




偶然间看到老猫多年前的优化视频,按照惯例,模拟走起。
构建测试环境及数据(oracle 11.2.0.4)
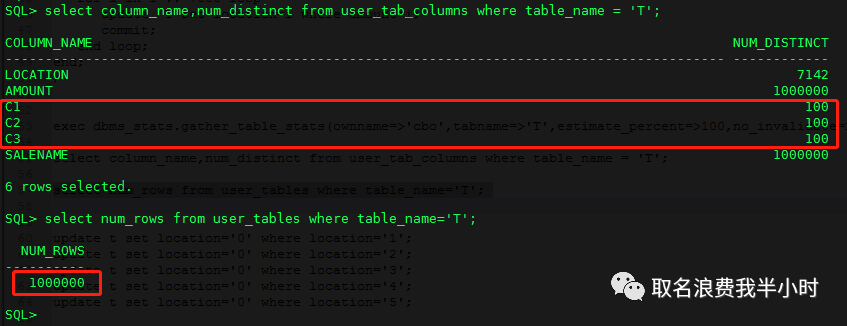
drop table t; create table t(location varchar2(20),amount number,c1 number,c2 number,c3 number,salename varchar2(20)); begin for i in 1 .. 1000000 loop insert into T(location,amount,c1,c2,c3,salename) values ( trunc(i/140), i, trunc(i/10001), trunc(i/10001), trunc(i/10001), i ); commit; end loop; end; / begin for i in 1 .. 7000 loop update T set location=i where amount=i; commit; end loop; end; / exec dbms_stats.gather_table_stats(ownname=>'cbo',tabname=>'T',estimate_percent=>100,no_invalidate=> false); |
select column_name,num_distinct from user_tab_columns where table_name = 'T'; select num_rows from user_tables where table_name='T'; |
好了,接下来我们执行一条sql语句:
select * from t a where amount > (select avg(amount) from t b where a.location = b.location and c1 = 0 and c2 = 0 and c3 = 0) and c1 = 0 and c2 = 0 and c3 = 0; |
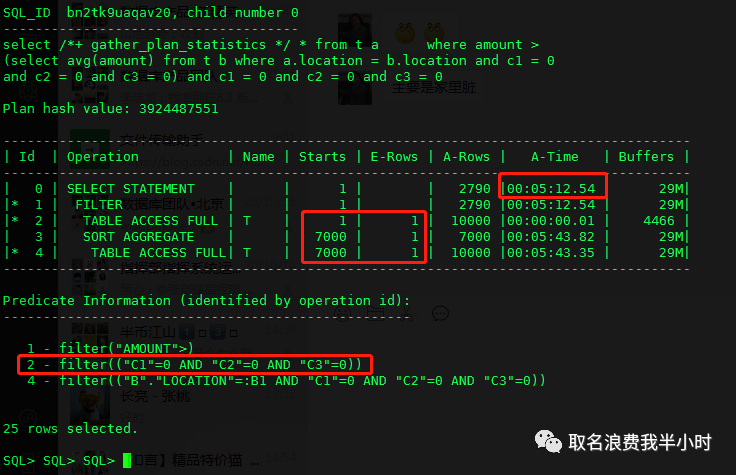
当看到这个真实的执行计划时,很明显,该sql语句仅返回2790行,却要花费5分多钟,并且执行计划第2、4步中的全表扫描,oracle评估的行数都是1,而这和真实的行数差1万倍。哦既然是oracle对cardinality评估不准,那么应该是统计信息的问题,然而手动收集统计信息之后,再次执行依然是这个结果。
