






分享嘉宾 —— 姚延栋
北京四维纵横数据有限公司(yMatrix)创始人
原 Greenplum 北京研发中心总经理 Greenplum 中国开源社区创始人 PostgreSQL 中文社区常委 壹零贰肆数字基金会(非营利组织)联合发起人
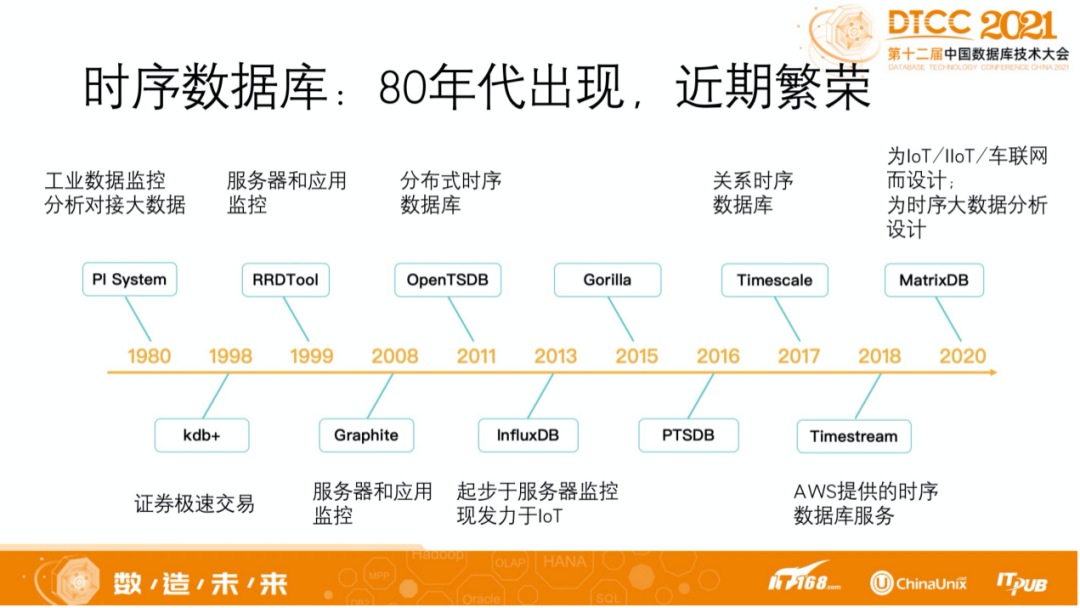
数据处理平台60年
大约在上世纪80年代,有一个叫分析型数据库(OLAP)的分支,也叫 MPP 数据库发展起来,专门针对分析场景复杂查询优化。在2010年以后出现了很多新名词,像 NewSQL、HTAP、Lakehouse、多模、批流一体等。
这些名词我们就不做详细介绍了,但是它们的核心点在于跨界融合。从2010年,我们开始尝试在不同的产品之间进行融合,来解决过去需要多个产品解决的问题。到2020年,出现了超融合数据库,也就是多层次、多角度地进行深度融合。

