




Hi~朋友,关注置顶防止错过消息
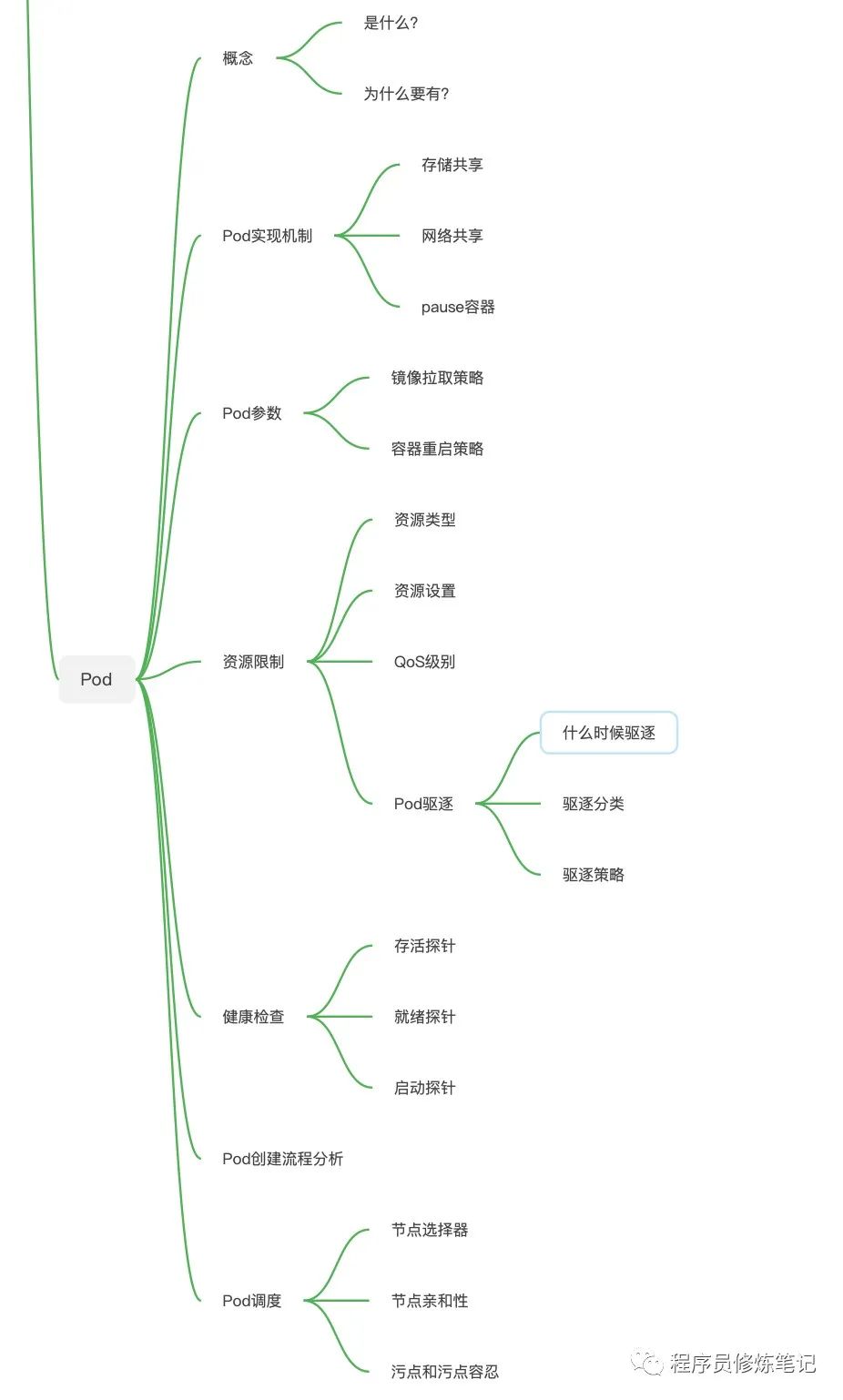
由于本文篇幅过大,下图是本文涵盖的一些内容,方便大家从总到分的进行理解和学习:
为什么要有Pod
Pod是什么?
