





引言

数据库架构发展主要阶段
基于SMP架构数据库
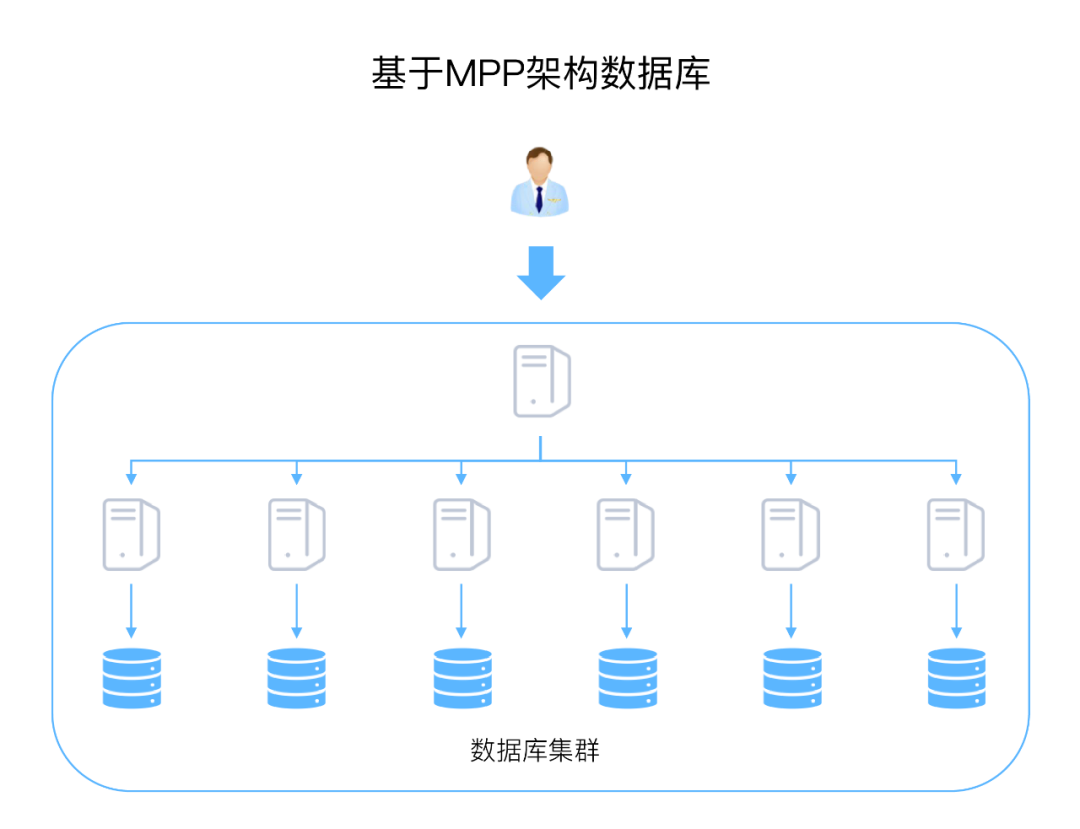
基于MPP架构数据库
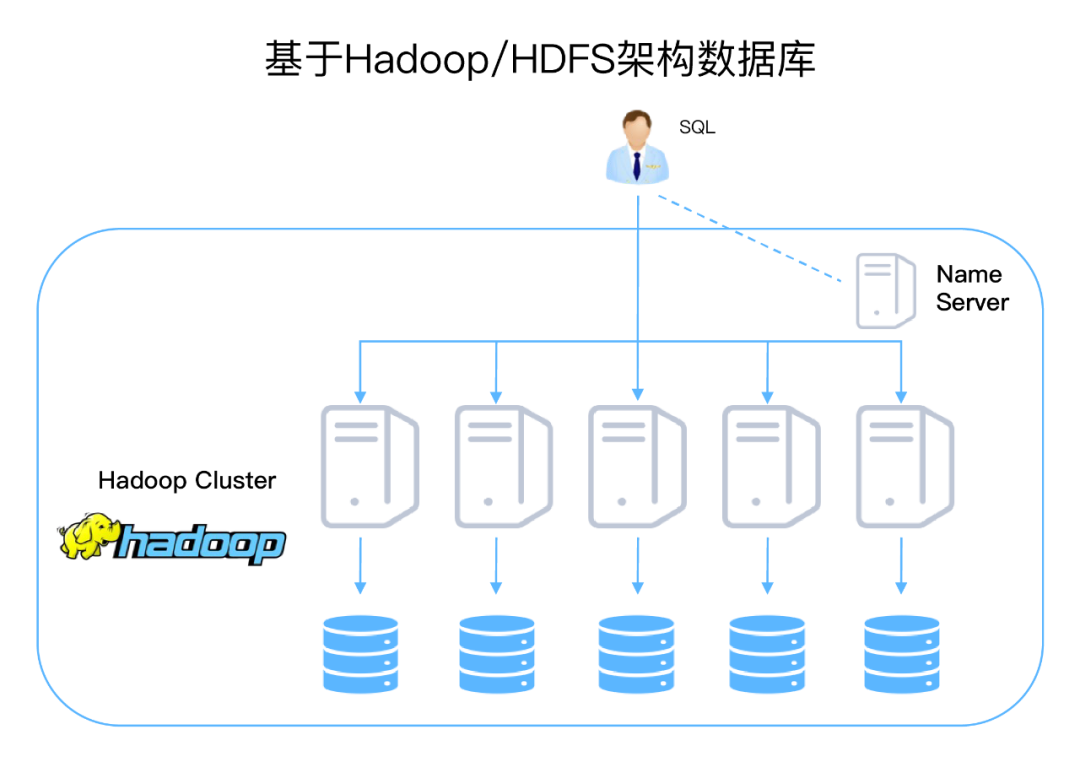
基于Hadoop/HDFS架构数据库
基于云原生架构数据库
接下来,我们将对以上几种数据库架构的特点逐一进行解读。

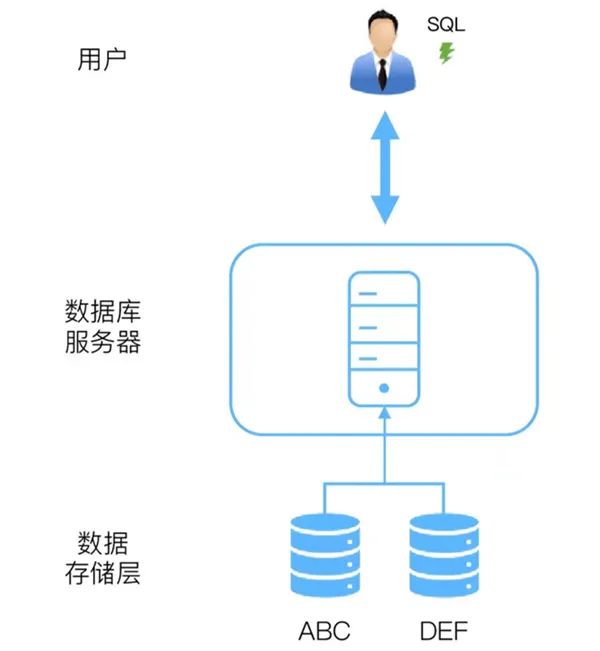
自20世纪80年代初以来,数据库市场一直由Oracle、Microsoft和IBM主导,他们提供了满足当时用户的通用解决方案,其底层硬件和数据库系统架构是在20世纪70年代开发的,使用的是对称多处理(Symmetrical Multi-Processing,SMP)架构,核心原理是多处理器共享统一的内存和磁盘等,应用场景以单机为主。
成本和性能:SMP架构是经过验证的成熟体系结构,产品部署成本相对较低,其性能和吞吐量有一定的保证。
部署方式:SMP架构数据库几乎可以在任何硬件上运行,包括大型服务器和中型商用硬件,还可以运行在云平台的虚拟服务器。SMP架构基于多核,支持物理核和虚拟核。