纵观过去60年,我们不难发现,大约每隔10年,就会出现一次技术 PK。第一次是文件系统和数据库,第二次是 CODSAL 和关系数据库,第三次是 XML 数据库和关系数据库,第四次是 NoSQL 和分布式关系数据库。
当时,很难去辩证哪一个技术在未来会变成更有优势的技术路线。现如今,基本就明确了关系型数据库、分布式数据库的生命力更旺盛。技术的碰撞最终目的是互相学习,然后衍生出适应技术发展的产品形态。
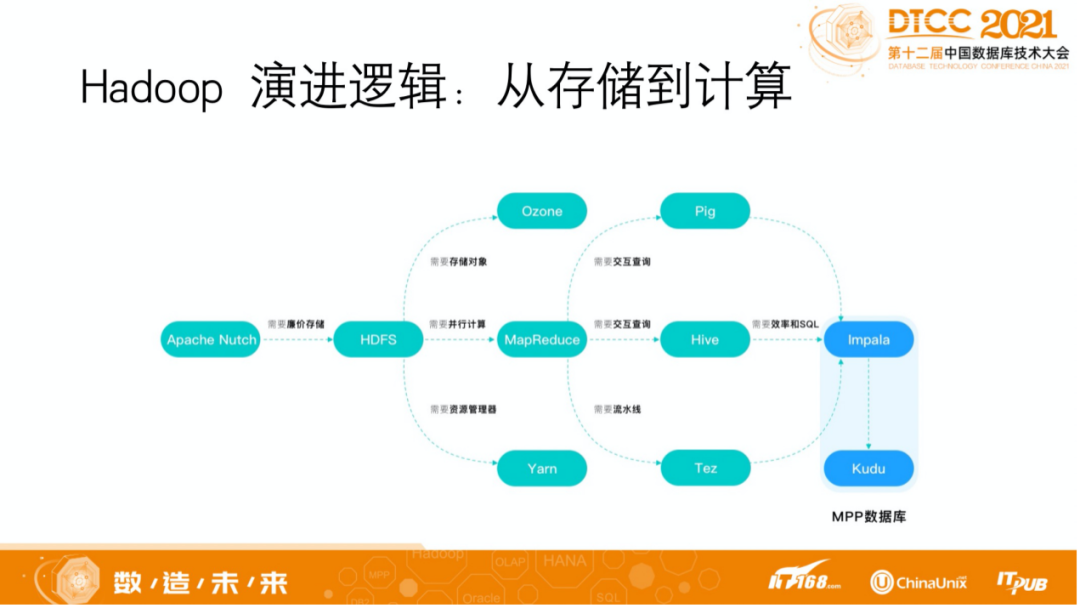
我们讲到数据处理平台时,不可避免会涉及到三个产品。
第一个产品是 Hadoop,它的演进逻辑是从存储到计算。它起源于 Apache Nutch 项目(一个网页爬取工具,后来遇到大数据量的网页存储问题)。
Apache Nutch 需要一个存储引擎,所以做了 HDFS,然后出现并行计算 MapReduce 和交互查询 Hive,继而又出现了效率较高的 Impala。到目前为止,Hadoop 有点远离大数据 C 位,这和它的底层演进逻辑有一定的关系。

第二个产品是 Spark,它的演进逻辑是从计算到存储。Spark RDD 是纯粹计算的接口,后面出现了 Spark SQL 和 DataFrames,以及 Spark Streaming、Spark Graph、Spark ML 等。
所以我们能够看出,Spark 前几年都在做计算,为了适应不同的场景,后来 Spark 面临数据存储和性能优化的问题,开始做 DeltaLake。同时提出了一个词,叫做 Lakehouse,它是一种结合了数据湖和数据仓库优势的新范式。

第三个 Snowflake 的演进逻辑为从雪花到雪球,然后到更大的雪球。它背后的关键设计是存算分离、存算同时演进,开始就是一个完整的数据库,存储层和计算层都不断变化更新。
主流时序数据库架构分析