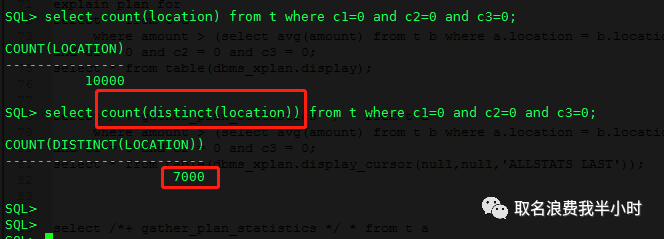
我们再好好看看这个执行计划,最耗时的步骤是第四步,这是一个filter类型的执行计划,他的特点是外层返回多少行,内层就要被执行多少次,而执行计划第二步真实返回行数为10000行,那么就意味着第四步要被重复执行10000次,但filter和NL的区别在于,filter会额外做一个去重的操作,这也是为什么外层返回10000行,内层重复启动只有7000次的原因,下面我们验证一下:
其实每次我在看到filter类型的执行计划时,我都在想,真倒霉,怎么走了filter,其实这是不对的,oracle既然发明了filter肯定是有他的道理的,只不过大多数情况走filter效率不佳,而给人一种filter很垃圾的错觉。就好比我在初学的时候认为全表扫描很垃圾,但其实也完全不是像我想的那样,很多时候对于某些表数据分布情况特殊,或者热点块问题严重,都可以采用全表扫描的方式来缓解。
扯远了,我们继续来分析执行计划,如果执行计划中真实行数就和oracle评估的1行是一致的,那么走filter说不定就是最佳的,那既然评估的和实际的行数相差1万倍,在统计信息准确的情况下是什么原因造成oracle评估错误的呢?
我们继续来看执行计划中的第二步,从上面截图可知,该步的条件为c1=0 and c2=0 and c3=0,那么sql语句就是简单的select * from t where...,再结合该表中列的数据分布情况(c1 c2 c3的ndv都是100,并且都非空),那么根据cardinality的计算公式,我们可以很容易的算出:
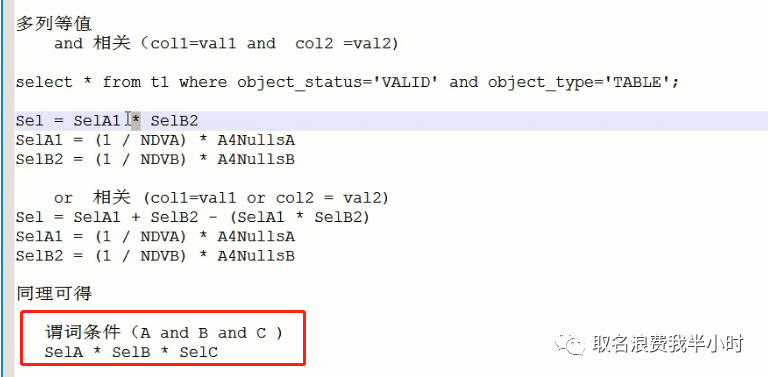
cardinality = num_rows * (sel_c1 * sel_c2 * sel_c3) = 1
原来在统计信息准确的情况下,oracle算出的cardinality值就是1,那难道这条sql就无解了吗?当然不是,oracle的CBO说到底只是一堆数学模型,他做计算的数据来源就是各种统计信息,而统计信息又和统计学上的概念相似,统计学嘛,肯定是有误差的,所以很多时候,他并不能代表所有的情况,总会有一些特例。