Pod是Kubernetes集群中最小的调度单位,具有以下特点:
Kuberenetes集群中最小的部署单位 一个Pod中可以拥有多个容器 同一个Pod共享网络和存储 每一个Pod都会有一个Pause容器 Pod的生命周期只跟Pause容器一致,与其他应用容器无关
为什么要有Pod的存在?
容器不具备处理多进程的能力 很多应用程序相互之间并不是独立运行的,有着密切的协作关系,必须部署在一个节点上
Pod共享机制
Pod实现机制?
Pod中可以共享网络,并且可以声明共享存储。
共享存储是通过数据卷Volume的方式进行共享,该Volume可以定义在Pod级别,在容器中进行挂载即可实现共享 共享网络是通过共享Network Namespace的方式进行的,具体的方式是通过一个称为Pause容器来实现的
Pause容器的作用?
Pod中通过共享Network Namespace的方式进行网络的共享,但是如果是以下方式进行Network Namespace共享会有问题:
# A容器共享B容器的网络$ docker run --net=B --volumes-from=B --name=A image-A ...
上述的方式我们是通过A容器共享了B容器的网络,本质上是A加入到了B的Network Namespace中,但是这种方式需要容器B必须先于A启动。
为了解决应用容器的上述启动顺序问题,Kubernetes引入了一个中间容器,叫Pause容器(或称Infra容器),Pause容器是Pod中第一个被创建的容器,其他用户容器都会以Join Network Namespace的方式与Pause容器关联起来,实现同一个Pod中所有容器共享网络。
共享存储示例
apiVersion: v1kind: Podmetadata: labels: run: busybox name: busyboxspec: containers: - image: busybox name: busybox-write command: ["/bin/sh"] args: ["-c", "while true; do date >> /data/result.txt; sleep 5; done;"] # 容器内挂载数据卷 volumeMounts: - name: data # 容器内目录 mountPath: /data - image: busybox name: busybox-read command: ["/bin/sh"] args: ["-c", "while true; do date; sleep 10; done;"] # 容器内挂载数据卷 volumeMounts: - name: data # 容器内目录 mountPath: /data # 定义共享数据卷 volumes: - name: data emptyDir: {}
spec.volumes字段我们定义了整个Pod共享的数据卷 spec.containers.volumeMounts字段用来挂载数据卷
创建POD$ kubect apply -f 001.yaml进入只读容器busybox-read查看文件,如果共享存储是对的,我们可以在只读容器/data找到result.txt文件$ kubectl exec busybox -c busybox-read -i -t -- sh -il$ tail -f -n 10 /data/result.txt
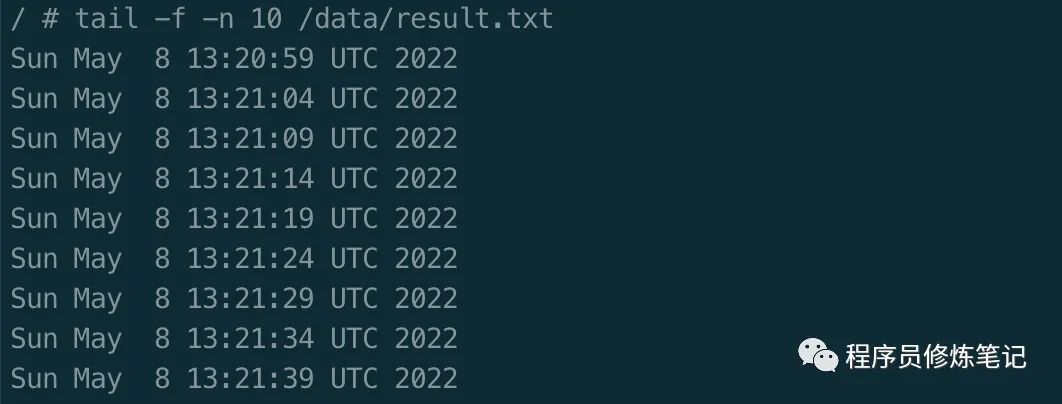
可以看到/data/result.txt每5s中会多一行,这是因为我们的busybox-write每5s中往该容器写入时间,通过数据卷volume我们实现了同一个Pod内容器的存储共享。
Pod参数
Pod镜像拉取策略
Pod镜像拉取策略是定义在容器级别的,由spec.containers.imagePullPolicy定义,如下:
apiVersion: v1kind: Podmetadata: name: busyboxspec: containers: - image: busybox # 定义镜像拉取策略 imagePullPolicy: Always name: busybox-write
imagePullPolicy默认值为Always,目前主要有三种字段:
Always:每次创建Pod都需要重新拉取镜像 Never:永远不会主动拉取镜像 IfNotPresent:Pod所在的宿主机上不存在这个镜像时拉取
当容器的镜像是类似busybox或者busybox:latest这样的名字时,imagePullPolicy会被认为Always。
Pod容器重启策略
apiVersion: v1kind: Podmetadata: name: busyboxspec: # 重启策略 restartPolicy: Always containers: - image: busybox name: busybox-write
容器的重启策略定义在Pod级别,字段为spec.restartPolicy,该字段有以下值:
Always: 当容器失效时,由Kubelet自动重启容器 OnFailure:当容器终止运行且退出码不为0时,由Kubelet自动重启该容器 Never:不论容器运行状态如何,都不会重启容器
Pod资源限制
Kubernetes对Pod进行调度的时候,我们可以对Pod进行一些定义,来干涉调度器Scheduler的分配逻辑。
资源类型
在Kubernetes中,资源类型有以下两种:
可压缩资源:此类资源不足时,Pod只会饥饿,不会退出,比如CPU 不可压缩资源:此类资源不足时,Pod会被内核杀掉,比如内存
资源配置
CPU和内存资源的限额定义都在container级别,Pod整体资源的配置是由Container的配置值累加得到。
定义资源示例
apiVersion: v1kind: Podmetadata: name: busyboxspec: containers: - image: busybox name: busybox-write command: ["/bin/sh"] args: ["-c", "while true; do date >> /data/result.txt; sleep 5; done;"] resources: limits: cpu: "500m" memory: "50Mi" requests: cpu: "500m" memory: "10Mi"
Pod中的资源限制如上述文件所示,还要分为两类:
requests:kube-scheduler在进行调度的时候会按照该值去检查Kubernetes的node是否符合要求 limits:Pod在实际运行时能够使用到的资源上限(真正设置Cgroups限制的时候)
$ free -h

通过上图我们可以看到我们的node-1节点内存大小为1.9Gi,我们把resources.limits.memory和resources.requests.memory设置成2.0Gi。
apiVersion: v1kind: Podmetadata: name: busyboxspec: containers: - image: busybox name: busybox-write command: ["/bin/sh"] args: ["-c", "while true; do date >> /data/result.txt; sleep 5; done;"] resources: limits: cpu: "500m" memory: "2.0Gi" requests: cpu: "500m" memory: "2.0Gi"
$ kubectl apply -f 001.yaml$ kubectl get pods -o wide$ kubectl describe pod busybox


通过上图可以看出,buxbox的Pod没有被调度到任何节点,一直处于Pending状态,然后通过查看pod的Event可以看出原因:一共有两个节点,其中1个节点(master)被打上了不允许调度的污点,另一个节点1个(k8s-node-01)内存资源不足,因此Pod不能被成功调度。
Pod QoS类别的划分?
Guaranteed类别:Pod中的每一个container中都设置了相同的requests和limit Burstable类别:不满足Guaranteed类别,但Pod中至少一个containers设置了requests BestEffort类别:Pod中没有设置requests和limits
为什么要进行Pod QoS划分?
QoS主要用来,当宿主机资源发生紧张时,Kubelet对Pod进行Eviction(资源回收)时需要使用。
什么情况会触发Eviction?
Kubernetes管理的宿主机上的不可压缩资源短缺时,将有可能触发Eviction,常见有以下几种:
可用内存(memory.avaliable):可用内存低于阀值,默认阀值100Mi 可用磁盘空间(nodefs.avaliable):可用空间低于阀值,默认阀值10% 可用磁盘空间(nodefs.inodesFree):linux节点,可用空间低于阀值,默认阀值5% 容器运行时镜像存储空间(imagefs.available):可用空间低于阀值,默认阀值15%
上述阀值也可以通过以下命令进行修改
--eviction-hard 指定Hard Eviction--eviction-soft、--eviction-soft-grace-period和--eviction-max-pod-grace-period共同指定了Soft Eviction$ kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% --eviction-soft=imagefs.available<30%,nodefs.available<10% --eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m --eviction-max-pod-grace-period=600
Hard Eviction和Soft Eviction的区别?
