




上一篇文章讲述了OLTP系统大量硬解析的危害,其中就包含可能会引发ora-4031的报错,今天就来看看如果遇到ora-4031,我们要怎么处理呢?顺便插一句,有些人可能会说ora-4031问题的根本原因在于内存不够,那我加内存不就能避免了嘛,其实我想说的是很多时候,看似是某些系统资源出现所谓的瓶颈,但并非真的是资源达到了瓶颈,就比如说内存资源,小内存有小内存的烦恼(ora-4031),大内存有大内存的麻烦(页管理),所以并不是出了问题就能通过加资源去解决的,往往会适得其反哦。
进入正题,如果我们的系统遭遇ora-4031的报错我们该如何处理呢?首先我们先来看一下ora-4031报错的官方解释:
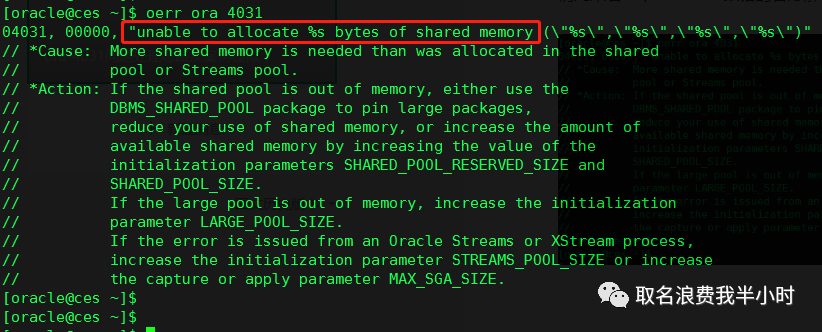
字面解释为无法从SGA当中的某个池去分配内存(连续的多少k内存)
我一直都认为经验很重要他能让我们快速的从为数不多的可能原因中一项一项的排除最终找到根因,就算当下你没多少经验,那么别人总结好的经验我们就可以拿过来用,比如ora-4031问题的常见原因有:
配置问题之配置错误
配置问题之配置过小,随着慢慢的使用就不够用了
内存碎片问题,配置内存时足够大,但随着慢慢的使用,内存碎片化了
BUG导致,内存足够多,但由于某些组件异常增长,导致大量内存被异常占用
既然是无法分配内存,那么我们解决这个问题的核心思路就是看看shared pool中哪个组件占用的内存最多。
首先先确定是SGA的哪个pool无法分配内存(一般情况下在alert日志的报错信息中可以明确看到是哪个pool引起的)
然后查看对应的各个subpool的使用情况,确认哪个组件使用的内存最多
如果使用最多内存的是组件SQLA,那基本可以确实该系统绑定变量没有使用好
如果是一些很不常见的组件使用内存最多,那么一般就是因为BUG
下面列举一些常用的检查命令:
show parameter sga show parameter pool select component,current_size/1024/1024 size_mb from v$sga_dynamic_components; select pool,name,sum(bytes)/1024/1024 