数据一致性:下图展示了SMP架构的数据库基本特性,即直接连接到本地或者网络磁盘的单台计算机。实际上,SMP架构数据存在一份副本,因此可以保证数据一致性,这与许多NoSQL解决方案相比较存在一定的优势。
可扩展性不足:SMP架构虽然可以通过增加服务器配置进行扩展,但是实际上可扩展性十分有限,单纯的增加服务器配置未必可以线性提高性能,同时也带来较高的人力物力成本。
资源浪费:由于SMP架构可扩展性不足,因此很多项目在最初规划时候,一步到位最大化地部署资源,以此保证规划的资源足以满足一定期限内的需求,这种超前配置在项目前期造成了资源浪费。
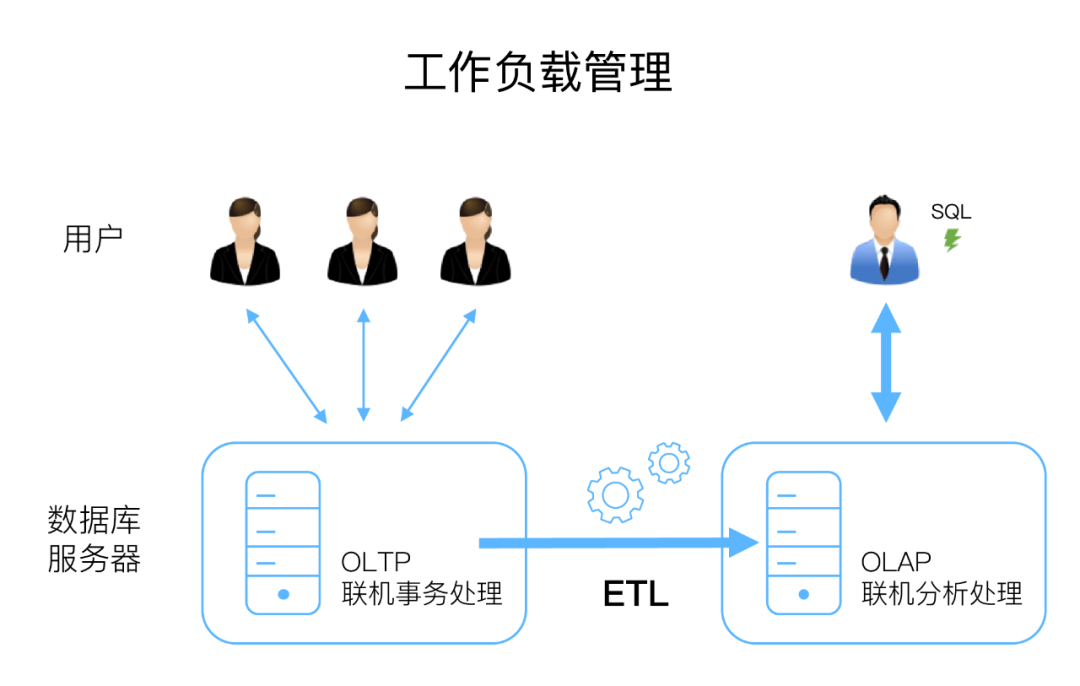
工作负载管理:基于SMP架构的数据库,由于架构的特殊性,很难同时满足快速响应和高吞吐量的需求。下图说明了一种常见的方案,即面向客户的在线事务处理(OLTP)系统可以提供快速响应时间,同时该系统定期将数据同步到单独的联机分析处理(OLAP)数据仓库平台。
弹性和可用性:由于SMP架构使用的是单一的平台,因此为了提供弹性和可用性,需要部署一套单独的备用数据库,整体而言,代价较大。
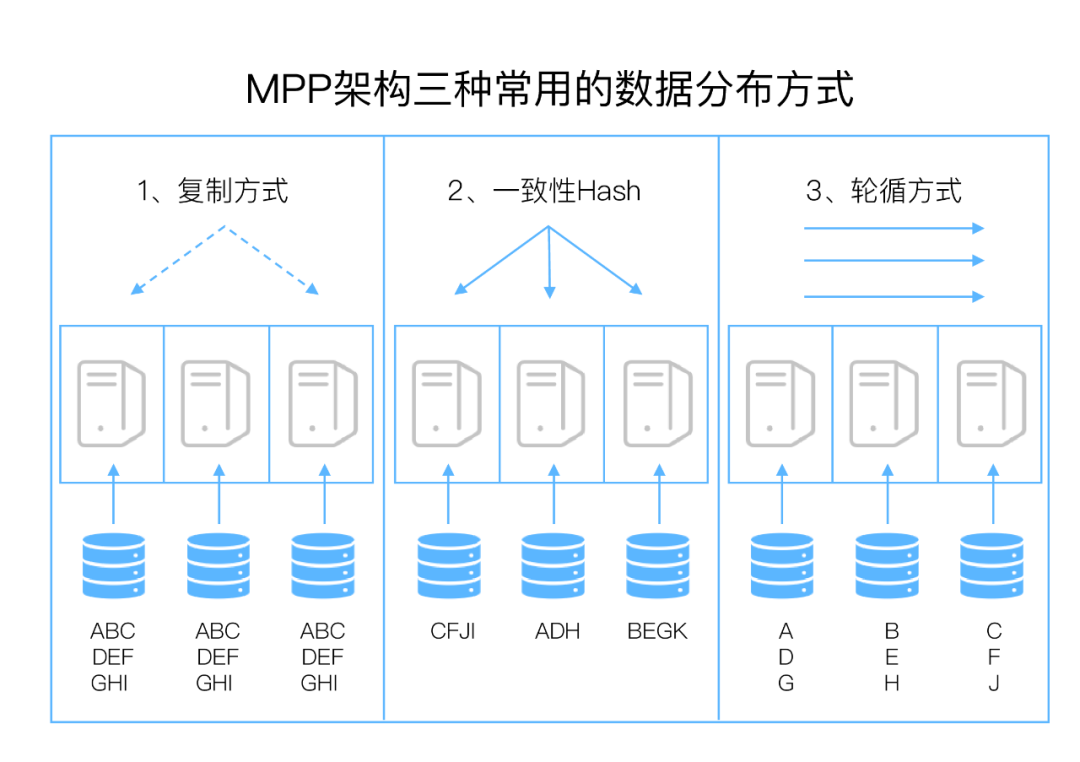