那么对于上面的这种场景,我们该怎么去干预让oracle评估的更准呢?答案就是收集这三列的扩展统计信息,如果这条sql的条件只是c1=0,那么没问题,如果条件是c1=0 c2=1 c3=2那么也没问题,但当条件为c1=0 c2=0 c3=0的时候,oracle就搞不清楚了,因为他不知道c1 c2 c3这三个列组合在一起的时候各列数据之间的关系情况。举个简单的例子,假设我们有一张person表,有两个字段,分别是出生月份和星座,现在我们要统计下这张表中既是7月份出生,又是狮子座的人的总数,那么oracle在计算选择率的时候就是(1/12)*(1/12)=1/144,但是如果使用这个选择率来计算的话,是有问题的,因为这两列是有关联的,“七月份的尾巴是狮子座 ”,也就是说7月份中可能有大部分人都是狮子座,这时候oracle对选择率的估算值就显得偏小了。
”,也就是说7月份中可能有大部分人都是狮子座,这时候oracle对选择率的估算值就显得偏小了。
下面我们就在这张表相关的列上收集扩展统计信息:
select dbms_stats.create_extended_stats(ownname => 'CBO' , tabname => 'T' , extension => '(c1,c2,c3)' ) from dual ; exec dbms_stats.gather_table_stats(null,'T', method_opt => 'for columns SYS_STUX7RKLWBB89JLF$Z7_$342Y_ size 2' ); |
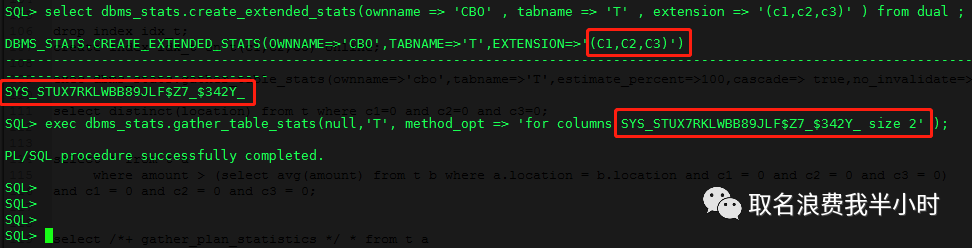
收集完扩展统计信息之后,我们再次执行这条sql,观察执行计划的变化:
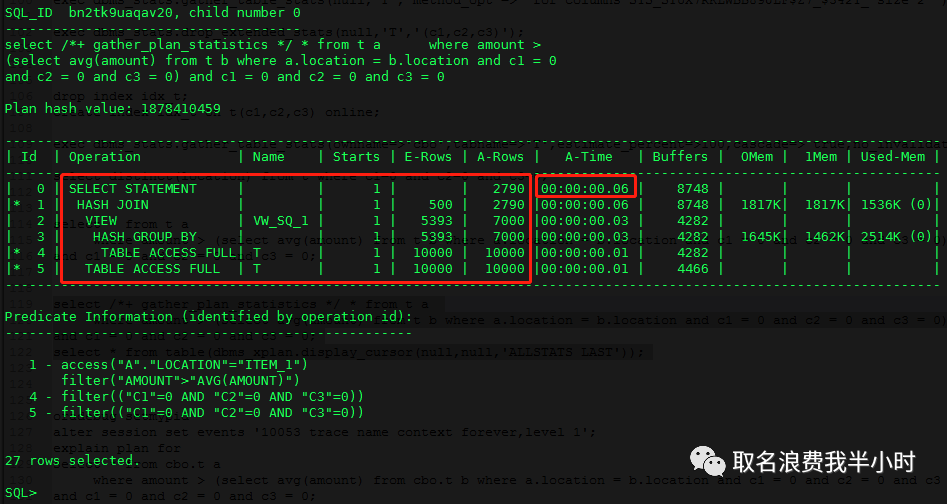
这条sql从原来执行需要5分多钟,变成了0.05秒,执行计划从filter变成了hash join,可以看到oracle这次将sql语句中的select avg(amount) from t b where a.location = b.location and c1 = 0 and c2 = 0 and c3 = 0部分拆开成一个view再和外部查询做关联,走hash join。这时候我就在想其实就算不收集扩展统计信息,oracle要是选择这样的执行计划,肯定效率会更好啊,那么又是什么原因导致oracle最开始的时候,没有做视图合并,而选择了一个效率很差的filter呢?
