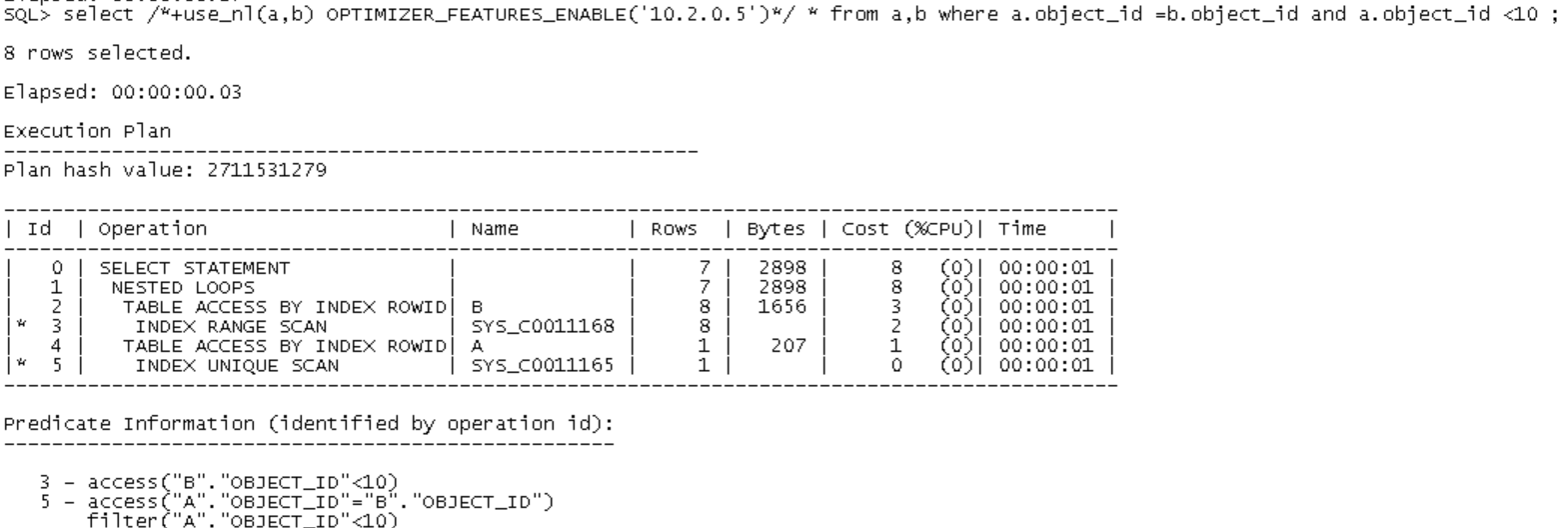
禁用掉其中一个索引后,优化器会自动将有索引的表选为被驱动表
SQL> alter index SYS_C0011168 unusable;
Index altered.
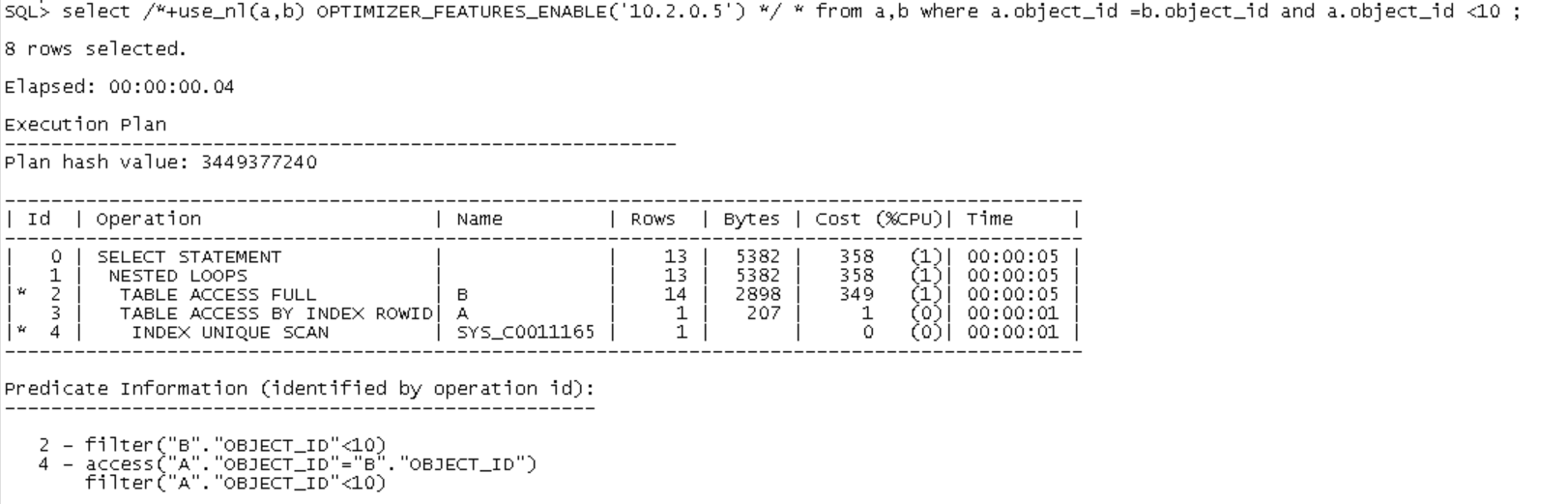
当需要的被驱动表的属性为连接属性,可省去回表工作。