复制方式:通常用于较小的表,采用此方式分布数据,在每个节点上都重复着所有数据,存在一定的浪费。此方式在维度表时可以考虑,因为维度表通常需要与一个数据量大的事实表进行关联,这样就类似在集群的每个节点的本地磁盘进行关联计算,从而避免了跨节点的数据转移。
一致性Hash:通常适用于较大的事实表,主要是通过一定方式生成键值,将每一行记录分配到相应的服务器上,此方式可以保证数据均匀分配,但是如果键值生成方式不恰当,导致节点数据分布不均匀,会影响整体性能。
轮循方式:此方式主要是以循环方式依次对将数据依次写入节点中,这种方式适合临时层的表,这些表通常只被读写一次。它的优点是能保证数据均匀分布。使用此方式,需要将所有的表轮循分配到所有的节点,否则整体性能会比较差。
性能:由于数据分散在不同的节点上,节点是使用独立的资源,节点之间性能隔离,每个节点执行一部分计算任务,并行处理,可以提高整体执行性能。
可扩展性和并发性:MPP架构可以通过横向扩展服务器节点数,提升处理能力。基于MPP架构的计算能力,可以支持多用户同时访问数据库。
低成本的高可用:一些MPP架构的数据库在廉价的商用硬件上运行,数据通过副本提供冗余保护,自动故障探测和管理,自动同步元数据和业务数据,这样可以有效地利用资源,相比于SMP架构的冗余设备,成本有所降低。
读写吞吐量:由于读写操作可以在集群的不同计算节点上并行执行,因此可以实现高吞吐量。
成本高:MPP架构的复杂性较高,TeraData和Netezza为最早的MPP数据库产品,使用一体机架构,使得用户的成本居高不下。
数据分布方式至关重要:MPP架构,如果数据分布方式不恰当,会引起某些节点计算过载而部分节点闲置,这将直接影响数据库的吞吐量和查询响应时间。如果没有正确选择表关联字段作为数据分布字段,在执行关联时候,会导致节点之间过多的数据交换,也会引发性能问题。下图展示了数据在不同节点之间的交换。
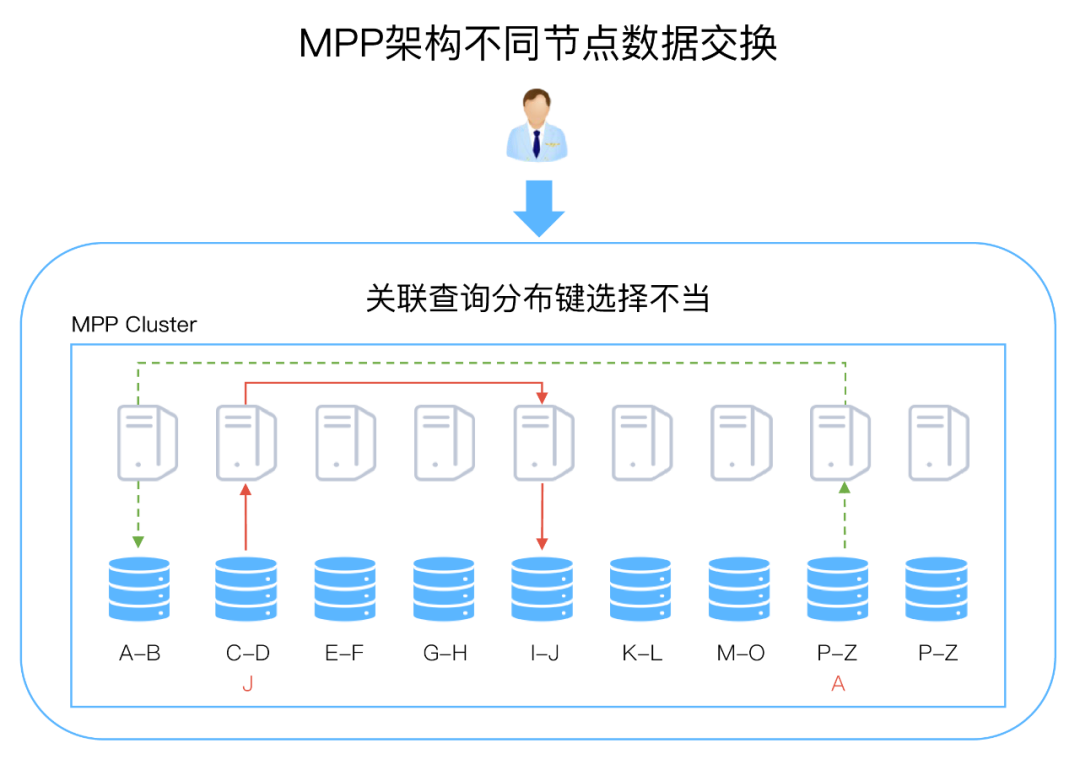
扩缩容复杂:MPP架构的数据库、计算和存储是紧耦合的,如果需要扩缩容,需要对数据重新分布,这样会严重影响数据库的性能,甚至需要停机。
只支持横向扩展:MPP架构计算和存储是紧耦合的,所以只支持横向扩展,通过增加节点方式进行扩展。
资源浪费:由于计算和存储紧耦合,无法单独增加计算资源或者存储资源,在增加存储的同时,需要增加计算资源,势必造成资源的浪费。