带着这个疑问,我们继续探究,现在将刚刚收集的扩展统计信息删除,重新跑一下这条sql,这次我们收集一个10053:
exec dbms_stats.drop_extended_stats(null,'T','(c1,c2,c3)'); |
oradebug setmypid alter session set events '10053 trace name context forever,level 1'; explain plan for select * from cbo.t a where amount > (select avg(amount) from cbo.t b where a.location = b.location and c1 = 0 and c2 = 0 and c3 = 0) and c1 = 0 and c2 = 0 and c3 = 0; alter session set events '10053 trace name context off'; oradebug tracefile_name; vi u01/app/oracle/diag/rdbms/ces/ces/trace/ces_ora_122139.trc |
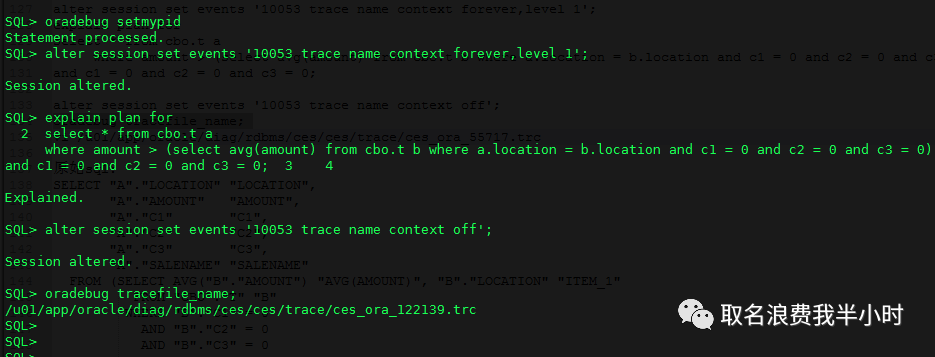
下面就是10053trace中的关键信息:
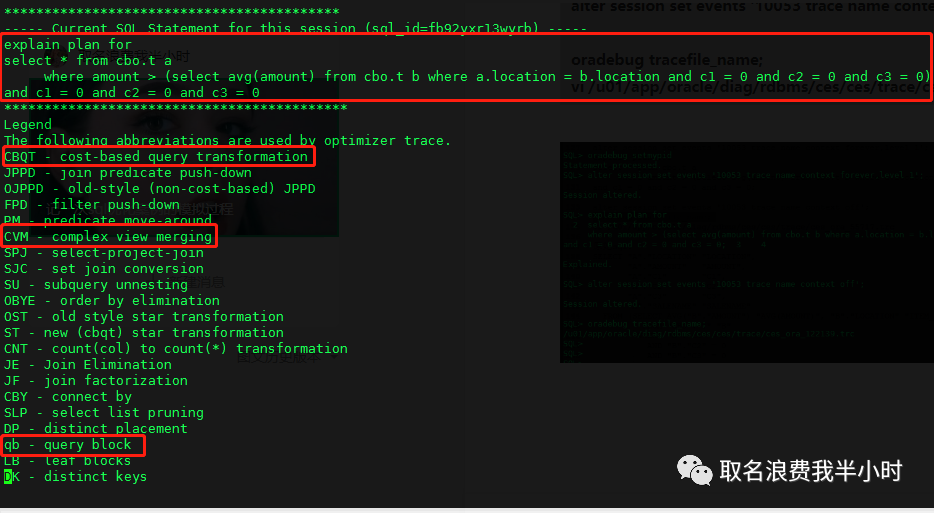
可以看到我们刚刚执行的这条sql,以及一些一会将会用到的英文简写的含义。
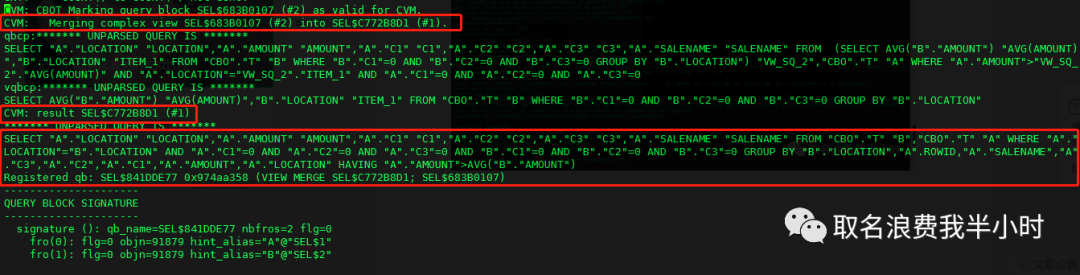
这里可以看到对于我们执行的sql语句,在oracle眼里他其实看起来很奇怪,全都加了双引号,并且这里做了CVM(复杂视图合并)改写之后的sql语句也打印了出来,我们格式化来看一下:(由于子查询里有avg聚合函数所以该视图被称为复杂视图)
SELECT "A"."LOCATION" "LOCATION", "A"."AMOUNT" "AMOUNT", "A"."C1" "C1", "A"."C2" "C2", "A"."C3" "C3", "A"."SALENAME" "SALENAME" FROM "CBO"."T" "B", "CBO"."T" "A" WHERE "A"."LOCATION" = "B"."LOCATION" AND "A"."C1" = 0 AND "A"."C2" = 0 AND "A"."C3" = 0 AND "B"."C1" = 0 AND "B"."C2" = 0 AND "B"."C3" = 0 GROUP BY "B"."LOCATION", "A".ROWID, "A"."SALENAME", "A"."C3", "A"."C2", "A"."C1", "A"."AMOUNT", "A"."LOCATION" HAVING "A"."AMOUNT" > AVG("B"."AMOUNT"); |