上图为行业流行度排名第一的时序数据库 InfluxDB 的下一代时序数据库 IOx 要实现的目标,我们可以关注两点。一个是扩展性,第二个是分析性能。这也表明了流行度行业老大 InfluxDB 在时序领域摸爬滚打了多年后对未来时序场景的认知和判断。
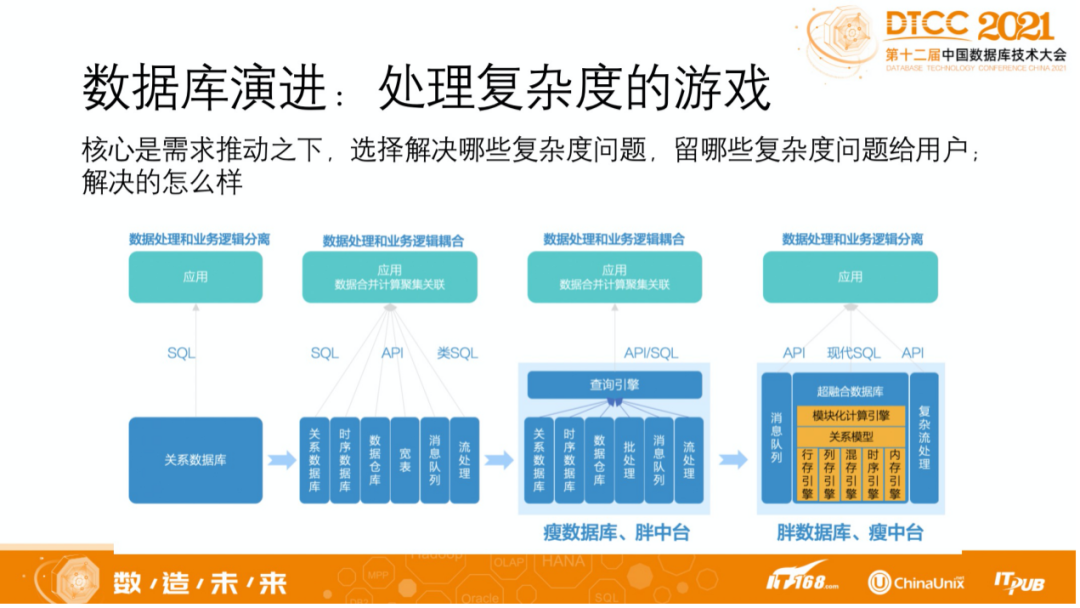
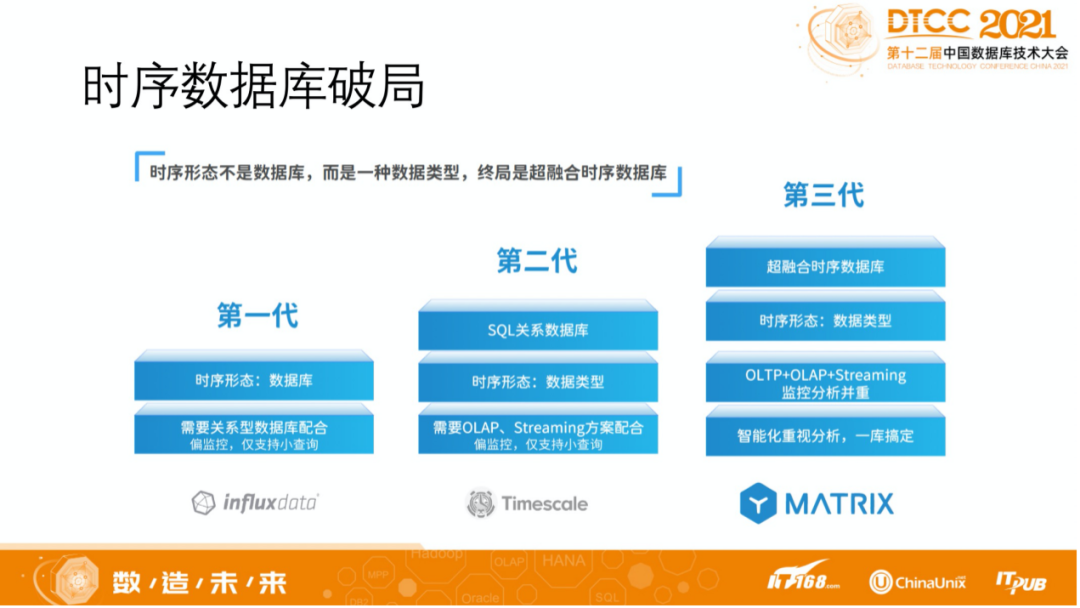
时序数据库破局探讨
当前,时序架构基本上都是 DIY 搭建出来的技术栈,这样的架构栈通常会出现“2大特征”:1、慢;2、复杂。其中,慢是指使用专用产品,看似很快,但端到端组合在一起会慢;复杂意味着技术栈复杂,稳定性差,开发运维成本高,软硬件成本高,性能低,人才稀缺,把复杂度留给了用户。
那么,时序数据库应该是怎样的呢?它应该是快且简单的。奥卡姆剃刀原理中指出,“如无必要,勿增实体。”本质上要考虑是谁简单,谁复杂?是用户简单、数据库人承担搞定多种数据类型多种查询场景的复杂度;还是数据库人简单的只做一件事情的数据库,把搞定多种数据类型和多样新查询场景的复杂度(譬如拼搭 Hadoop 全家桶、引入多种 NoSQL 产品等)交给用户?