Hadoop是一个庞大的处理平台,它解决的主要问题包括:
大容量数据存储和批处理:Hadoop和HDFS通常被用于廉价的数据存储和数据湖构建平台。由于它能扩展到数千个节点,因此它非常适合大规模批量数据处理。
实时处理:HDFS适合运行大批量数据,其他组件,例如Kafka、Spark Streaming、Storm以及Flink,专门用于提供微批或者实时流式数据处理。随着物联网行业的发展,需要提供越来越多的实时或准实时结果,Hadoop的实时处理能力越来越突出。
文本挖掘和分析:Hadoop平台能够处理包括文本在内的非结构化数据,这极大不同于传统的数据库适用于行和列中的结构化数据。
批处理性能:针对大数据量处理,Hadoop利用多个节点并行处理的方式,可以实现高吞吐量。
可扩展性:Hadoop可以通过增加节点方式扩展集群规模,集群规模可达数千个节点。
可用性和弹性:Hadoop数据存储在HDFS上,可以自动进行数据的多份备份,任务失败后能自动重新部署计算任务。
成本:Hadoop是开源的,其软件成本不高,并且对硬件的要求也不高,可以使用廉价、通用的服务器,所以Hadoop整体成本比较低。
管理复杂:Hadoop不是单一产品,而是一个庞大的软件生态系统,部署通常需要熟练掌握一系列工具,包括HDFS,Yarn,Spark,Impala,Hive,Flume,Zookeeper和Kafka等等。
无法高效存储大量的小文件:因为NameNode把文件系统的元数据放置内存中,所以文件系统所能容纳的文件数目是由NameNode的内存大小决定的。如果小文件过多,会引起文件系统的元数据量增多,过多地占用NameNode的内存。
低延迟数据访问受限:HDFS主要是为了处理大型数据集分析任务,达到高数据吞吐量而设计的,这就带来了高延迟作为代价。
数据交换:与MPP架构不同,Hadoop无法将数据分布到节点上。在进行表关联时候,可能存在大量的数据交换,因此存在验证的性能问题。
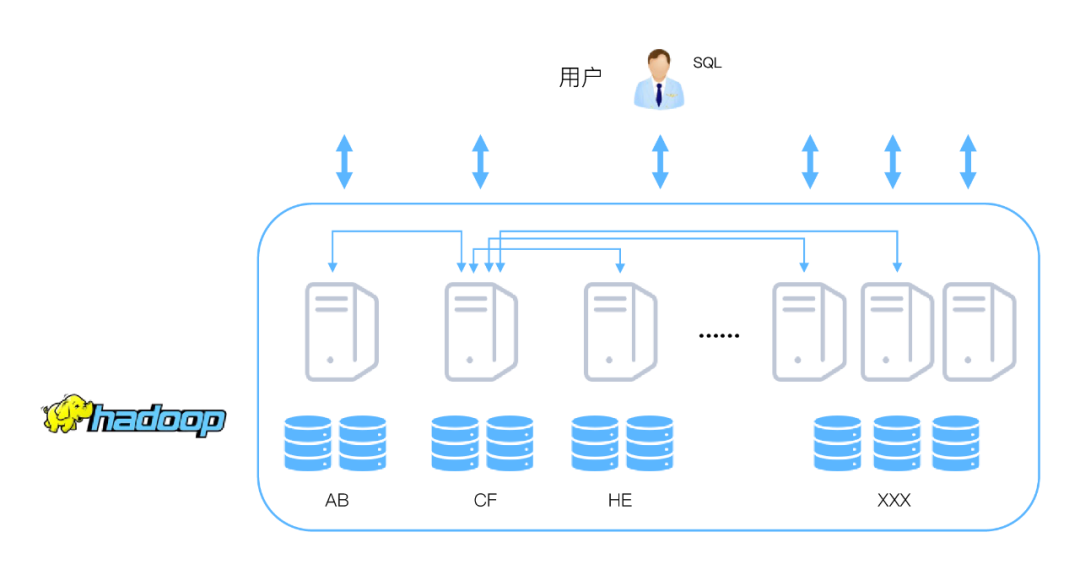
不支持多用户写入及任意修改文件:在HDFS文件中只能有一个写入者,而且写操作只能在文件末尾完成,即只能追加操作,目前还不支持多个用户对同一个文件的写操作以及在文件任意位置进行修改。
其他缺点:与MPP架构类似,Hadoop/HDFS架构可扩展性差,在构建数据湖时候存在资源浪费。