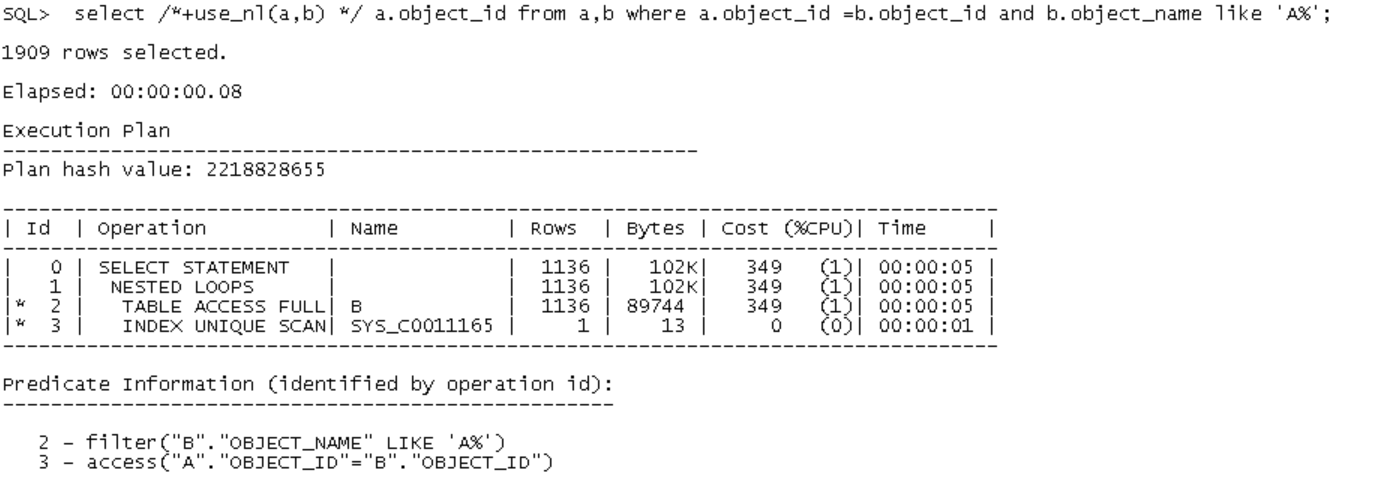
为了提高NL连接的效率,11G开始引入了向量I/O:将原先一批单块读所需要耗费的物理IO组合起来,然后用一个向量IO去批量处理它们。
在这种情况下, 第一个嵌套循环连接 处理驱动表中的值和被驱动表中的索引。第二个嵌套循环处理第一个嵌套循环连接的结果和被驱动表之间的连接。
 执行顺序:3-->4-->2-->5-->1-->0
执行顺序:3-->4-->2-->5-->1-->0