MB from v$sgastat group by pool,name order by 3; set lines 200 pages 200 select pool,name,sum(bytes)/1024/1024 MB from v$sgastat where pool = 'shared pool' group by pool,name having sum(bytes)/1024/1024>5 order by 3; |
下面是我的环境中上面语句执行的截图:
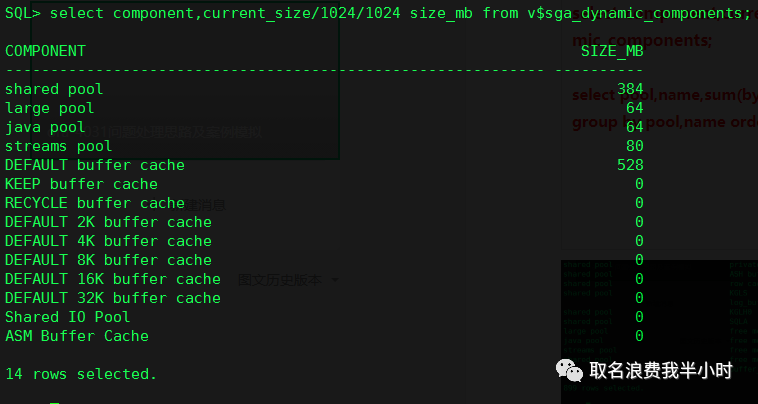
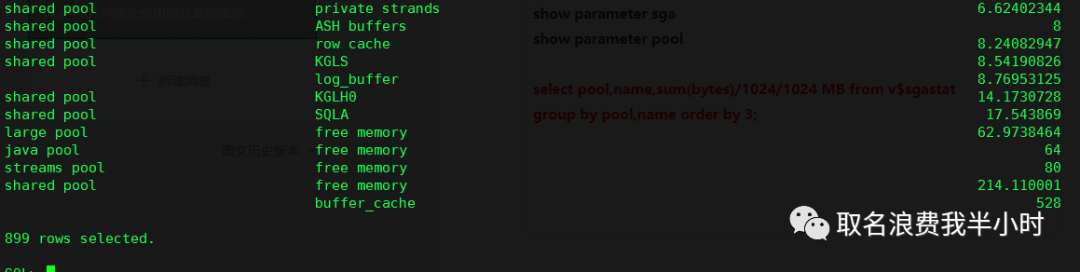
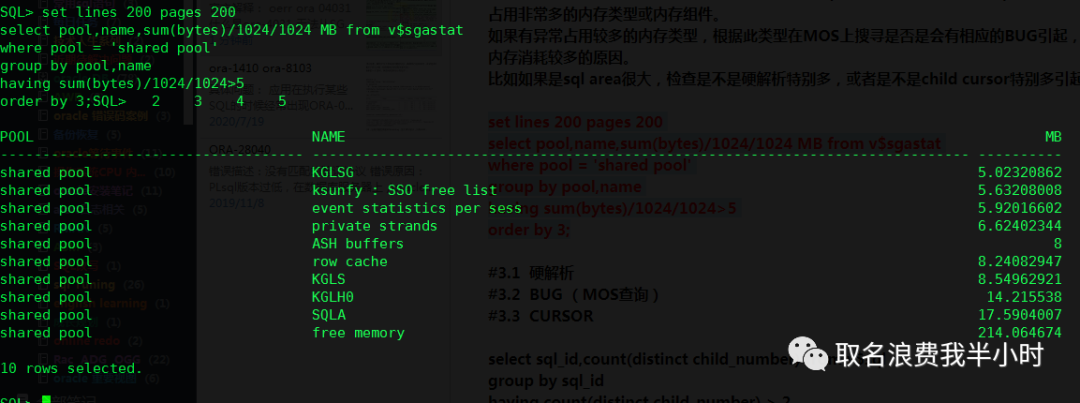
如果Shared Pool相较于系统规模来说足够大(一般几个G就已经很大了),检查Shared Pool中有没有占用非常多的内存类型或内存组件。如果有异常占用较多的内存类型,根据此类型在MOS上搜寻是否是会有相应的BUG引起,或者分析这种类型的内存消耗较多的原因。比如如果是sql area(SQLA)很大,检查是不是硬解析特别多,或者是不是child cursor特别多引起。
接下来模拟因为配置错误导致ora-4031报错的案例
在模拟之前我们先来看两个隐含参数,_KSMG_GRANULE_SIZE和_KGHDSIDX_COUNT
_KSMG_GRANULE_SIZE:oracle内存分配的粒度,分配的内存都是这个参数的整数倍
_KGHDSIDX_COUNT:从oracle9i开始,shared pool和large pool(从9.2),streams pool(10g) 可以由multiple subpools组成,每个subpool由一个latch 来保护。subpool的数量是从实例启动的时候,根据shared pool的大小和操作系统CPU的数目来决定的。一个实例最少有一个subpool,最多有7个subpool,subpool的数量可以被隐含参数 "_kghdsidx_count"来控制。
下面开始模拟