为了解决MPP架构存储和计算紧耦合问题,行业内出现了云原生架构数据库,其核心是充分发挥云基础设施带来的各种资源弹性的优势,通过将计算和存储分离,提高数据库资源配置效率,实现计算和存储弹性扩展,按需分配,为客户带来超高的ROI。
与传统数据仓库相比,云原生数仓围绕着对象存储和抽象服务构建,通过融合大规模并行处理数据库优异的SQL功能和性能、Hadoop/Spark计算存储分离理念,以及云计算的弹性和扩展性,帮助企业客户轻松应对数据仓库、数据湖以及数据共享实施中面临的各种挑战。
以Snowflake为例,它能够启动多个独立的计算资源集群,每个集群的大小和操作都是独立的,可以从公共数据存储中加载和查询数据。Snowflake可以部署多个独立的计算资源集群,这意味着用户可以在批量加载数据的表上进行数据科学操作,同时为用户提供亚秒级响应时间。
在国内,HashData是最早进入云原生数仓赛道的厂商,其技术架构如下图所示:
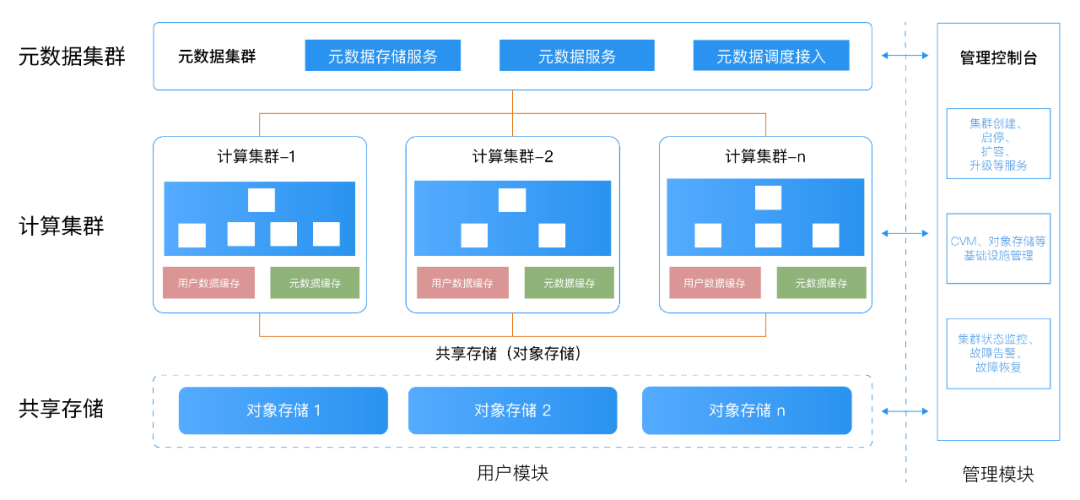
可扩展性和并发性:云原生架构能够轻松实现集群扩展,通过增加计算节点来运行更高的工作负载,也可以通过添加计算集群来实现高并发以支持更多的用户访问。