Hard Eviction:Eviction在达到阀值时会立即进行资源回收 Soft Eviction:Eviction在达到阀值时会等待一段时间才开始进行Pod驱逐,该时间由eviction-soft-grace-period和eviction-max-pod-grace-period中的最小值决定
Eviction对Pod驱逐的策略是什么?
当Eviction被触发以后,Kubelet将会挑选Pod进行删除,如何挑选就需要参考QoS类别:
首先被删除的是BestEffort类别的Pod 其次是属于Burstable类别,并且发生饥饿的资源使用量超过了requests的Pod 最后是Guaranteed类别,Guaranteed类别的Pod只有资源使用量超过了limits的限制或者宿主机处在内存紧张的时候才会被Eviction。
对于每一种QoS类别的Pod,Kubernetes还会按照Pod优先级进行Pod的选择
CPU限额m的设置是什么意思?
Kubernetes推荐将CPU限额设置为分数,500m指的是500 millicpu,也就是0.5个CPU,也就是会获得一个CPU一半的计算能力。
Pod健康检查
什么是健康检查?
Pod里面的容器可以定义一个健康检测的探针(Probe),Kubelet会根据这个Probe返回的信息决定这个容器的状态,而不是以容器是否运行为标志。健康检查是用来保证是否健康存活的重要机制。
通过健康检测和重启策略,Kubernetes会对有问题的容器进行重启。
探针探测的方式?
使用探针检测容器有四种不同的方式:
exec:容器内执行指定命令,如果命令退出时返回码为0则认为诊断成功 grpc:使用grpc进行远程调用,如果响应的状态为SERVING,则认为检查成功 httpGet:对容器的IP地址上指定端口和路径执行HTTP Get请求,如果状态响应码的值大于等于200且小于400,则认为检测成功 tcpSocket:对容器上的IP地址和端口进行TCP检查,如果端口打开,则检查成功
探测会有三种结果:
Success:通过检查 Failure:容器未通过诊断 Unknown:诊断失败,不会采取行动
探针类型?
Kubernetes中有三种探针:
livenessProbe:表示容器是否在运行,如果存活状态探针检测失败,kubelet会杀死容器,并根据重启策略restartPolicy来进行相应的容器操作,如果容器不提供存活探针,默认状态为Success readinessProbe:表示容器是否准备好提供服务,如果就绪探针检测失败,与该Pod相关的服务控制器会下掉该Pod的IP地址(比如Service服务) startupProbe:表示容器中的应用是否已经启动,如果启用该探针,其他探针会被禁用。如果启动探测失败,kubelet会杀死容器并根据重启策略进行重启
存活探针livenessProbe
apiVersion: v1kind: Podmetadata: name: liveness-execspec: containers: - name: liveness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600 # 存活探针 livenessProbe: exec: command: - cat - /tmp/healthy # 延迟探测,第一次探测需要等待5s initialDelaySeconds: 5 # 每隔5s进行一次探测 periodSeconds: 5
存活探针主要由几部分组成:
探针探测的方式:上面的例子中我们使用了exec的方式 initialDelaySeconds:延迟探测的时间,默认值0,最小值0 periodSeconds:探测的周期,默认值10,最小值1 timeoutSeconds:探测超时后等待多少s,默认值为1 successThreshold:探测器失败后,被认为成功的最小连续成功数,默认1,最小值为1,存活探测器和启动探测器这个值必须为1 failureThreshold:当探测失败时,Kubernetes的重试次数,默认值为3,最小值是1。对存活探测器来说,超过该次数会重启容器;对于就绪探测器来说,超过该次数Pod会被打上未就绪的标签
$ kubectl apply -f exec-liveness.yaml$ kubectl get pods -o wide$ kubectl describe pod liveness-exec


可以看到,在我们提交我们的YAML给Kuberenets以后,我们的Pod成功建立,并且容器成功启动,30s以后我们再查看应用Pod的Events,我们的健康检测会失败如下:

可以看到在30s以后,我们进行了三次存活探测都失败了,然后容器被杀掉重启。
就绪探针readinessProbe
有些应用在启动后需要加载大量配置文件或者数据,或者需要等待外部服务,此时我们并不想杀掉应用让其重启,而是不想给他发送请求,此时就可以用到就绪探针。
apiVersion: v1kind: Podmetadata: name: readiness-execspec: containers: - name: liveness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 20; rm -rf /tmp/healthy; sleep 600; # 就绪探针 readinessProbe: exec: command: - cat - /tmp/healthy # 延迟探测,第一次探测需要等待5s initialDelaySeconds: 5 # 每隔5s进行一次探测 periodSeconds: 5
$ kubectl apply -f exec-readiness.yaml$ kubectl get pods -o wide$ kubectl describe pod readiness-exec


通过上图可以看出,我们的readiness-exec的Pod成功启动并通过了健康检测并且容器也准备好接收数据(READY为1/1)。但在20s以后,我们再来观察我们的Pod,此时Pod的状态如下:


通过上图可以看出,Pod中的容器健康检测失败,同时容器就绪个数也变为0.
Pod创建流程
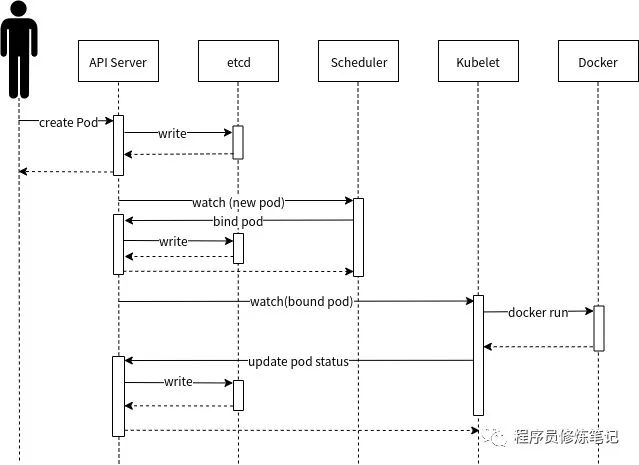
用户首先通过kubectl或其他的API Server客户端将Pod资源定义(也就是我们上面的YAML)提交给API Server API Server在收到请求后,会将Pod信息写入etcd,并且返回响应给客户端 Kubernets中的组件都会采用Watch机制,Scheduler发现有新的Pod需要创建并且还没有调度到一个节点,此时Scheduler会根据Pod中的一些信息决定最终要调度到的节点,并且将该信息提交给API Server API Server在收到该bind信息后会将内容保存到etcd 每个工作节点上的Kubelet都会监听API Server的变动,发现是否还有属于自己的Pod但还未进行绑定,一旦发现,Kubelet就会在本节点上调用Docker启动容器并完成Pod一系列相关的设置,然后将结果返回给API Server API Server在收到Kubelet的返回信息后,会将信息写入etcd
Pod的Status的含义?