select ksppinm,ksppstvl,ksppdesc from sys.x$ksppi x,sys.x$ksppcv y where x.indx=y.indx and upper(ksppinm)='_KSMG_GRANULE_SIZE'; select ksppinm,ksppstvl,ksppdesc from sys.x$ksppi x,sys.x$ksppcv y where x.indx=y.indx and upper(ksppinm)='_KGHDSIDX_COUNT'; |
我的初始环境信息如下:
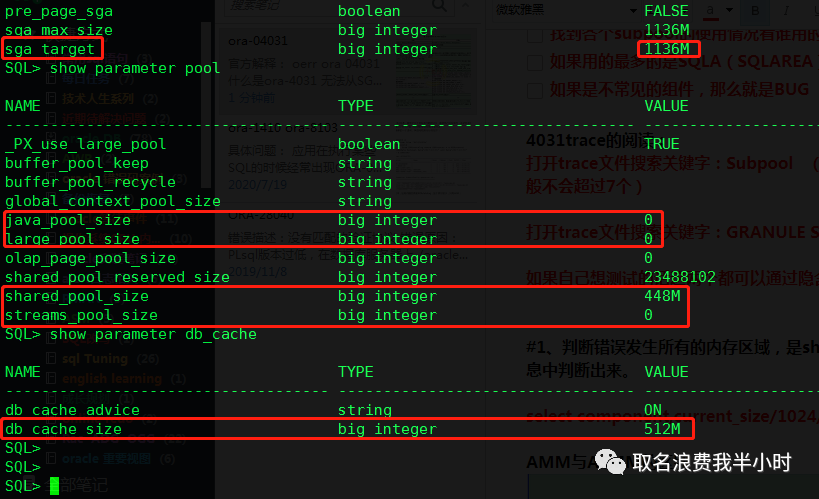
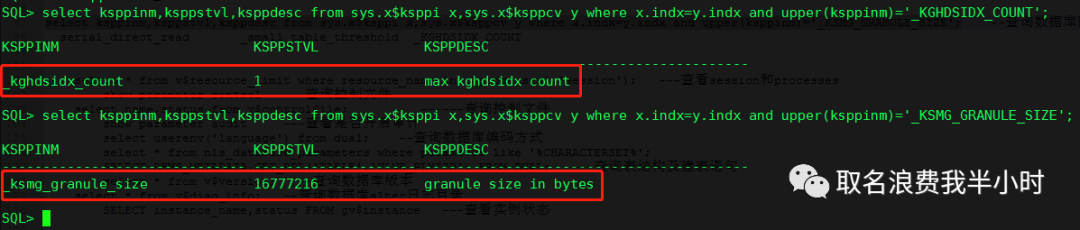
可以看到除了sga中除了shared pool和db cache指定了大小,java pool,large pool,stream pool都是未指定大小的,并且"_KSMG_GRANULE_SIZE"=16M,"_KGHDSIDX_COUNT"=1
接下来做执行以下修改(修改完重启数据库):
alter system set "_KGHDSIDX_COUNT"=3 scope=spfile; alter system set sga_target=1152M scope=spfile; alter system set db_cache_size=512M scope=spfile; alter system set shared_pool_size=512M scope=spfile; alter system set large_pool_size=48M scope=spfile; alter system set java_pool_size=48M scope=spfile; alter system set streams_pool_size=16M scope=spfile; |
可以看到修改已经生效了:
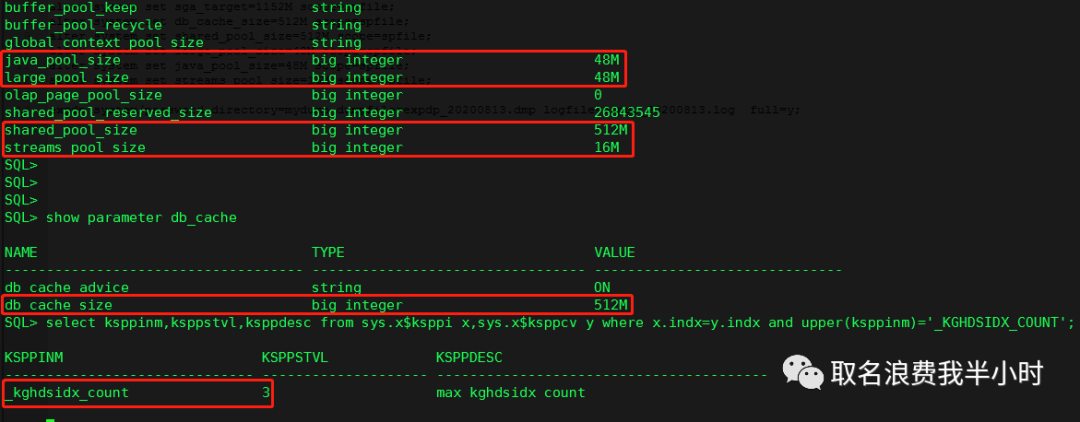
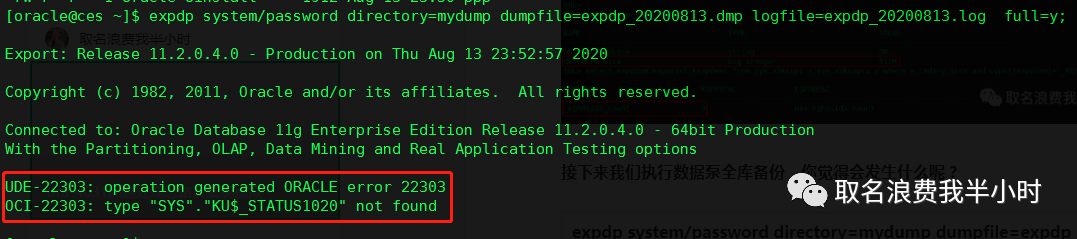
接下来我们执行数据泵全库备份,你觉得会发生什么呢?