低成本和高可用性:云原生架构可以本地部署或者云环境部署,无论是哪种部署方式,都可以实现故障自愈的高可用。部署在云环境的用户可以按需的关闭或者挂起暂时不用的数据库,以控制成本,待需要时候再重启。此外,服务、计算、存储层的解耦设计,方便精准地按需增减资源,降低了使用成本。
接近零停机时间:与MPP架构不同,云原生架构在对集群进行扩容或者缩容、增加或者减少单节点计算资源都不需要停机,用户可以正常使用数据库。
多维度扩展:MPP架构仅支持横向扩展(Scale Out),云原生架构可以独立地扩展计算和存储,还可以按需增加和减少吞吐量。如下图所示,云原生架构可以通过扩展存储以保存日益增长的数据量,可以在用户数量增加时通过增加计算集群的数量以达到高吞吐量,还可以通过增加计算节点数量以实现快速响应,从而实现吞吐量、数据容量和响应时间这三个围度上的完全弹性。
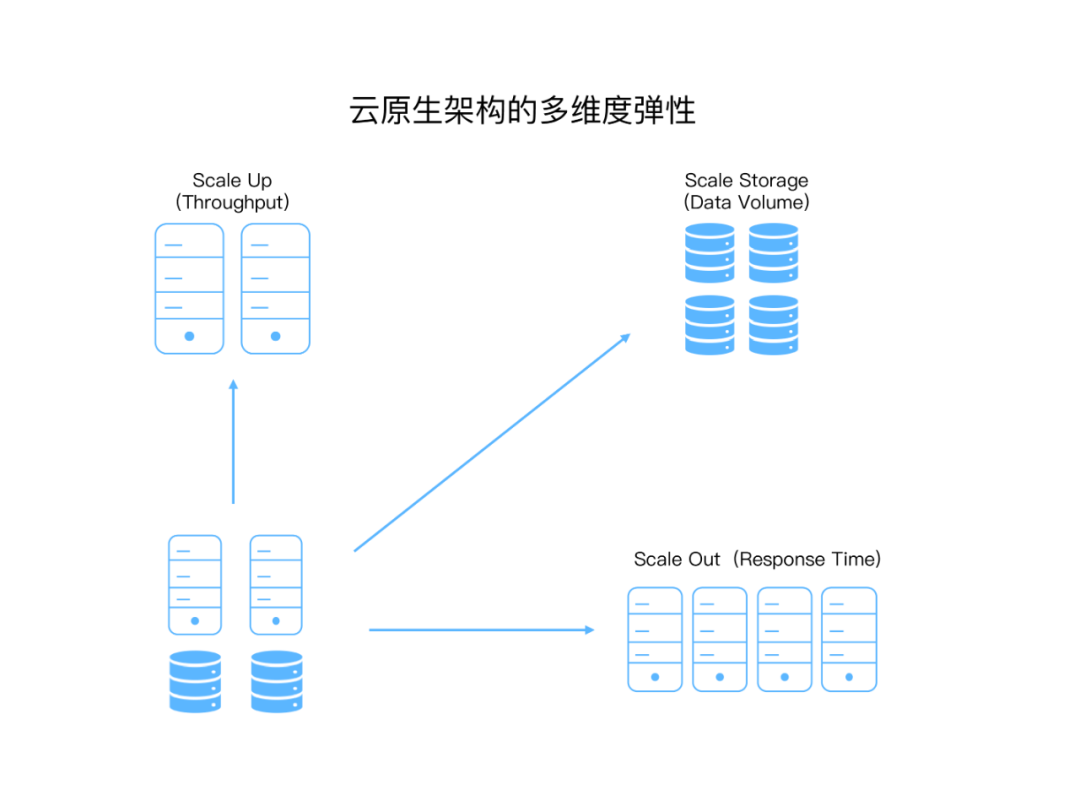
更合理的硬件配置:与SMP架构和MPP架构不同,云原生架构可以根据业务的实际需求选择最合理的计算和存储资源的配置关系,这意味着可以用小型计算集群处理PB级数据,或者在较小的数据集上运行强大的计算集群,从而更好的满足不同业务类型的数据处理需求,大幅提高硬件资源利用效率。
结束语
END