未来,如何做一个更适合时序数据库场景的产品?既然要判断一个产品,肯定要回归到场景。和其他数据库一样,时序数据库具备读和写两个场景,但是它的读和写都非常有特色,写的场景需要平稳高效,并且大部分数据是实时数据,读的场景有点查/最新值、查询、峰值检测,高级分析模型等。
整个场景是多种多样的,为了匹配这种需求,如何去设计产品?时序场景95-99%为写操作,所以大多数时序数据库使用类 LSM 树方式,基于 B+ 树的 MatrixDB 写入性能是基于 LSM/TSM 的 InfluxDB 的几十倍。
这一点在 PostgreSQL中文社区第三方评测得到验证:时序数据库InfluxDB和MatrixDB加载性能实测。在400列数的场景下,MatrixDB 比 InfluxDB 快48.6倍,仍然非常强悍,是国产数据库的一个新亮点。
值得一提的是,理论上讲 B+ 树为读而优化,LSM 树为写而优化。原因是B+ 树随机 IO 比较高,但是实际工程实现的时候,有很多手段来降低随机 IO,最大限度地平衡存储和计算,为了提升写的性能,譬如采用 WAL、通过 Buffer 尽量避免随机 IO,通过分区避免 B+ 树太大等,而 LSM 引擎为了提升读的性能,需要内建 B+ 树加速读性能,内建 Bloomfilter 加速读,创建倒排索引加速查询,使用 WAL 避免丢数据。所以最终效果如何还要看实际工程优化的情况。