其实在oracle对这条sql进行CVM改写之后,其执行计划正是我们收集扩展统计信息之后的执行计划,我们继续从10053的trace这种寻找线索:

可以看到在经过CVM改写之后这条sql最好的执行计划对应的cost算出来是1896.2281。

而如果不做CVM改写这条sql的最好的执行计划对应的cost算出来的是1895.1907。
由于CVM(复杂视图合并)是基于成本的(CBQT)所以在经过CBO的一番计算之后,势必会选择一个最小的cost,导致了最终oracle在执行这条sql的时候,并没有做CVM,但是这个计算错误的根因是最开始的那个执行计划中第二步的选择率计算错了。到目前为止我们知道了为什么oracle一开始选择走filter那个效率不佳的执行计划了。
既然oracle CBO是因为选择率计算错误而错误的评估了CVM前后的cost值,这也就解释了为什么我们在收集了c1 c2 c3三列的扩展统计信息之后,oracle就走了更好的执行计划,因为收集扩展统计信息之后,CBO对选择率的计算更准确了。前面我们已经将收集的扩展统计信息删除了,我们保持这一点不变,尝试在这条sql上使用hint,让oracle强制做CVM,看看会如何?
select *+ gather_plan_statistics */ * from t a where amount > (select *+ unnest*/avg(amount) from t b where a.location = b.location and c1 = 0 and c2 = 0 and c3 = 0) and c1 = 0 and c2 = 0 and c3 = 0; select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); |
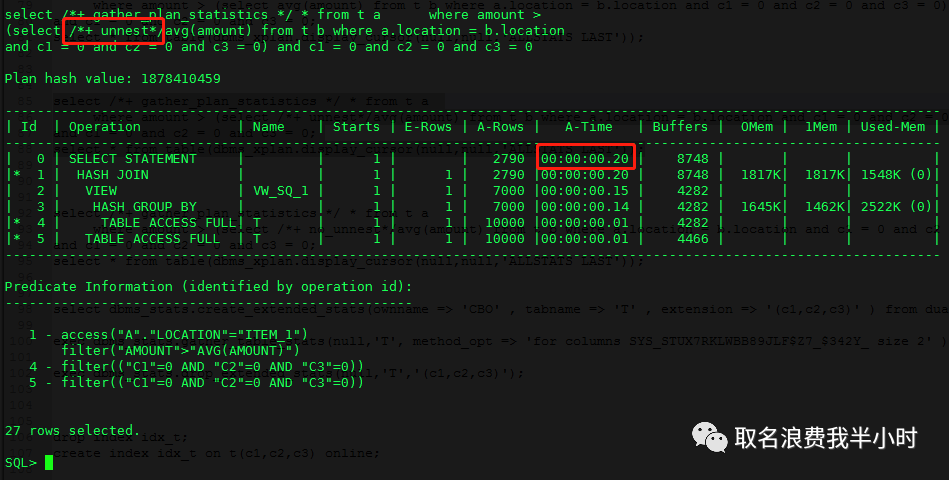
可以看到使用unnest hint之后的执行计划基本和收集扩展统计信息之后的执行计划是一致的,执行时间仅需0.2秒。
那么除了这两种优化方式,还有别的方法吗?有的。
还记得最开始的那个执行计划吗?再贴一次:
执行计划第2步第4步都是全表扫描,那很容易就能想到如果我们在c1 c2 c3列上创建索引,会对sql的执行起到怎么的作用呢?