Pending:Pod已被Kubernetes系统接收,但有一个或多个容器尚未创建运行 Running:Pod已经绑定到某个节点,并且所有容器已被创建,且至少有一个容器正在运行,或者处于启动或重启状态 Succeed:Pod中所有容器都成功终止,并且不会再重启 Failed:Pod中所有容器都已终止,并且至少有一个容器是因为失败而终止。 Unknown:因为某些原因无法取得Pod的状态,比如和Pod所在的节点通信失败。
apiVersion: v1kind: Podmetadata: name: status-change-watchspec: restartPolicy: Never containers: - name: readiness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 20; rm -rf /tmp/healthy - name: readiness-1 image: busybox args: - /bin/sh - -c - cat 111
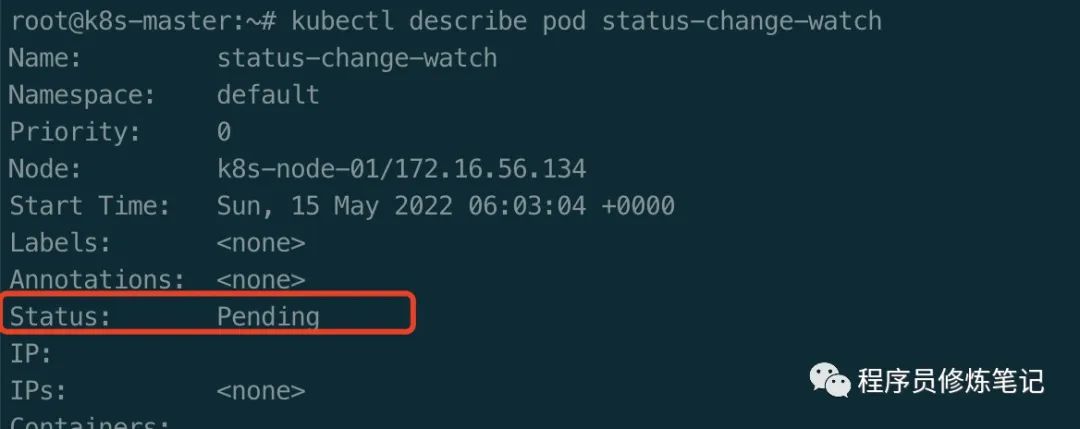
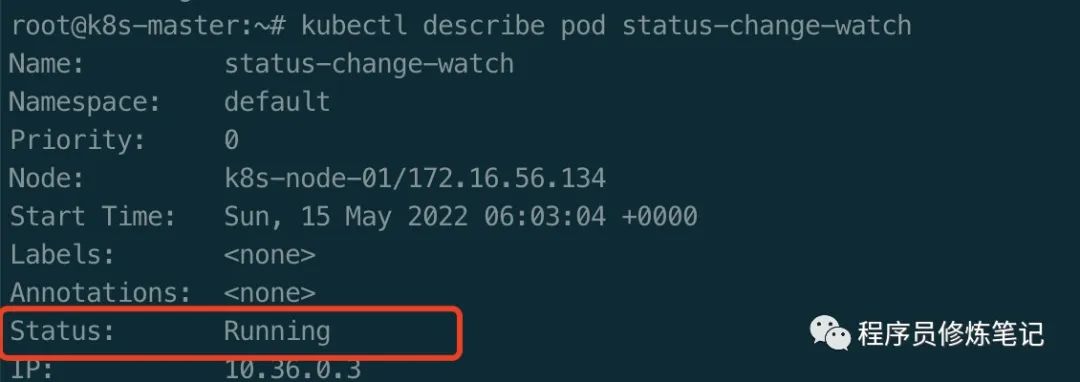
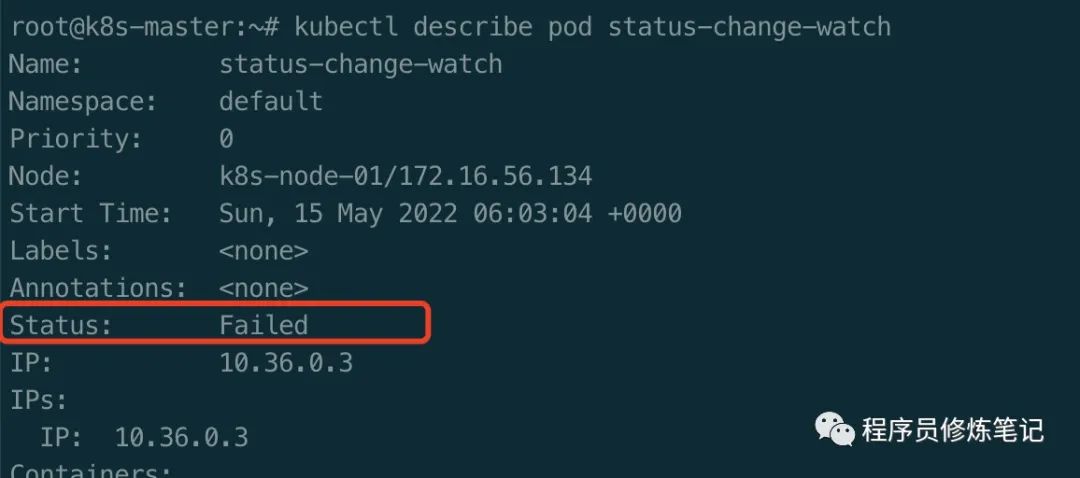
$ kubectl apply -f status-change-watch.yaml$ kubectl describe pod status-change-watch
我们通过上述命令,不断地观察Pod的状态,会发现Pod的Status会从Pendingb变为Running,变为Failed。
Pod调度
节点选择器
apiVersion: v1kind: Podmetadata: name: node-seletorspec: # 节点选择器 nodeSelector: node_env: test restartPolicy: Never containers: - name: readiness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 10; rm -rf /tmp/healthy
节点选择器可以方便的将某个Pod和固定的Node进行绑定,由字段spec.nodeSeletor定义,上述YAML中的含义是,Pod在被调度时会被调度到节点上有node_env标签,且标签值为test的Node上。
$ kubectl apply -f node-seletor.yaml$ kubectl describe pod node-seletor

可以看到,由于我们现在没有节点有node_env: test标签,所以调度失败了。
为节点打标签$ kubectl label nodes k8s-node-01 node_env=test$ kubectl get nodes --show-labels$ kubectl describe pod node-seletor

当我们为k8s-node-01节点打上node_env=test以后就发现我们node-seletor成功被调度到了该节点上。
节点亲和性
节点亲和性类似于节点选择器,只不过节点亲和性相比节点选择器具有更强的逻辑控制能力。节点亲和性字段由spec.affinity.nodeAffinity定义,主要有两种类型:
requiredDuringSchedulingIgnoredDuringExecution:调度器只有在节点满足该规则的时候可以将Pod调度到该节点上 preferredDuringSchedulingIgnoredDuringExecution:调度器会首先找满足该条件的节点,如果找不到合适的再忽略该条件进行调度