当然我们对比 B+ 树和 LSM 的主要目的是说明企业产品优化有很多需要关注的点,而不是说 MatrixDB 只支持 B+ 树。实际上 MatrixDB 支持多种存储引擎,包括基于 B+ 树的 Heap 引擎,也有基于 LSM 变种的 mars 存储引擎。

我们认为最好的时序架构是超融合架构,这种架构把极简、极速留给客户。超融合架构的核心是在数据库中,通过极致的可插拔,实现不同的存储引擎,可以是行存引擎、列存引擎、内存引擎、LSM 引擎等。它们之间是互相隔离,互相不会影响。
在未来的数据库里面,比较有生命力的是关系模型。关系模型不再是上世纪70年代纯粹的只支持简单数据类型的关系模型,现在的关系数据模型的字段可以支持复杂数据类型。做一个数据库极具挑战,不单单是做引擎,还要做周边大量的组件。而超融合数据库基于关系数据模型,通过可插拔存储实现一个数据库同时支持关系数据、时序数据、GIS数据、半结构化数据和非结构化数据的 All-in-One。

什么是超融合数据库?
从开发运维角度来看,它就相当于是关系库+时序库+分析库。以 MatrixDB 为例,不同的表可以使用不同的存储引擎,譬如总共200张表,180张表使用 heap 存储,用以处理关系数据的读写,20张表为时序表,用以存储时序数据的读写,他们之间还可以直接 JOIN。
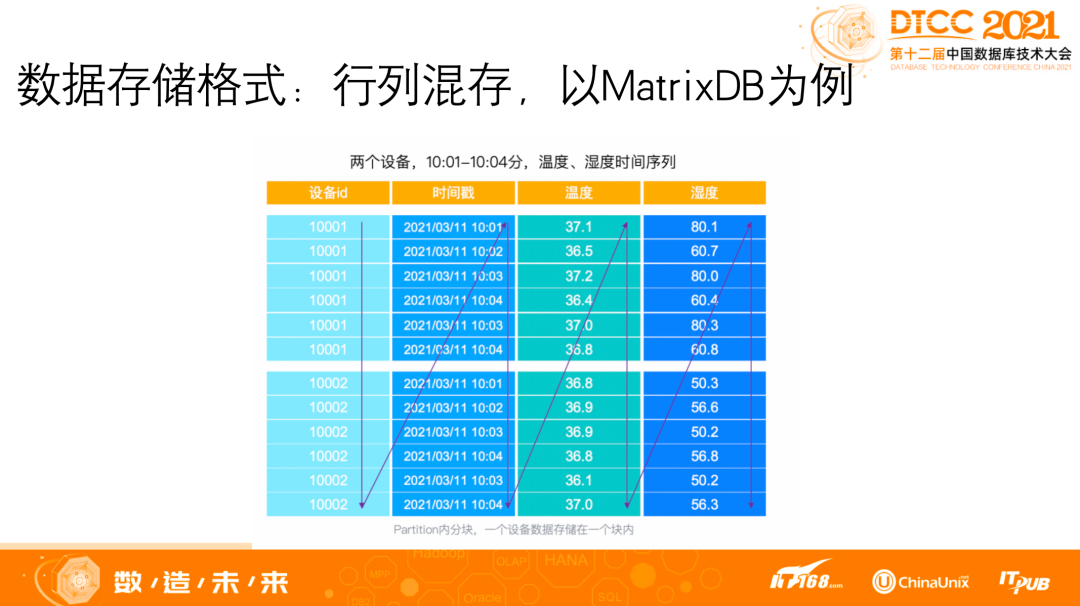
MatrixDB 具有以下特性:
关于时序数据的写入,支持顺序上报、乱序上报、延迟上报、异频上报、上报信号/指标动态增减、更新或删除、自动降采样、持续聚集等多种方式。
写入的场景具备高性能、平稳持续、实时写入、数据正确性等特色。其中,95%以上操作是插入,且对性能敏感。平稳持续方面,没有明显的高低峰。实时写入方面,要求秒级写入。数据正确性方面,保证不错、不重、不丢,让开发人员聚焦业务,而不是数据处理。
时序数据存储方面,存储效率/压缩比十分重要,好的时序数据库可以做到10:1左右,针对某些范式数据压缩比高达几十倍。支持针对数据类型进行优化,支持多种编码压缩算法,包括 delta-delta、gorilla、RLE、lz4、zstd 等,以达到压缩比和压缩速度的平衡。
支持冷热数据分级存储,热数据、温数据、冷数据分层,最小化存储开销,具备自动分区管理功能,到了时间自动会执行相应的操作,无需人工干预。
支持多样性数据类型,比如,字符串、数字、日期/时间、布尔类型等基本数据类型,以及数组、IP 地址等复合数据类型,兼顾效率和 schemaless 的灵活性的KV数据类型,点、线、多边形等空间数据类型(和函数),XML/JSON 等半结构化类型,文本等非结构化数据类型。
支持多样化的查询,包括单表的点查、明细、聚集、多维查询,多表的 JOIN,支持10+表关联,以及子查询、窗口函数、Cube、CTE 等高级分析。
支持数据库内机器学习能力,在数据库内部,实现了60多种机器学习的算法,包括监督学习、无监督学习、统计分析、图计算等。
支持数据库内建分析,比 Spark 快10倍以上。通过在数据库内执行 Python/R/Java 代码,避免移动海量数据,实现高效率灵活的数据分析。
一个产品本身有很长的路要走,不仅是技术层面,还需要具备完善的开发工具和生态,实现开箱即用。MatrixDB 支持各种流行 IDE,包括 IntelliJ、DataGrip、Dbeaver、Navicat 等,可以和 BI 和可视化的产品进行对接,支持 ETL/CDC,支持 MQTT、OPC-UA、OPC-DA、MODBUS 等 IoT 协议。
作为一款企业级产品,MatrixDB 具备稳定性、完备性,具备图形化部署,线性扩展,可以单机部署,也可以集群化部署,监控、报警以及可视化,在线扩容,不停机,不停业务,分布式备份恢复,资源管理,分钟级升级等功能。




 分享、点赞、在看,一起为 yMatirx 充电!
分享、点赞、在看,一起为 yMatirx 充电!