create index idx_t on t(c1,c2,c3) online; exec dbms_stats.gather_table_stats(ownname=>'cbo',tabname=>'T',estimate_percent=>100,cascade=> true,no_invalidate=> false); |
现在我们再次执行该sql(不收集扩展统计信息,不加hint):
select *+ gather_plan_statistics */ * from t a where amount > (select avg(amount) from t b where a.location = b.location and c1 = 0 and c2 = 0 and c3 = 0) and c1 = 0 and c2 = 0 and c3 = 0; select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS LAST')); |
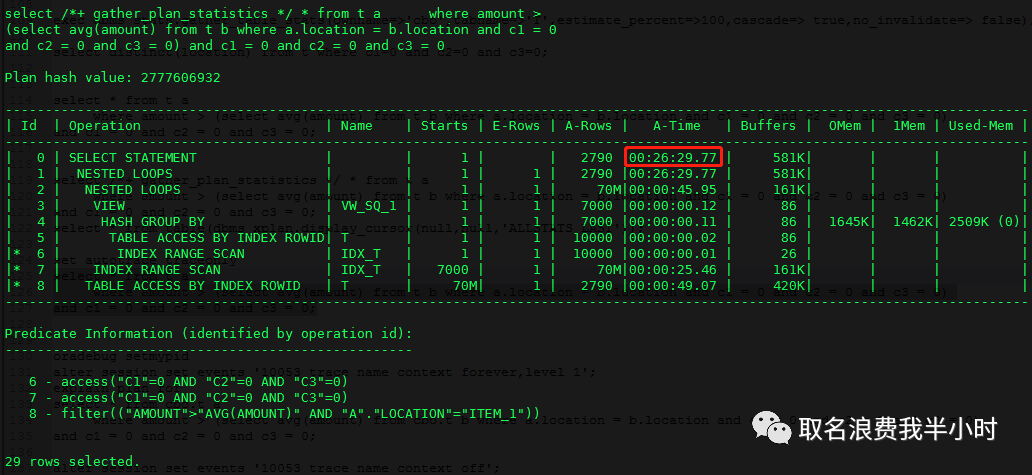
这里很奇怪啊,这里显示的真实执行时间竟然是28分钟,我也没搞清楚是什么情况,我们换种方式查看:
set timing on set autotrace traceonly select * from t a where amount > (select avg(amount) from t b where a.location = b.location and c1 = 0 and c2 = 0 and c3 = 0) and c1 = 0 and c2 = 0 and c3 = 0; |

44秒执行完成。
现在我们回顾一下,对于最开始那条有“性能问题”的sql语句,到目前为止我们已经有了三个解决方案:
在c1 c2 c3上收集 extended stats 5分多钟---0.05秒 加unnest的hint 5分多钟---0.2秒 在c1 c2 c3上创建复合索引 5分多钟---44秒
以上我们分别测试了,只收集扩展统计信息,只加hint,只创建复合索引,接下来我们将这三种方式分别组合起来看看有什么效果:
收集扩展统计信息+创建复合索引:
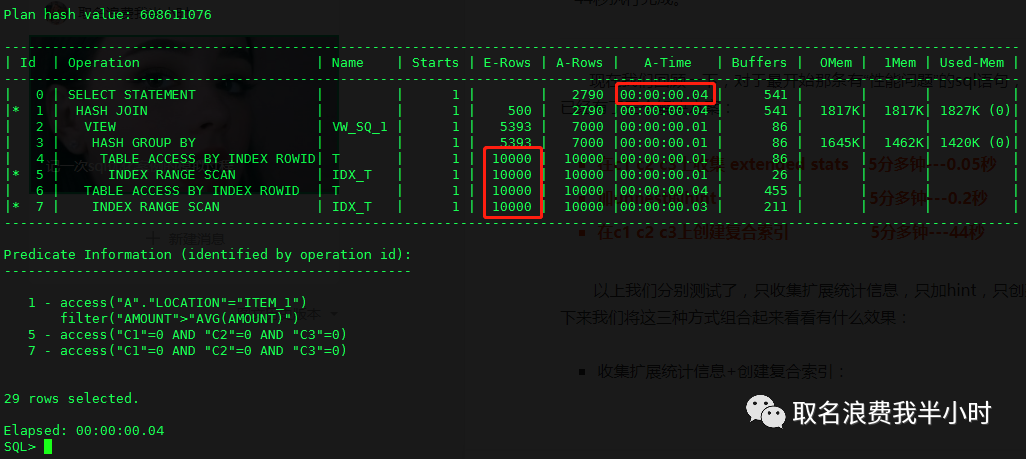
可以看到执行时间为0.04秒,效率提升了0.01秒,当然这样的提升是可以忽略的。
收集扩展统计信息+加强制CVM的hint:
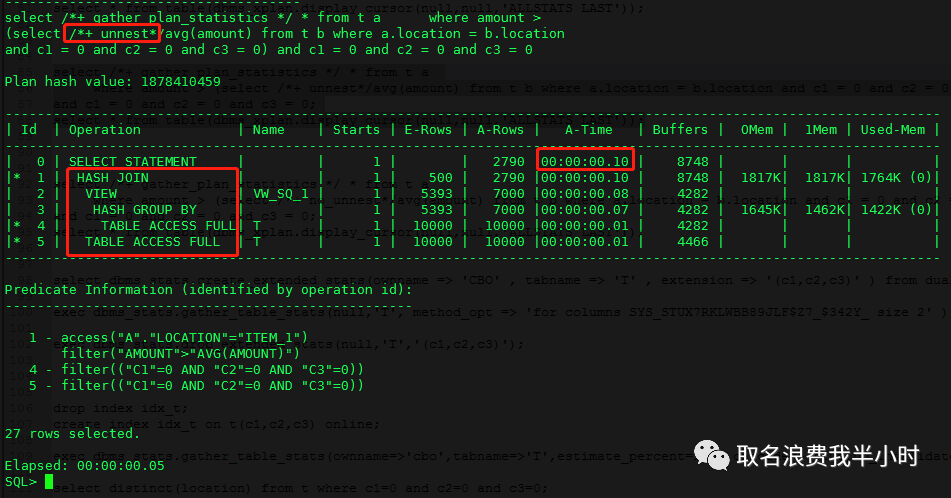
执行时间0.1秒。
收集扩展统计信息+加禁止CVM的hint:
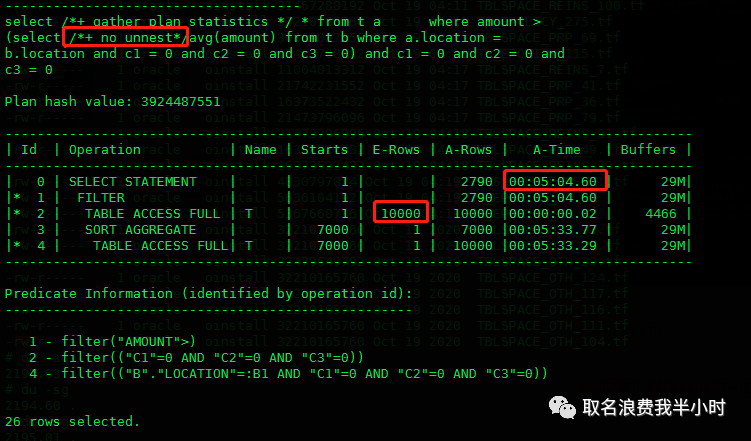
可以看到执行时间为5分多钟,并且因为收集了扩展统计信息,第二步评估的行数变准确了。