apiVersion: v1kind: Podmetadata: name: node-affinityspec: affinity: # 节点亲和性 nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: node_env operator: In values: - "test" preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: "cloud-provider" operator: In values: - "ali" restartPolicy: Never containers: - name: readiness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 10; rm -rf /tmp/healthy
上述亲和性规则如下:
节点必须包含node_env标签,且值是test 节点最好具有cloud-provider标签,且值是ali
目前operator字段主要有以下值:
In和NotIn Exists和DoesNotExist Gt和Lt
preferredDuringSchedulingIgnoredDuringExecution的weight代表了下面的条件的权重,在调度时会将节点上的权重加起来(如果满足条件的话),最终权重高的节点优先级越高,越容易被调度到。
污点(Taint)和污点容忍(Toleration)
污点作用于节点上,没有对该污点进行容忍的Pod无法被调度到该节点。
污点容忍作用于Pod上,允许但不强制Pod被调度到与之匹配的污点的节点上。
为节点打污点kubectl taint nodes k8s-node-01 key1=value1:NoSchedule
上述表示为k8s-node-01节点打上了一个污点,污点的key为key1,value为value1,效果是NoSchedule,目前效果主要有以下固定值:
NoSchedule:不允许调度 PreferNoSchedule:尽量不调度 NoExecute:如果该节点上不容忍该污点的Pod已经在运行会被驱逐,同时如果不会将不容忍该污点的Pod调度到该节点上
apiVersion: v1kind: Podmetadata: name: node-tolerationspec: tolerations: - key: "node-role.kubernetes.io/master" operator: "Equal" value: "" effect: "NoSchedule" restartPolicy: Never containers: - name: readiness image: busybox args: - /bin/sh - -c - touch /tmp/healthy; sleep 10; rm -rf /tmp/healthy
目前operator的值主要有以下两种情况:
Equal:value必须和污点的value相同 Exists:此时,Pod上的toleration不能指定value
$ kubectl apply -f node-toleration.yaml$ kubectl get pods -o wide

通过上图可以看出,我们通过污点容忍,node-toleration这个Pod成功被调度到了master节点上。
本期Kubernetes Pod详解就到这,扫码关注,更多内容我们下期再见!