| expdp system/password directory=mydump dumpfile=expdp_20200813.dmp logfile=expdp_20200813.log full=y; |
我们再看看alert日志中有什么提示:
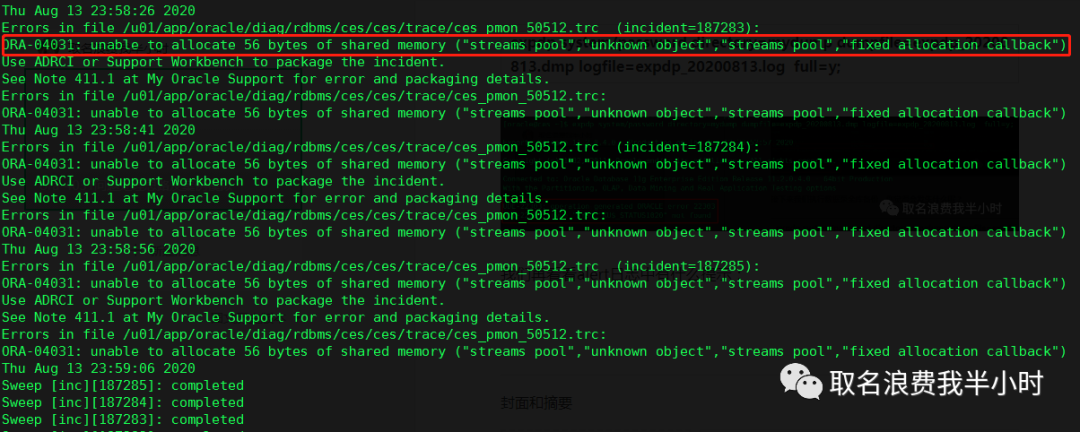
可以看到alert日志中抛出了ora-4031的报错:ORA-04031: unable to allocate 56 bytes of shared memory ("streams pool","unknown object","streams pool","fixed allocation callback"),并且是因为streams pool。
我们再看看4031的trace文件中有什么信息
通过GRANULE SIZE关键字搜索trace文件,可以看到GRANULE SIZE=16M
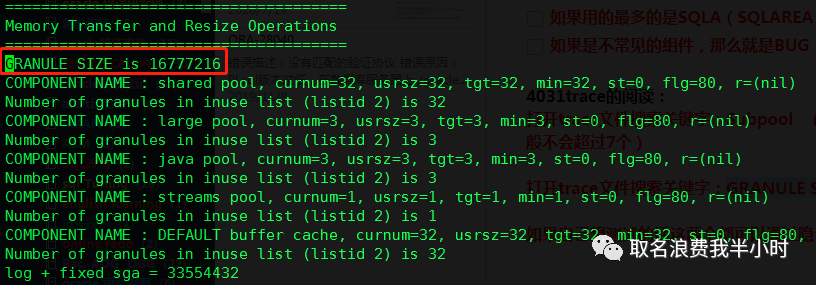
再通过Subpool 关键字搜索trace文件,由于之前设置的参数 "_KGHDSIDX_COUNT"=3 所以这里有三个subpool:
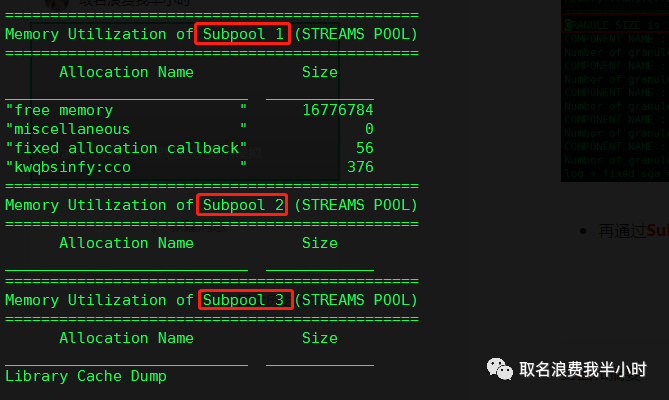
并且由于我们前面特意设定的各个pool的值,导致streams_pool_size最多只有1152-512-512-48-48=32M,这里虽然结果为32M,而实际上最后分给streams pool的只有16M,从而导致subpool2和subpool3是没有内存分配的,从而我们知道了该ora-4031问题的原因是因为错误的内存配置,这也是为什么数据泵备份的时候会报错的原因所在。
总结:这里只模拟了因为内存配置错误而导致ora-4031报错的场景,当然ora-4031的问题原因远远不止这些,不过只要我们知道了解决问题的思路,真正遇到该问题的时候不过是根据思路,根据经验,然后逐项排除,最终找到问题根因而已。