收集扩展统计信息+加强制CVM的hint+创建复合索引
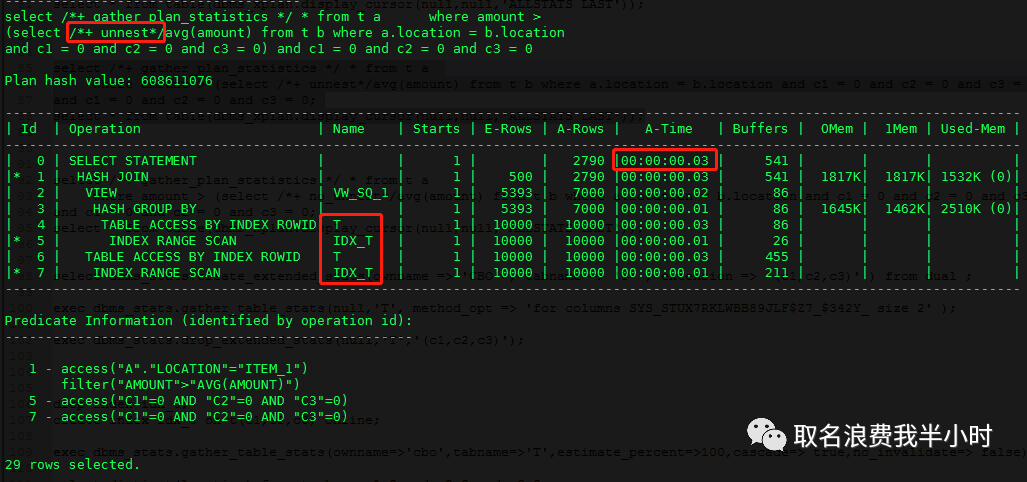
执行时间为0.03秒。
现在问题来了,原本一条执行需要5分多钟的sql语句,在经过我们采取各种不同的优化方式之后,执行时间分别变成了44秒、0.2秒、0.1秒、0.05秒、0.04秒、0.03秒。那么我们是不是就一定要采用执行时间为0.03秒的这种优化方案吗?(收集扩展统计信息+加强制CVM的hint+创建复合索引)
其实我觉得不是,主要原因倒不是因为最后的0.0几秒的提升少到可以忽略,而是我们在做优化的时候,眼光不能仅仅局限于当前的这一条sql,想象一下,如果加了索引,那么对于insert时的影响我们是不知道的,还需要额外的去维护一个索引;加强制CVM的hint,那如果下次出现了同类型的sql呢?可能条件变成了c1 =1 c2 =1 c3 =1,那是不是就需要继续在sql上加hint?如果同类型的sql有1000条呢?都要加hint?如果以后数据库迁移了或者升级了,hint失效了,又要怎么办呢?所以我们应该从众多的优化方案中选出一个“最好的”,而这个最好的优化方案可以不是执行时间最短的,就好比这个例子中的收集扩展统计信息,我们只需要收集一次,就解决了所有同类型sql的性能问题,并且以后数据库迁移了升级了也不会受到影响,实现了以最少的变动,解决尽可能多的问题。
